Create and manage catalogs | Databricks on AWS [2023/6/8時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
本書では、Unity Catalogにおけるカタログの作成、管理方法を説明します。カタログにはスキーマ(データベース)が含まれ、スキーマにはテーブルとビューが含まれます。
要件
- あなたがDatabricksメタストア管理者であるか、メタストアに対する
CREATE CATALOG権限を付与されていること。 - お使いのDatabricksアカウントがPremiumプラン以上であること。
- カタログ作成を行うワークスペースにUnity Catalogメタストアがリンクされていること。
- カタログを作成するためのノートブックやDatabricks SQLを実行する計算リソースは、Unity Catalog互換のアクセスモードを用いてること。
カタログの作成
カタログを作成するには、データエクスプローラかSQLコマンドを使用できます。
データエクスプローラ
-
メタストアにリンクされているワークスペースにログインします。
-
 Dataをクリックします。
Dataをクリックします。 -
Create Catalogボタンをクリックします。
-
(オプション)カタログのマネージドテーブルのデータが格納されるロケーションを指定します。
メタストアで設定されたデフォルトのルートストレージロケーションにこのカタログのマネージドテーブルを格納したくない場合にのみ、ここでロケーションを指定します。Create a Unity Catalog metastoreをご覧ください。
指定するパスは、外部ロケーション設定で定義されている必要があり、その外部ロケーションに対する
CREATE MANAGED STORAGE権限を持っている必要があります。また、そのパスのサブパスを使用することもできます。Unity Catalogにおける外部ロケーションとストレージ認証情報の管理をご覧ください。 -
Createをクリックします。
-
(オプション)カタログが紐付けられるワークスペースを指定します。
デフォルトでは、カタログは現在のメタストアにアタッチされているすべてのワークスペースで共有されます。カタログに特定のワークスペースに制限すべきデータが含まれている場合は、Workspacesタブに移動して、それらのワークスペースを追加します。
詳細は、(オプション)特定のワークスペースへのカタログの割り当てをご覧ください。
-
カタログのアクセス権を割り当てます。Unity Catalogにおける権限およびセキュリティ保護可能オブジェクトをご覧ください。
カタログを作成すると、defaultとinformation_schemaの2つのスキーマ(データベース)が自動的に作成されます。
また、Databricks Terraform providerとdatabricks_catalogを用いることでカタログを作成することができます。databricks_catalogsを用いることで、カタログに関する情報を取得することができます。
SQL
-
ノートブックかSQLエディタで以下のSQLコマンドを実行します。大括弧内のアイテムはオプションです。以下のプレースホルダーを置き換えてください:
-
<catalog-name>: カタログ名。 -
<location-path>: オプション。メタストアで設定されたデフォルトのルートストレージロケーションにこのカタログのマネージドテーブルを格納したくない場合に、ロケーションを指定します。このパスは外部ロケーション設定で定義され、この外部ロケーション設定に対するCREATE MANAGED STORAGE権限を持っっている必要があります。外部ロケーションで定義されているパスやるいはサブパス(言い換えると、's3://depts/finance'や's3://depts/finance/product')を使用することができます。Databricksランタイム11.3以降が必要です。 -
<comment>: オプションのコメント。
CREATE CATALOG [ IF NOT EXISTS ] <catalog-name> [ MANAGED LOCATION '<location-path>' ] [ COMMENT <comment> ];例えば、
exampleというカタログを作成するには:CREATE CATALOG IF NOT EXISTS example; -
-
カタログに権限を割り当てます。Unity Catalogにおける権限およびセキュリティ保護可能オブジェクトをご覧ください。
Python
spark.sql("CREATE CATALOG [ IF NOT EXISTS ] <catalog-name> [ MANAGED LOCATION '<location-path>' ] [ COMMENT <comment> ]")
