Modular Orchestration with Databricks Workflows | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
モジュール化したジョブによる複雑なワークフローの簡素化
数千のDatabricksのお客様は、Databricksレイクハウスプラットフォームでビジネス上重要なワークロードをオーケストレートするために、Databricksワークフローを日々活用しています。多くのケースにおいては、お客様のユースケースの多くで複雑な依存関係を持つ膨大な数のタスクを伴うDAG(有効非巡回グラフ)を含む重要なワークフローの定義が必要となります。想像できるように、複雑なワークフローの定義、テスト、管理、トラブルシュートは信じられないほどに困難で時間を浪費するものです。
複雑なワークフローのブレークダウン
複雑なワークフローを簡素化する一つの方法は、モジュール化のアプローチを取ることです。これには、大規模なDAGを個別に定義、管理される論理的な塊、あるいは小規模な子供のジョブにブレークダウンすることを伴います。これらの子どものジョブは親のジョブから呼び出され、全体的なワークフローはよりシンプルに理解、維持できるようになります。
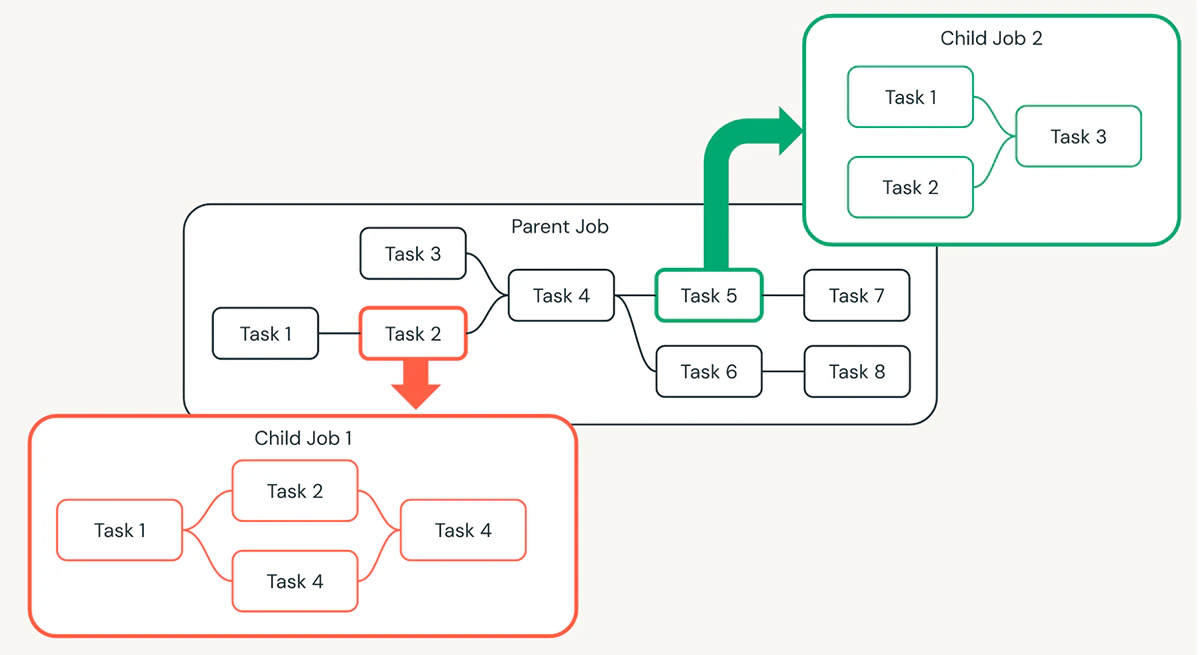
上では親ジョブには8つのタスクが含まれ、そのうち2つが子供ジョブを呼び出しています
なぜワークフローをモジュール化するのか?
