ニッチなネタですが。
シナリオ
日次で特定のS3パスにファイルが到着します。
.../2023/07/24: 7/23時点の全件データ断面
.../2023/07/25: 7/24時点の全件データ断面
断面データを用いてターゲットテーブルを洗い替えたいものとします。
Delta Live Tablesとは
データパイプラインの変換処理を全て記述することなしに、パイプラインの各ステップ(テーブル)を宣言することで、Delta Live Tablesはテーブル間の処理を補完するので、シンプルなコードで複雑なパイプラインを構築することができます。SQLとPythonをサポートしているので、得意な言語でデータパイプラインを構築できます。また、イベントログ、エラー時のリトライ、自動テスト、オートスケーリングなどがサポートされています。処理の背後ではSparkの構造化ストリーミングやDelta Lakeを活用しています。
方針
- 日次でフォルダが作成されていくので、自動で未処理のファイルのみを取り込みたい。
- ターゲットテーブルに追記するのではなく、一旦レコードをDELETEしてINSERTしたい。
実は、2つ目が結構苦戦しました。Delta Live Tablesは基本追記処理となります(DELETE込みのUPSERTもあります)。
追記ではなく、洗い替えをする手段としてフルリフレッシュという機能があります。これはこれで便利なのですが、データソース自体もリフレッシュされてしまうので、結局のところ前日のファイルも読み込まれてしまう訳でして。
案1: 日毎のフォルダを特定してパイプラインをアップデート
CREATE
OR REFRESH STREAMING LIVE TABLE customer_bronze
COMMENT "ブロンズレイヤ:データファイルをすべてString型でロードする"
AS
SELECT
*
FROM
cloud_files(
-- ディレクトリをパラメータ化