spark.sql("CREATE CATALOG IF NOT EXISTS example")
R
library(SparkR)
sql("CREATE CATALOG [ IF NOT EXISTS ] <catalog-name> [ MANAGED LOCATION '<location-path>' ] [ COMMENT <comment> ]")
library(SparkR)
sql("CREATE CATALOG IF NOT EXISTS example")
Scala
spark.sql("CREATE CATALOG [ IF NOT EXISTS ] <catalog-name> [ MANAGED LOCATION '<location-path>' ] [ COMMENT <comment> ]")
spark.sql("CREATE CATALOG IF NOT EXISTS example")
(オプション)特定のワークスペースへのカタログの割り当て
ユーザーのデータアクセスを分離するためにワークスペースを使い場合、カタログへのアクセスをお使いのアカウントの特定のワークスペースに限定したいと考え、ワークスペース・カタログバインディングと呼ばれる機能を使いたいと考えるかもしれません。デフォルトでは、現在のメタストアにアタッチされたすべてのワークスペースでカタログは共有されます。
カタログを特定のワークスペースにバインディングする典型的なユースケースには以下のようなものがあります:
- プロダクションのワークスペース環境からのユーザーのみがプロダクションデータにアクセスするようにする。
- 専用ワークスペースからのユーザーのみセンシティブなデータにアクセスできるようにする。
プロダクションと開発の分離の例を取ります。お使いのプロダクションデータカタログはプロダクションワークスペースからのみアクセスできることを指定した場合、これは、ユーザーに発行されている個人の権限を上書きします。
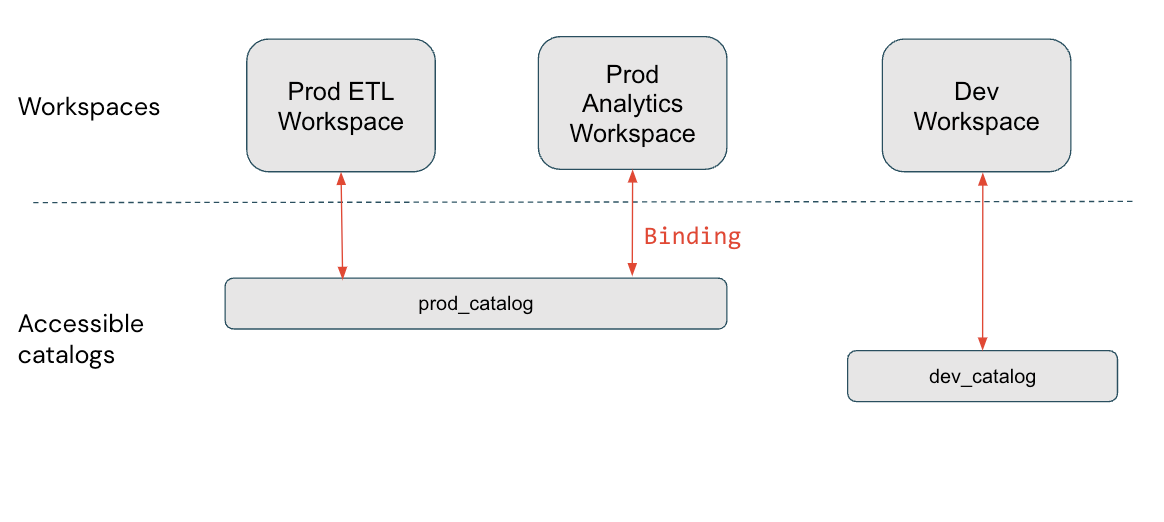
この図では、prod_catalogは2つのプロダクションワークスペースにバインディングされています。(GRANT SELECT ON my_table TO <user>を用いて)あるユーザーに、prod_catalogのmy_tableと呼ばれるテーブルへのアクセスが許可されているものとします。Devワークスペースでこのユーザーがmy_tableにアクセスしようとすると、エラーメッセージを受け取ります。このユーザーはProd ETLかProd Analyticsワークスペースからのみmy_tableにアクセスすることができます。
ワークスペース・カタログバインディングは、プラットフォームのすべての領域で考慮されます。例えば、information schemaをクエリーする際、クエリーを実行したワークスペースからアクセスできるカタログのみを参照できます。データリネージや検索UIなどは、(バインディングを使っていようがデフォルトであろうが)ワークスペースに割り当てられてるカタログのみを表示します。
設定
特定のワークスペースにカタログを割り当てるには、データエクスプローラかUnity Catalog REST APIを使用することができます。
必要な権限: メタストア管理者あるいはカタログオーナー。
注意
メタストア管理者は、カタログが現在のワークスペースに割り当てられているかどうかに関係なく、データエクスプローラを用いてメタストアのすべてのカタログを参照することができます。そして、カタログオーナーは、メタストアで所有しているすべてのカタログを参照することができます。ワークスペースに割り当てられていないカタログはグレー表示され、子供のオブジェクトを参照したりクエリーすることはできません。
データエクスプローラ
-
メタストアにリンクされているワークスペースにログインします。
-
Dataをクリックします。
-
Dataペインの左でカタログ名をクリックします。
メインのデータエクスプローラのペインはデフォルトではCatalogsリストです。そこでもカタログを選択することができます。
-
Workspacesタブで、All workspaces have accessチェックボックスをクリアします。
-
Assign to workspacesをクリックし、割り当てたいワークスペースを入力あるいは検索します。
アクセスを取り消すには、Workspacesタブでワークスペースを選択してRevokeをクリックします。
API
カタログをワークスペースに割り当てるのに必要な2つのAPIと2つのステップが存在します。以下の例では、<workspace-url>をワークスペースのインスタンス名に置き換えてください。ワークスペースインスタンス名やワークスペースIDの取得方法については、DatabricksでワークスペースID、クラスターID、ノートブックID、モデルID、ジョブIDを取得するをご覧ください。アクセストークンの取得方法については、Databricks自動化における認証処理をご覧ください。