親のジョブを小規模な塊に分割すべきかどうかに関する意思決定は、多くの理由からなされることがあります。これまでに我々がお客様からよく聞いた理由は、組織境界によってDAGを分割する必要性があるということです。これは、組織の様々なチームがワークフローの異なる場所で連携できるようになることを意味します。このようにして、様々なチームにおいて、自分が所有する異なるコードリポジトリを用いて、ワークフローの一部のオーナーシップをより適切に管理できるようになります。異なるチームにおける子ジョブのオーナーシップをテストや更新に拡張することができ、親のワークフローをより信頼できるものにします。
モジュール化を検討するもう一つの理由は再利用性です。複数のワークフローに共通のステップが存在する場合、あるジョブでそれらのステップを定義し、異なる親のワークフローにある子ジョブで再利用することには合理性があると言えます。パラメーターを用いることで、異なる親のワークフローの要件にフィットするように、再利用されるタスクをより柔軟にすることができます。ジョブの再利用によってワークフローの管理負荷を削減し、一つの場所で更新とバグ修正が行われるようにし、複雑なワークフローをシンプルにします。近い将来、ワークフローにさらなる制御フロー能力を追加する予定であり、お客様にとって有用な別なシナリオは、子ジョブをループし、繰り返しごとに異なるパラメーターを引き渡すというものです(ループ処理は高度なコントロールフロー機能であり、まもなくアップデートがあります。楽しみにしていてください!)。