"dbfs:/tmp/DLT_Example/customer_${mypipeline.startDate}",
"csv",
map(
"delimiter",
",",
"header",
"true",
"cloudFiles.schemaLocation",
"dbfs:/tmp/DLT_Example/customer/schema_spend"
)
);
これはこれで動くのですが、毎回パラメータに日付を指定しなくてはなりません。
案2: Auto Loaderを使いつつもパイプラインアップデート前にテーブルをリセットする
結局こちらで行きました。ただ、注意点があります。デフォルトでは、Delta Live Tablesはパイプラインがアップデートされるたびに入力データに基づいてテーブルの結果を再計算するので、ソースデータから削除されたレコードが再ロードされないように抑制する必要があります。
DLTパイプラインの作成
Delta Live Tablesを用いることで、テーブルから手動でレコードを削除、更新することができ、後段のテーブルの再計算を行うためにリフレッシュすることができます。
デフォルトでは、Delta Live Tablesはパイプラインがアップデートされるたびに入力データに基づいてテーブルの結果を再計算するので、ソースデータから削除されたレコードが再ロードされないようにする必要があります。テーブルプロパティ
pipelines.reset.allowedをfalseに設定することで、テーブルのリフレッシュを防ぎつつも、テーブルに対するインクリメンタルな書き込みやテーブルへの新規データの流入は妨げません。
CREATE
OR REFRESH STREAMING TABLE complete_bronze TBLPROPERTIES (
'delta.minReaderVersion' = '2',
'delta.minWriterVersion' = '5',