-
カタログの
isolation modeをISOLATEDに設定するためにcatalogsAPIを使います:curl -L -X PATCH 'https://<workspace-url>/api/2.1/unity-catalog/catalogs/<my-catalog> \ -H 'Authorization: Bearer <my-token> \ -H 'Content-Type: application/json' \ --data-raw '{ "isolation_mode": "ISOLATED" }'デフォルトの
isolation modeは、メタストアにアタッチされているすべてのワークスペースに対するOPENです。 -
カタログにワークスペースを割り当てるために
workspace-bindingsAPIを使います:curl -L -X PATCH 'https://<workspace-url>/api/2.1/unity-catalog/workspace-bindings/catalogs/<my-catalog> \ -H 'Authorization: Bearer <my-token> \ -H 'Content-Type: application/json' \ --data-raw '{ "assign_workspaces": [<workspace-id>, <workspace-id2>], "unassign_workspaces": [<workspace-id>, <workspace-id2>] }'
カタログに割り当てられているすべてのワークスペースを一覧するには、workspace-bindings APIを使います:
curl -L -X PATCH 'https://<workspace-url>/api/2.1/unity-catalog/workspace-bindings/catalogs/<my-catalog> \
-H 'Authorization: Bearer <my-token> \
次のステップ
add schemas (databases) to your catalogを行うことができます。
カタログの削除
カタログを削除(ドロップ)するには、データエクスプローラかSQLコマンドを使用することができます。
データエクスプローラ
カタログを削除する前にinformation_schemaを除くカタログ内のすべてのスキーマを削除する必要があります。
- メタストアにリンクされているワークスペースにログインします。
-
Dataをクリックします。
- Dataペインの左で削除したいカタログ名をクリックします。
- 詳細ペインで、Create databaseボタンの左の3点メニューをクリックし、Deleteを選択します。
- Delete catalogダイアログでDeleteをクリックします。
SQL
以下のSQLコマンドをノートブックかSQLエディタで実行します。大括弧内のアイテムはオプションです。プレースホルダー<catalog-name>を置き換えてください。
パラメーターの説明に関しては、DROP CATALOGをご覧ください。
CASCADEオプションなしでDROP CATALOGを使う場合、カタログを削除する前にinformation_schema以外のカタログのすべてのスキーマを削除しなくてはなりません。これには、自動生成されたdefaultスキーマも含まれます。
DROP CATALOG [ IF EXISTS ] <catalog-name> [ RESTRICT | CASCADE ]
例えば、カタログvaccineとそのスキーマを削除するには:
DROP CATALOG vaccine CASCADE
Python
spark.sql("DROP CATALOG [ IF EXISTS ] <catalog-name> [ RESTRICT | CASCADE ]")
spark.sql("DROP CATALOG vaccine CASCADE")
R
library(SparkR)
sql("DROP CATALOG [ IF EXISTS ] <catalog-name> [ RESTRICT | CASCADE ]")
library(SparkR)
sql("DROP CATALOG vaccine CASCADE")
Scala
spark.sql("DROP CATALOG [ IF EXISTS ] <catalog-name> [ RESTRICT | CASCADE ]")
spark.sql("DROP CATALOG vaccine CASCADE")