How Corning Built End-to-end ML on Databricks Lakehouse Platform - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
このブログ記事はCorningのPrincipal Software EngineerであるDenis Kamotskyによるものです。
Corningは、約200年を通じてマテリアルサイエンスにおいて世界をリードするイノベーターの一つであり続けています。彼らのイノベーションには、世界初のトーマスエジソンの電球のガラスバルブ、世界初の低損失光ファイバー、触媒コンバーターを実現する細胞基質、世界初のモバイルデバイス向け耐ダメージカバーガラスが含まれます。Corningでは境界を拡大し続けており、より良い製品や効率を改善するために機械学習(ML)のような破壊的テクノロジーを活用しています。
機械学習による製造プロセスの効率改善
高品質の製品をデリバリーすることは、世界中にある製造施設においてキーとなる目的となっており、このゴールに到達するために、どのようにMLを活用できるのかを探索し続けています。これは、例えば個人用、商用の車の両方のエアフィルターや触媒コンバーターで使用されるCorningセラミックスを生成するプラントにおいても真実となります。これらのフィルターの製造ステップの大部分はロボット化されていますが、一部はマニュアルのままです。特に品質チェックにおいては、漏れや不良パーツの予兆となり得るセルにおける異常を検知するために高解像度の画像を取得します。しかし、ここでの課題は製造環境におけるデブリが画像に映ってしまうことで生じる偽陽性の対策です。
これに対応するために、我々は撮影の前に手動でフィルターをブラッシング、ブローしています。オペレーターに掃除するパーツがどれかを伝えることで、プロセスに要する合計時間を劇的に削減することができ、機械学習が役立つことに気づきました。オペレーターが撮影機材にフィルターを設置している間に撮影した低解像度の画像に基づいて、フィルターが綺麗かそうでないかを予測するためにMLを活用しました。予測に基づいて、オペレーターはパーツを掃除すべきかどうかのシグナルを受け取りますので、最終的な高解像度の画像における偽陽性を削減し、プロダクションプロセスを高速にし、高品質のフィルターを提供できるようになりました。
このMLモデルを実行するためには、低解像度の画像に対する2値分類器が必要でした。ここで鍵となるのは、工場のフロアにいる人間のオペレーターとやりとりしており、処理に時間がかかることでフラストレーションを感じたり作業が遅延してしまうので、低レーテンシーのモデルである必要があったということでした。我々のモデルを設計する際に、処理は数ミリ秒で実行されなくてはならないことを知りました。
こちらが我々が行ったことのブレークダウンです
データチーム
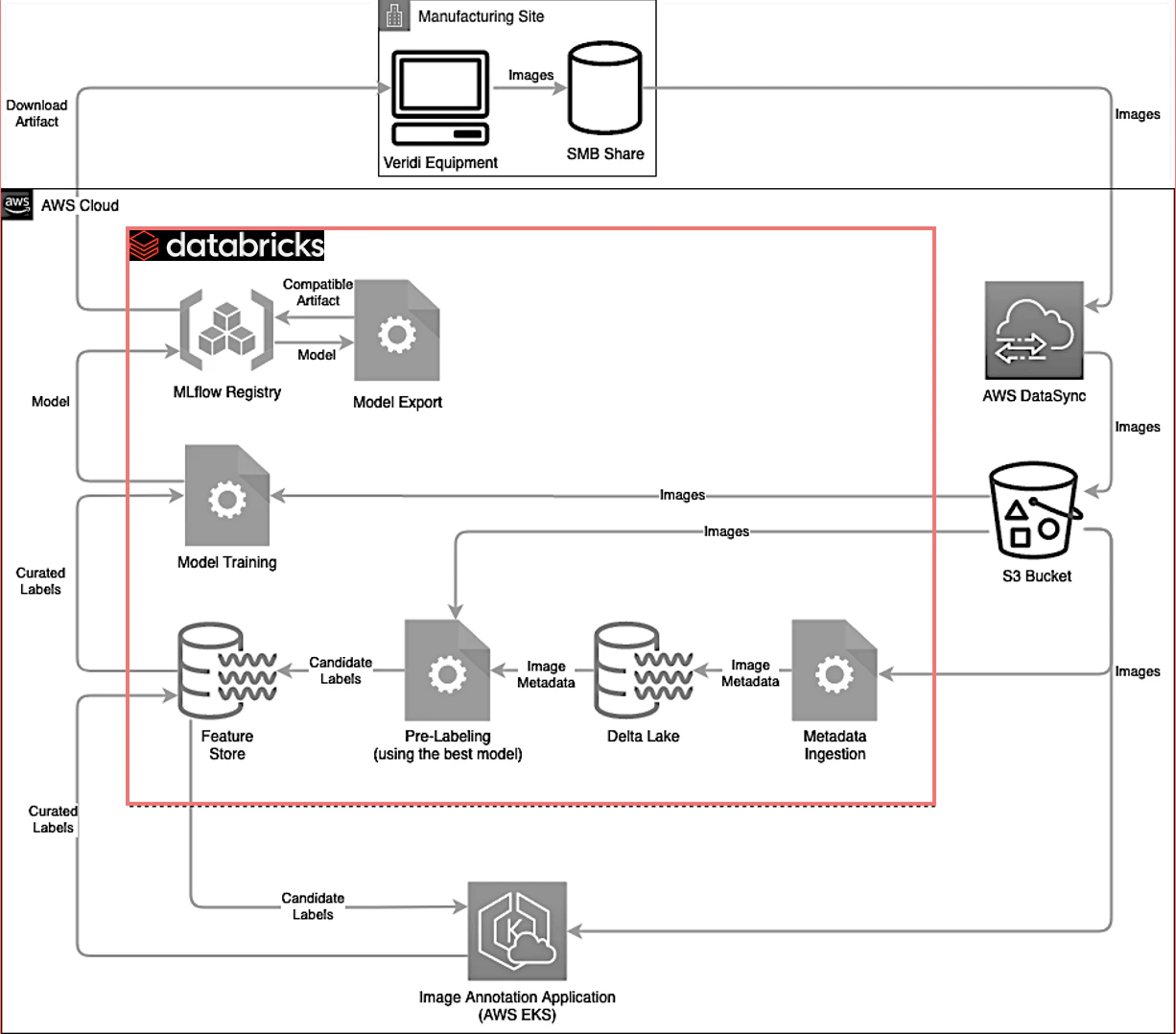
我々は、ディープラーニングアプローチを用いて低レーテンシーモデルを構築するためにDatabricksを活用する機能横断チームを蘇生するところからスタートしました。データサイエンティストが実験を行い、スクラッチからモデルを構築できるようにするために、最初に活用できる数千の画像を集めました。これらすべてのデータを加工し、ラベル付けを行えるようにフロントエンドのアプリケーションをデプロイし、データパイプラインを構築し、大規模にモデルをトレーニングしました。そして最後に、モデルがトレーニングされたら、世界中のCorningの環境テクノロジープラントすべてのエッジにデプロイする必要がありました。
モデルの構築