'delta.columnMapping.mode' = 'name',
'pipelines.reset.allowed' = 'false'
) COMMENT "Parquetをそのまま保持するブロンズテーブル" AS
SELECT
*,
current_timestamp() as processed -- 処理時刻
FROM
cloud_files(
"/tmp/takaaki.yayoi@databricks.com/dlt/landing/",
"parquet"
)
CREATE
OR REFRESH LIVE TABLE complete_silver COMMENT "取り込まれたデータで洗い替えされるテーブル" AS
SELECT
*
FROM
live.complete_bronze;
このノートブックを用いてDLTパイプラインを作成します。ここではテーブルの配信先としてUnity Catalogのカタログtakaakiyayoi_catalog、スキーマdltを設定しています。
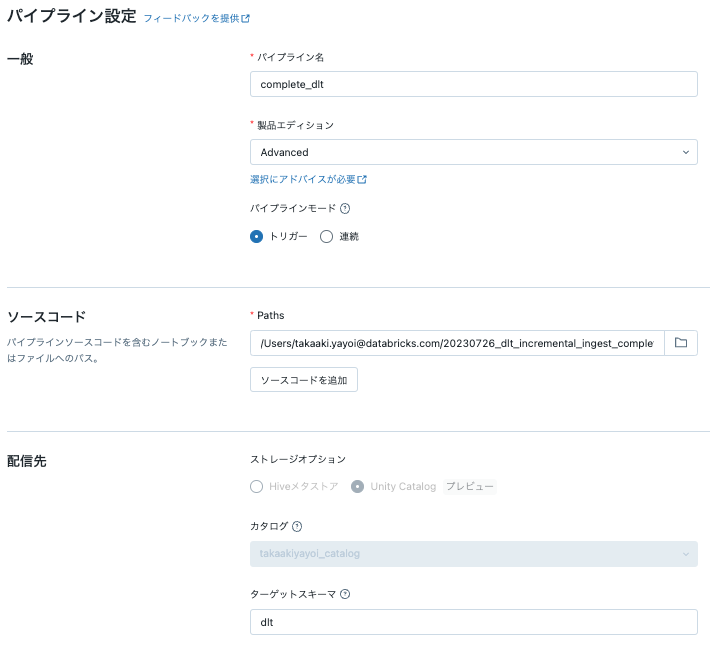
これでcomplete_bronzeのリフレッシュ後の再ロードが抑制されるようになり、テーブルのレコード削除操作が維持されるようにます。
テーブル削除処理の実装
あとは別途削除処理を実装します。別途Databricks SQLのクエリーとしてtable_resetを作成します。サイドメニューからクエリーにアクセスし、以下のクエリーを記述します。カタログ名とスキーマ名はDelta Live Tablesの定義と揃えてください。
DELETE FROM takaakiyayoi_catalog.dlt.complete_bronze;
DELETE FROM takaakiyayoi_catalog.dlt.complete_silver;
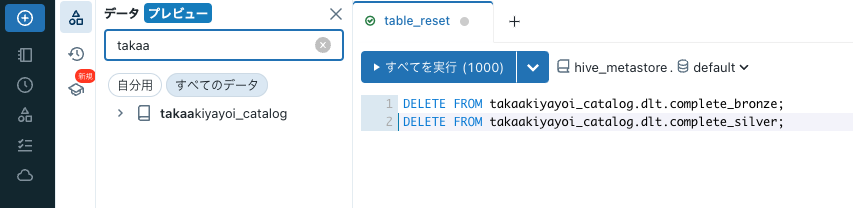
