こちらのチュートリアルをウォークスルーします。
データ分析を行う際には、当たり前ですが何かしらのデータが必要となります。このチュートリアルでは、JSONファイルをDeltaテーブルに取り込んで分析できるようにするまでの流れをウォークスルーしています。
ステップ 1: クラスターを作成する
こちらの手順に従ってクラスター(計算資源)を作成、起動します。
ステップ 2: Databricks ノートブックを作成する
Databricksでロジックを記述するインタフェースはノートブックです。こちらの手順に従ってノートブックを作成します。
手順 3: Unity Catalogによって管理される外部ロケーションからデータの書き込みと読み取りを行う
外部ロケーションとは、Databricksからお客様が使用しているS3やADLSを参照できるようにする仕組みです。
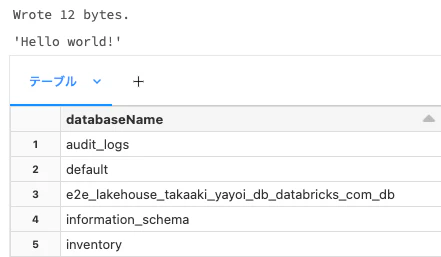
以下のコードでは、単に外部ロケーションにファイルを読み書きしているのと、カタログに含まれるデータベース(スキーマ)を一覧しているだけです。
# 外部ロケーションのパス
external_location = "s3://taka-external-location-bucket/"
# Unity Catalogのカタログ
catalog = "main"
dbutils.fs.put(f"{external_location}/filename.txt", "Hello world!", True)
display(dbutils.fs.head(f"{external_location}/filename.txt"))
dbutils.fs.rm(f"{external_location}/filename.txt")
display(spark.sql(f"SHOW SCHEMAS IN {catalog}"))
以下のコードでは、データを格納するデータベース(スキーマ)、テーブルを宣言し、データロードを行うクラスを定義しています。spark.table("samples.nyctaxi.trips")とあるように、Databricks環境に最初から格納されているサンプルデータ(NYのタクシー乗降記録)を読み込んでJSONを外部ロケーションに出力しています。実際のシナリオでは、外部システムなどから特定のオブジェクトストレージパスにファイルが到着するのが多いかと思います。
from pyspark.sql.functions import col
# ワークスペースで環境を分離するためのパラメータを設定し、デモをリセット
username = spark.sql("SELECT regexp_replace(current_user(), '[^a-zA-Z0-9]', '_')").first()[0]
database = f"{catalog}.e2e_lakehouse_{username}_db"
source = f"{external_location}/e2e-lakehouse-source"
table = f"{database}.target_table"
checkpoint_path = f"{external_location}/_checkpoint/e2e-lakehouse-demo"
spark.sql(f"SET c.username='{username}'")
spark.sql(f"SET c.database={database}")
spark.sql(f"SET c.source='{source}'")
spark.sql("DROP DATABASE IF EXISTS ${c.database} CASCADE")
spark.sql("CREATE DATABASE ${c.database}")
spark.sql("USE ${c.database}")
# 前回のデモ実行のデータをクリア
dbutils.fs.rm(source, True)
dbutils.fs.rm(checkpoint_path, True)
# データのバッチをソースにロードするクラスの定義
class LoadData:
def __init__(self, source):
self.source = source
def get_date(self):
try:
df = spark.read.format("json").load(source)
except:
return "2016-01-01"
batch_date = df.selectExpr("max(distinct(date(tpep_pickup_datetime))) + 1 day").first()[0]
if batch_date.month == 3:
raise Exception("Source data exhausted")
return batch_date
def get_batch(self, batch_date):
return (
spark.table("samples.nyctaxi.trips")
.filter(col("tpep_pickup_datetime").cast("date") == batch_date)
)
def write_batch(self, batch):
batch.write.format("json").mode("append").save(self.source)
def land_batch(self):
batch_date = self.get_date()
batch = self.get_batch(batch_date)
self.write_batch(batch)
RawData = LoadData(source)
これだけではJSONは出力されません。以下のコマンドを実行するごとに外部ロケーションにJOSNファイルが出力されます。
RawData.land_batch()
ステップ 4: Unity Catalogにデータを取り込むように Auto Loaderを構成する
そして、定期的あるいは断続的に到着するファイルを読み込んでテーブルとして活用できるようにしたいと言うのもよくあるユースケースと言えます。しかし、到着するファイルを毎回最初から処理するのは非効率的ですし、コストもかかります。このように、新規に到着したファイルのみを勝利したいと言うケースで役に立つのがAuto Loaderです。名前の通り、自動でデータをロードするのですが、賢いのは処理済みのファイルを無視すると言う点です。このため、Auto Loaderが動作するたびに未処理のファイルのみを処理するので、コスト効率良くデータの処理を行うことができます。
以下のコードのcloudFilesという部分でAuto Loaderを設定しています。読み込むファイルのフォーマットやパスを指定しています。そして、読み込んだデータをtoTableでDeltaテーブルに格納しています。readStreamやwriteStreamはストリーミング処理を行っていることを意味しています。これによって、差分のデータのみを効率的に処理するデータパイプラインを構築することができます。ストリーミング処理の詳細についてはこちらを参照ください。
# 関数のインポート
from pyspark.sql.functions import col, current_timestamp
# JSONデータをDeltaテーブルに取り込むようにAuto Loaderを設定
(spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", checkpoint_path)
.load(RawData.source)
.select("*", col("_metadata.file_path").alias("source_file"), current_timestamp().alias("processing_time"))
.writeStream
.option("checkpointLocation", checkpoint_path)
.trigger(availableNow=True)
.option("mergeSchema", "true")
.toTable(table))
ステップ 5: データの処理と操作
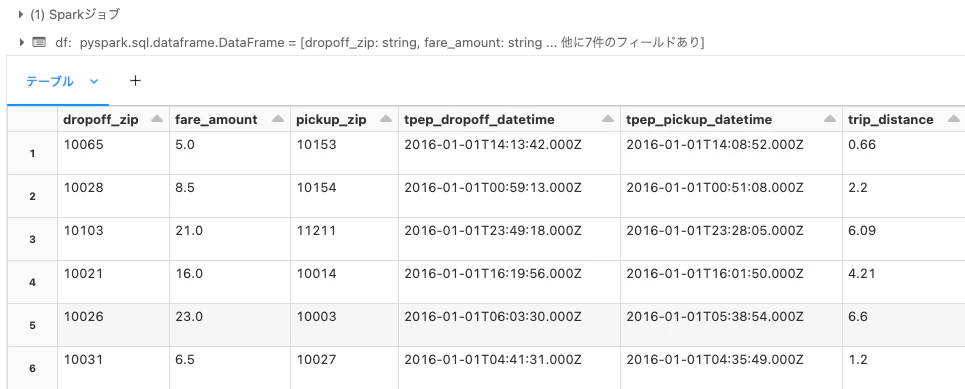
これでJSONから取り込まれたデータにはテーブル経由でアクセスできるようになりました。以下のように、テーブルの中身を確認したり、任意の集計作業などを行うことができます。
df = spark.read.table(table)
display(df)
ステップ 6: ジョブをスケジュールする
上述したようなデータ取り込み処理を定期的やファイルの到着をトリガーとして実行することができます。
ステップ 7: Databricks SQLでテーブルを検索する
SQLを用いたBIダッシュボードの構築にはDatabricks SQLが便利です。もちろん、既存のBIツールなどからテーブルを操作することもできます。