Databricksは、我々のすべてのデータやMLの作業を集中化できるシンプルかつ統合されたプラットフォームを提供しており、我々の戦略とトランスフォーメーションの中心となりました。我々がモデルをトレーニングしてMLflowに登録し、エクポートされたフォーマットのようなすべての追加アーティファクトを生成し、ベースモデルとして同じ場所でこれらを追跡することができます。さらに、製造施設のWindows共有から画像を収集するためにAWSのdata syncを活用し、これらはプロジェクトごとのS3バケットに到着することになります。画像に多くの前処理が必要な場合には、画像の変換や変換処理の適用を行い、Deltaテーブル自身のバイナリーカラムとして変換した画像を格納します。レイクハウスを活用するということは、S3にファイルが格納されていようが、Deltaテーブルのカラムに格納されていようが、コードからは同じように見えるということを意味します。このため、このデータにアクセスするためのプログラミングモデルはフォーマットに関係なく同じものとなります。
次に、jobs APIを用いてDatabricksジョブとしてモデルのトレーニングをキックします。トレーニングによってHDF5ファイルとして格納されるモデルを生成します。このモデルはMLflowによって追跡され、最新バージョンとしてMLflowレジストリに登録されます。次のステップは、モデルの評価の実行と、これまでのモデルのベストなメトリクスと比較することとなります。そして、これらのモデルはベストなバージョンを追跡し続けられるようにMLflowでタグ付けされます。
モデルのデプロイ
上述のステップを踏むことで、我々のエキスパートはMLflowのユーザーインタフェースにログインし、ベストモデルを生成するためのトレーニングジョブによって生成されたすべてのアーティファクトを検証します。この評価を実行したら、エキスパートは最も性能の良いモデルをプロダクションに移行し、エッジシステムはMLflowレジストリからMLflow APIを用いてモデルをダウンロードできるようになります。このループは、ドリフト検知の監視でも再利用できるので素晴らしいものです。
最終的にデプロイされた我々のモデルは200,000ものパラメーターを持っており、90%以上の精度を達成しています。
エンドツーエンドMLのためのDatabricks
DatabricksはPython指向のデータサイエンティストやディープラーニングエンジニアにとって素晴らしい開発環境であり、エンドツーエンドのMLのコラボレーションを実現します。Scikit-learn、TensorFlow、PyTorchを含む全体的なPythonエコシステムがプレインストールされた環境です。クラスターの配備は非常にクイックに行うことができ、素晴らしいノートブック環境があります。チームがノートブックでコラボレーションするのが簡単なだけではなく、MLflowエクスペリメントでも簡単にコラボレーションすることができます。
過小評価すべきではないDatabricksの別のメリットは、個々のデータサイエンティストに個人用の計算環境を提供するというものです。データサイエンティストは自分でクラスターノード数を指定することができます。そして、クラスターの分散能力はオープンソースプログラミングエンジンであるSparkによって管理されており、柔軟性やJava、Scala以上の選択肢を提供します。これらの並列計算能力の全ては非常にパワフルなものであり、あなたのワークロードを複数ノードに並列化することで高いスループットを実現することができます。Databricksにオンボードすると、Databricksは数多くのサンプルやノートブックを用いたDatabricksアカデミーのディープダイブ用のクラスを提供します。
ビジネスインパクト
Databricksレイクハウスプラットフォームで機械学習を活用することで、我々のビジネスは初年で製造業を動揺させるようなイベントを削減することで、200万ドルのコスト削減を達成しました。これは、Corning環境テクノロジーのすべての製造設備にデプロイされています。また、我々のプロジェクトの成功によって、業界の2022年のAI、機械学習における製造業リーダーシップカウンシルアワードを得ることができ、非常に誇らしく思っています。
AWS re: Inventのセッションで詳細な動画を参照することができます: AWS re:Invent 2022 - How Corning built E2E ML on a data lakehouse platform with Databricks (PRT321)