こちらもクエリーを実行して動作確認します。
ジョブを構築
最後に、クエリーとDLTパイプラインをジョブとしてまとめます。サイドメニューのワークフローにアクセスしてジョブを作成をクリックします。
- ジョブ名、タスク名を入力し、種類はSQL、SQLタスクはクエリー、SQLクエリーにはテーブル削除処理の実装で作成したクエリーを選択します。SQLウェアハウスを選択してタスクを作成をクリックします。

- 一つ目のタスクが選択されている状態で、タスクを追加をクリックします。
- タスク名を入力し、種類はDelta Live Tablesパイプラインを選択し、パイプラインでDLTパイプラインの作成で作成したパイプランを選択します。Delta Live Tablesパイプラインで完全なリフレッシュをトリガーするにチェックが入っていることを確認してください。

動作確認
1日目
データを準備します。ノートブックで以下を実行します。
data_path = "/tmp/takaaki.yayoi@databricks.com/dlt/landing"
dbutils.fs.rm(data_path, True)
data_07_06 = [{"Date": "2023/07/06", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Date": "2023/07/06", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Date": "2023/07/06", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Date": "2023/07/06", "Category": 'D', "ID": 4, "Value": 33.87, "Truth": True}
]
df_07_06 = spark.createDataFrame(data_07_06)
