How to work with files on Databricks | Databricks on AWS [2023/1/25時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
DBFS、クラスターのローカルドライバーノード、クラウドオブジェクトストレージ、外部ロケーション、Databricks Reposのファイルを操作することができます。他のシステムをインテグレーションすることができますが、これらの多くはDatabricksに対して直接のファイルアクセスを提供しません。
本書では、稼働中のクラスターにアタッチされる揮発性のボリュームストレージに格納されるファイル、DBFSルートに格納されるファイルを操作する際の違いを理解することにフォーカスします。ここで説明するDBFSルートのコンセプトはマウントされたオブジェクトストレージにも直接適用することができます。これは、/mntディレクトリはDBFSルートの配下に存在するからです。また、サンプルの多くは、必要な権限を持っていればクラウドオブジェクトストレージや外部ロケーションの直接の操作にも適用することができます。
Databricksのルートパスとは何か?
Databricksにおけるルートパスは、実行されるコードによって異なります。
DBFSルートはSparkとDBFSコマンドのルートパスとなります。これには以下が含まれます。
- Spark SQL
- Sparkデータフレーム
dbutils.fs%fs
ドライバーにアタッチされるブロックストレージボリュームは、ローカルで実行されるコードのルートパスとなります。これには以下が含まれます。
%sh- 大部分のPythonコード(PySparkを除く)
- 大部分のScalaコード(Sparkを除く)
注意
Databricks Reposを使っている場合、%shのルートパスは現在お使いのレポのディレクトリとなります。詳細はプログラムでDatabricksワークスペースのファイルを操作するをご覧ください。
DBFSルートのファイルにアクセスする
DBFSルートがデフォルトとなっているコマンドを使用する際、相対パスあるいはdbfs:/を含めることができます。
SELECT * FROM parquet.`<path>`;
SELECT * FROM parquet.`dbfs:/<path>`
df = spark.read.load("<path>")
df.write.save("<path>")
dbutils.fs.<command> ("<path>")
%fs <command> /<path>
ドライバーのボリュームがデフォルトとなるコマンドを使用する際、パスの先頭に/dbfsを追加する必要があります。
%sh <command> /dbfs/<path>/
import os
os.<command>('/dbfs/<path>')
ドライバーのファイルシステムのファイルにアクセスする
ドライバーストレージがデフォルトのコマンドを使用する際、相対パスあるいは絶対パスを指定することができます。
%sh <command> /<path>
import os
os.<command>('/<path>')
DBFSルートがデフォルトのコマンドを使用する際は、file:/を使用する必要があります。
dbutils.fs.<command> ("file:/<path>")
%fs <command> file:/<path>
これらのファイルはアタッチされたドライバーノードのボリュームに存在しており、Sparkは分散処理エンジンであるので、全てのオペレーションがここにあるデータに直接アクセスできる訳ではありません。ドライバーのファイルシステムからDBFSにデータを移動する必要がある場合には、マジックコマンドあるいはDatabricksユーティリティを用いてファイルをコピーすることができます。
dbutils.fs.cp ("file:/<path>", "dbfs:/<path>")
%sh cp /<path> /dbfs/<path>
%fs cp file:/<path> /<path>
サンプルを通じてデフォルトロケーションを理解する
このセクションで説明されたコマンド、および、いつそれぞれの文法を使うべきかを要約、説明するテーブルと図となります。
| コマンド | デフォルトロケーション | rootからの読み込み | ローカルファイルシステムからの読み込み |
|---|---|---|---|
%fs |
DBFSルート | パスにfile:/を追加 |
|
%sh |
ローカルドライバーノード | パスに/dbfsを追加 |
|
dbutils.fs |
DBFSルート | パスにfile:/を追加 |
|
os.<command>や他のローカルコード |
ローカルドライバーノード | パスに/dbfsを追加 |
|
spark.[read/write] |
DBFSルート | サポートされていません |
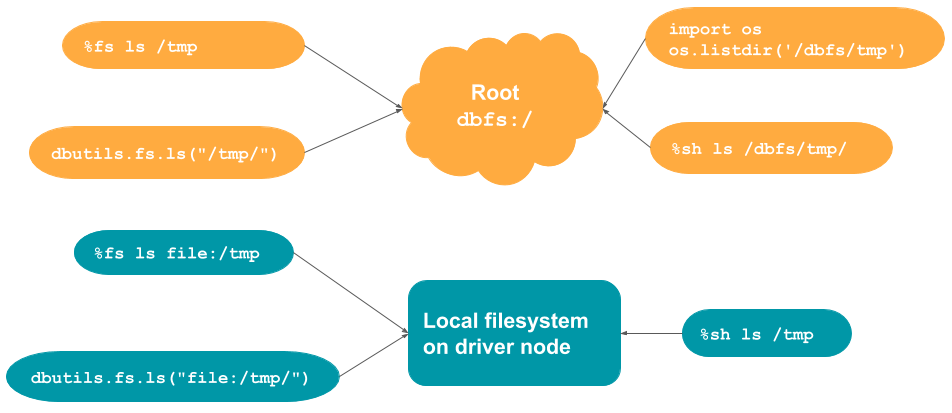
# %fsのデフォルトロケーションはDBFSルートです
%fs ls /tmp/
%fs mkdirs /tmp/my_cloud_dir
%fs cp /tmp/test_dbfs.txt /tmp/file_b.txt
# dbutils.fsのデフォルトロケーションはDBFSルートです
dbutils.fs.ls ("/tmp/")
dbutils.fs.put("/tmp/my_new_file", "This is a file in cloud storage.")
# %shのデフォルトロケーションはローカルファイルシステムです
%sh ls /dbfs/tmp/
# osコマンドのデフォルトロケーションはローカルファイルシステムです
import os
os.listdir('/dbfs/tmp')
# %fsとdbutils.fsを使用する際、ローカルファイルシステムから読み込むためには file:/ を使う必要があります
%fs ls file:/tmp
%fs mkdirs file:/tmp/my_local_dir
dbutils.fs.ls ("file:/tmp/")
dbutils.fs.put("file:/tmp/my_new_file", "This is a file on the local driver node.")
# %shはデフォルトでローカルファイルシステムから読み込みを行います
%sh ls /tmp
マウントされたオブジェクトストレージのファイルにアクセスする
DBFSにオブジェクトストレージをマウントすることで、ローカルファイルシステムに存在するかのようにオブジェクトストレージのオブジェクトにアクセスすることができます。
dbutils.fs.ls("/mnt/mymount")
df = spark.read.format("text").load("dbfs:/mymount/my_file.txt")
ローカルファイルAPIの制限
以下では、DatabricksランタイムのFUSEにおけるローカルファイルAPI使用時の制限を列挙します。
- クライアントサイド暗号化が有効化されたAmazon S3マウントをサポートしていません。
- ランダムの書き込みはサポートしていません。ランダムの書き込みが必要となるワークロードにおいては、以下のようにローカルディスクでオペレーションを行い、
/dbfsに結果をコピーするようにしてください。
# python
import xlsxwriter
from shutil import copyfile
workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx')
worksheet = workbook.add_worksheet()
worksheet.write(0, 0, "Key")
worksheet.write(0, 1, "Value")
workbook.close()
copyfile('/local_disk0/tmp/excel.xlsx', '/dbfs/tmp/excel.xlsx')
- スパースファイルはサポートされていません。スパースファイルをコピーするには、
cp --sparse=neverを使用してください。
$ cp sparse.file /dbfs/sparse.file
error writing '/dbfs/sparse.file': Operation not supported
$ cp --sparse=never sparse.file /dbfs/sparse.file