モジュール化したワークフローの実装
最近のData + AIサミットで発表されたいくつかの新機能の一部として、Run Jobと呼ばれる新たなタスクタイプを作成する機能が発表されました。これによって、ワークフローのユーザーは以前定義されたジョブをタスクとして呼び出し、これによってモジュール化されたワークフローを作成できるようになります。
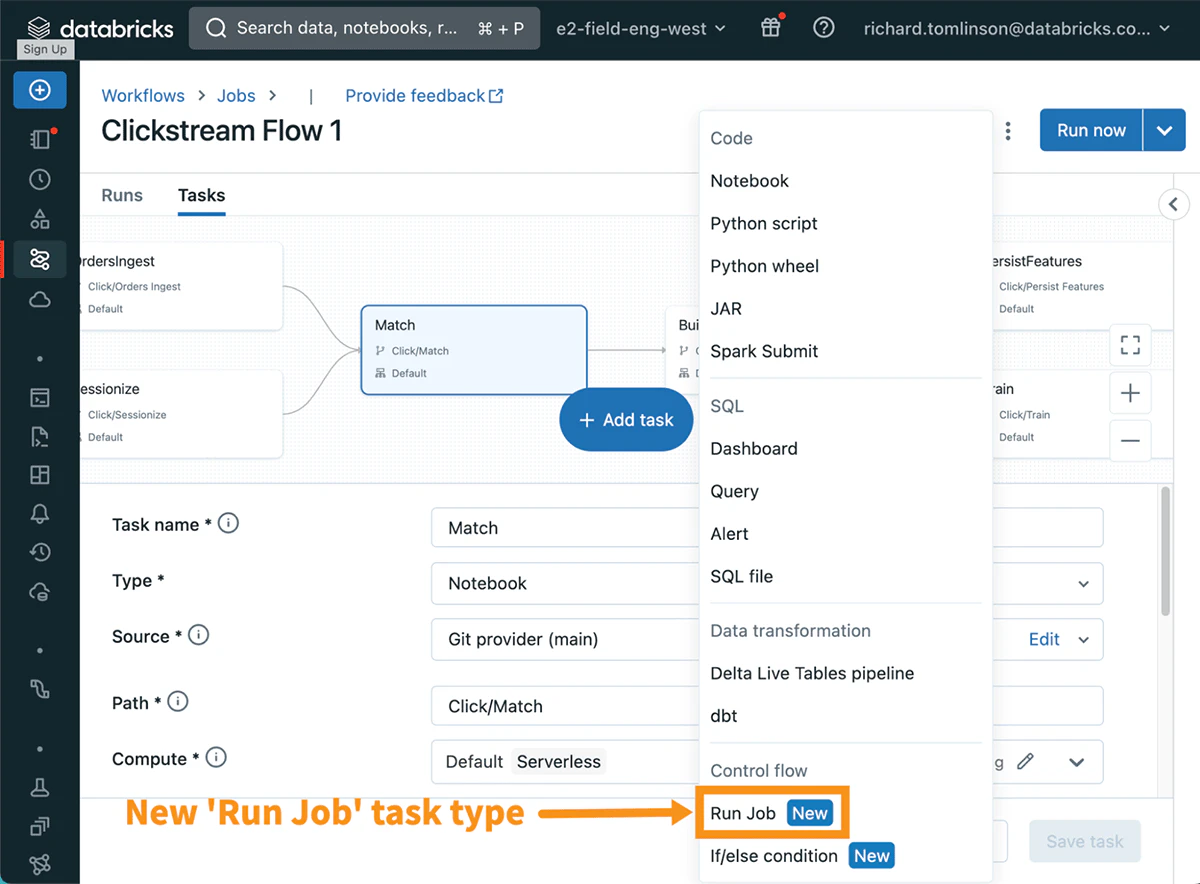
ワークフローで新規タスクを作成する際に、ドロップダウンメニューからこの新たなタスクタイプを利用できます。
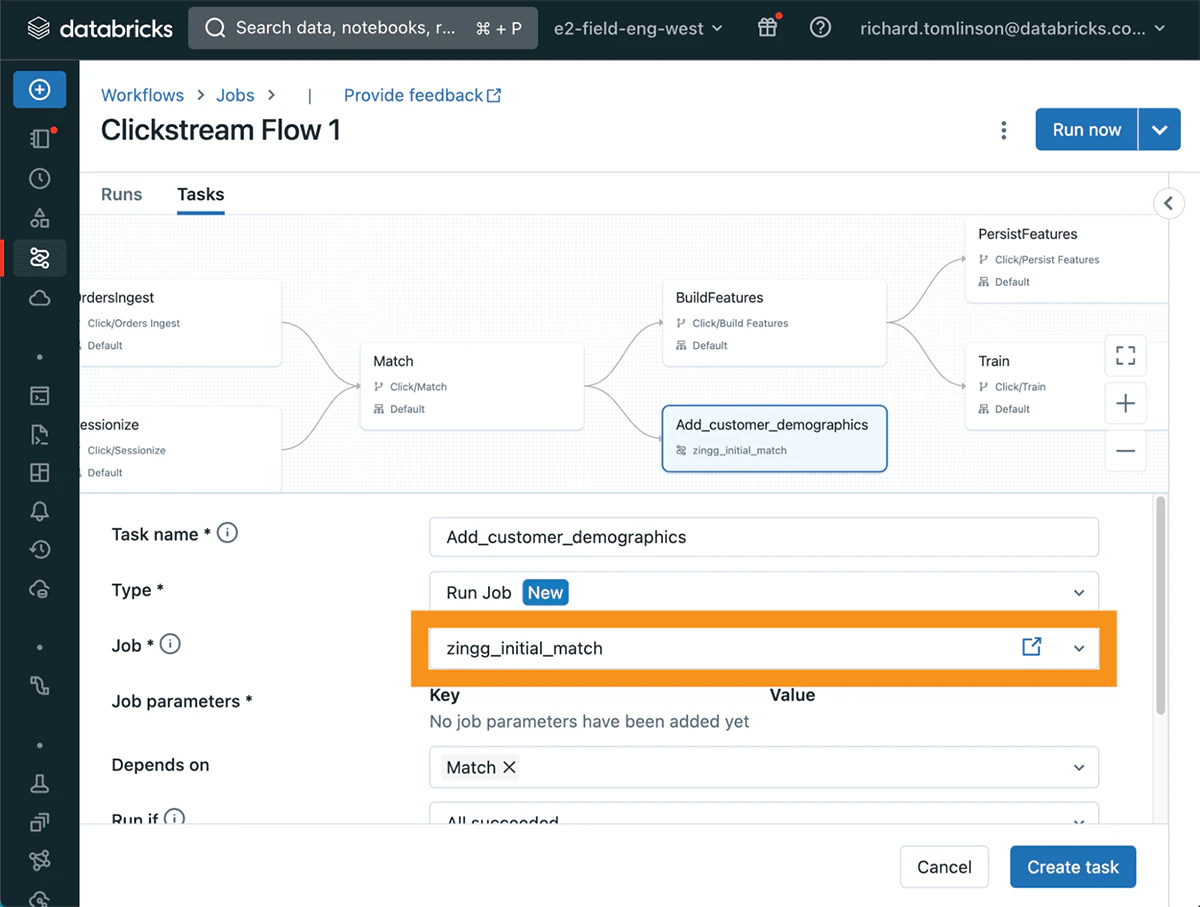
ワークフローで新規タスクを作成する際に、ドロップダウンメニューからこの新たなタスクタイプを利用できます。
様々なタスクタイプの詳細や、DatabricksワークフローのUIでの設定方法については、製品ドキュメントを参照ください。
使い始める
新たなタスクタイプRun Jobは、Databricksワークフローで正式提供されています。ワークフローで使い始めるには:
- Databricksワークフローの詳細を学ぶ
- Databricksワークフローのツアー
- クイックスタートガイドで最初のワークフローを定義して実行する