display(df_07_06)
data_07_07 = [{"Date": "2023/07/07", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Date": "2023/07/07", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
#{"Date": "2023/07/07", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Date": "2023/07/07", "Category": 'D', "ID": 4, "Value": 33.87, "Truth": True}
]
df_07_07 = spark.createDataFrame(data_07_07)
display(df_07_07)
data_07_08 = [#{"Date": "2023/07/08", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
#{"Date": "2023/07/08", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Date": "2023/07/08", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": True},
{"Date": "2023/07/08", "Category": 'E', "ID": 5, "Value": 33.87, "Truth": True}
]
df_07_08 = spark.createDataFrame(data_07_08)
display(df_07_08)
最初のデータを保存します。
save_path = f"{data_path}/2023/07/06/"
df_07_06.write.format("parquet").option("header", "true").mode("overwrite").save(save_path)
Delta Live Tablesのパイプラインを開始してテーブルを作成します。動作確認も兼ねています。
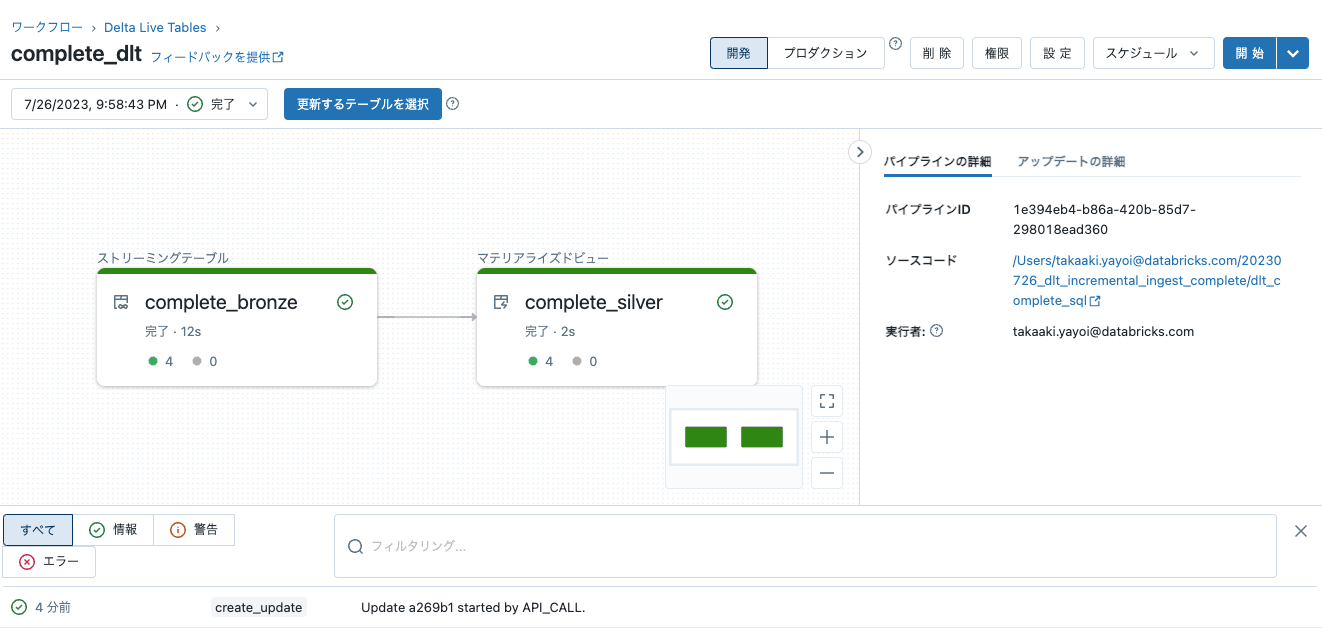
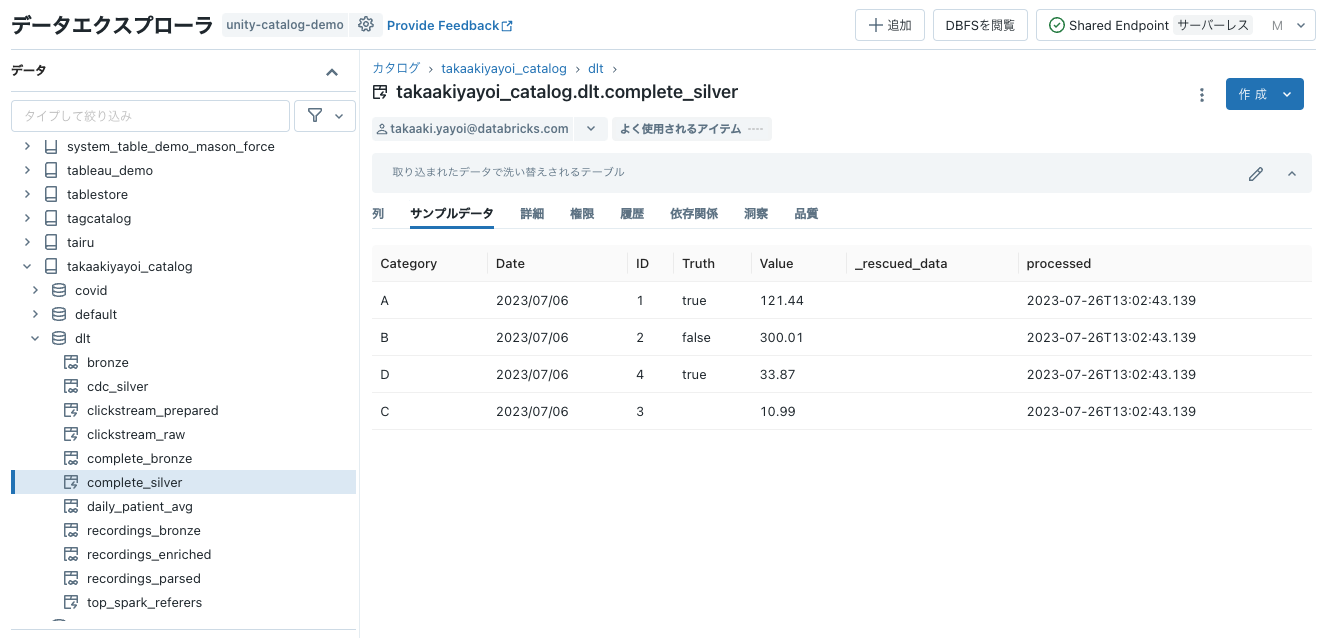
処理が完了したらテーブルを確認します。7/6のデータのみが反映されています。
2日目
ノートブックで2日目のデータを保存します。
save_path = f"{data_path}/2023/07/07/"
df_07_07.write.format("parquet").option("header", "true").mode("overwrite").save(save_path)
2回目以降はテーブルのリセットが必要になるので、ジョブの画面に移動して、今すぐ実行をクリックします。
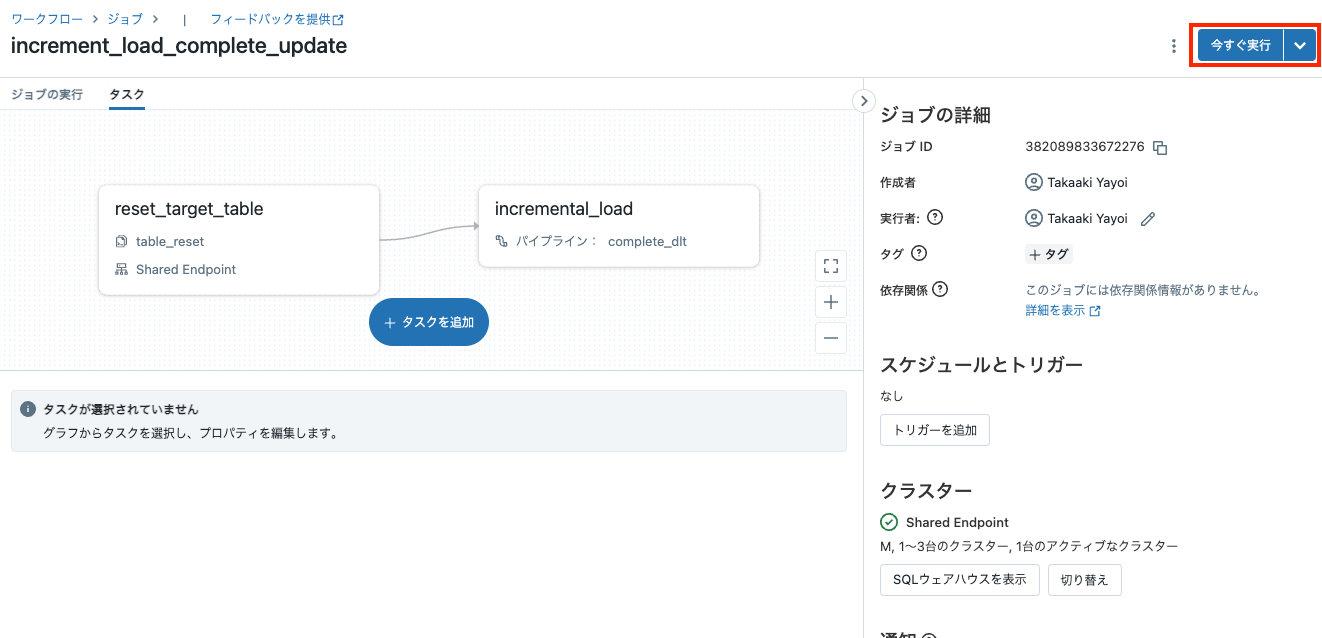
7/7のデータに洗い替えされます。
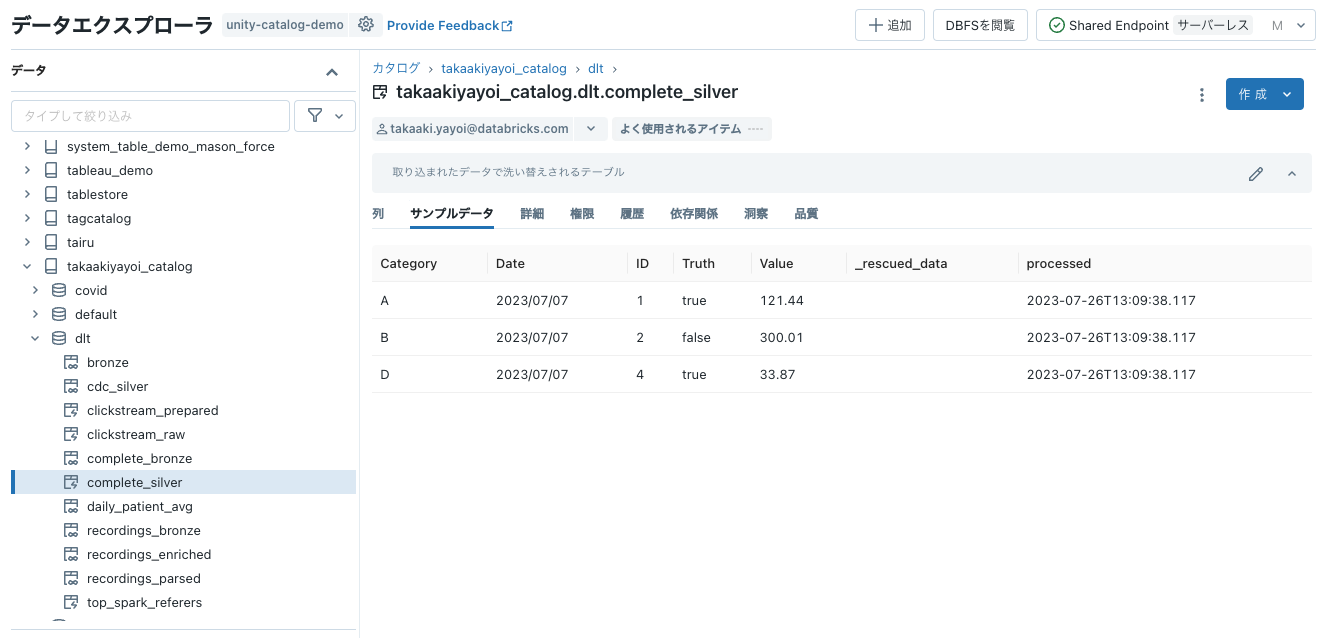
3日目
ノートブックで3日目のデータを保存します。
save_path = f"{data_path}/2023/07/08/"
df_07_08.write.format("parquet").option("header", "true").mode("overwrite").save(save_path)
ジョブの画面に移動して、今すぐ実行をクリックします。
7/8のデータに洗い替えされます。
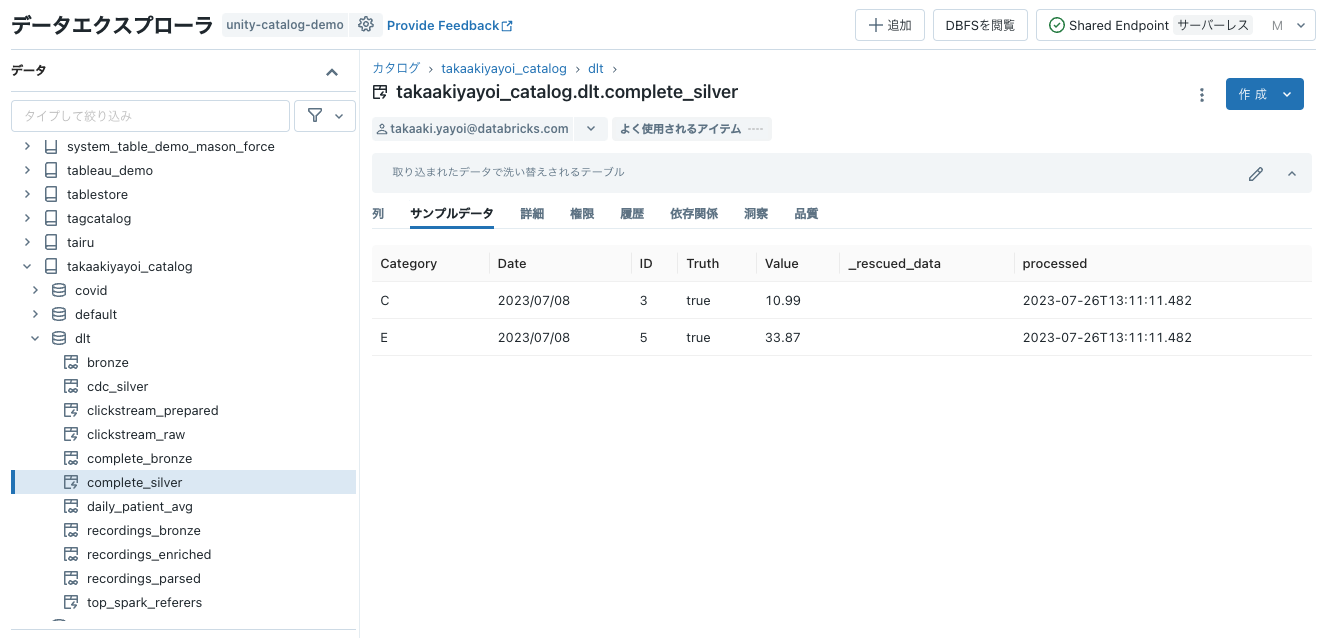
あとは、上のジョブを日次実行するようにスケジュールすれば、毎日更新ファイルを取り込んでテーブルを洗い替えるようになります。