High Scale Geospatial Processing With Mosaic From Databricks Labs - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
規模のバリヤーを打ち破る(既存の課題の議論)
Databricksにおいては、ユーザーのデータのモダン化のジャーニーをサポートすることに大変なフォーカスを置いています。
多くのお客様が、地理空間情報分析のワークロードをシンプルにし、スケールする助けを求めて我々にコンタクトしてきています。何人かの方は完全に専門的なデータアーキテクチャを構築したいと思っています。他の方は、カスタムコードと欠かすことのできない依存関係を開発しました。多くの場合、例えば、データ取得の新たな方法やデータに貪欲な機械学習アプリケーションにデータを提供する際に直面するスケールの課題に対応するために、シングルノードの世界から分散処理の世界に飛び込む必要が出てきています。
このようなケースでは我々は多くの場合、プラットフォームのユーザーは大規模地理空間データを処理するために既存のオープンソースの選択肢で実験をしているのを目撃しています。これらの選択肢は多くの場合、顧客がすでに特定のフレームワークのベストプラティスやデプロイや活用法に慣れ親しんでいない限り、非常に急激な学習曲線を必要とします。ユーザーは既存の地理空間データエンジニアリングアプローチを通じて必要とされるパフォーマンスを達成するために苦戦しており、多くの人は空間情報ライブラリやパートナーの広範なエコシステムを用いた作業の柔軟性を必要としています。
設計における意思決定には常にトレードオフが存在し、我々がMosaicと呼ばれる新たな地理空間ライブラリを構築する間にお客様から話を聞き、学びを得ました。Mosaicの目的は様々なワークロードをスケーリングし、拡張する際の摩擦を削減し、お客様とのエンゲージメントを通じて得られたベストプラクティスのパターンのリポジトリを提供することです。
コアとして、MosaicはApache Spark™フレームワークの拡張であり、非常に大きな地理空間データセットを高速かつ容易に処理するように構築されています。Mosaicは以下の機能を提供します。
- 他のライブラリやパートナーを利用する柔軟性を残しつつも、DatabricksのDelta Lakeのパワーを活用したユニークな地理空間データエンジニアリングアプローチ。
- コアのMosaic関数内でSparkコードジェネレーションの実装を通じた高いパフォーマンス。
- 空間データセットを変換、集計、joinするためのSparkエクスプレッションとして、数多くのOGC標準の空間SQL(ST_)関数。
- 大規模な空間情報joinを実行する際の最適化。
- WKT、WKB、GeoJSONのような一般的な空間データエンコーディング間の容易な変換処理。
- Sparkネイティブデータタイプから容易に新たなジオメトリクスを生成するコンストラクタ、および、JTS Topology Suite (JTS)、Environmental Systems Research Institute (Esri)ジオメトリ型への変換。
- Scala、SQL、Python APIの活用。
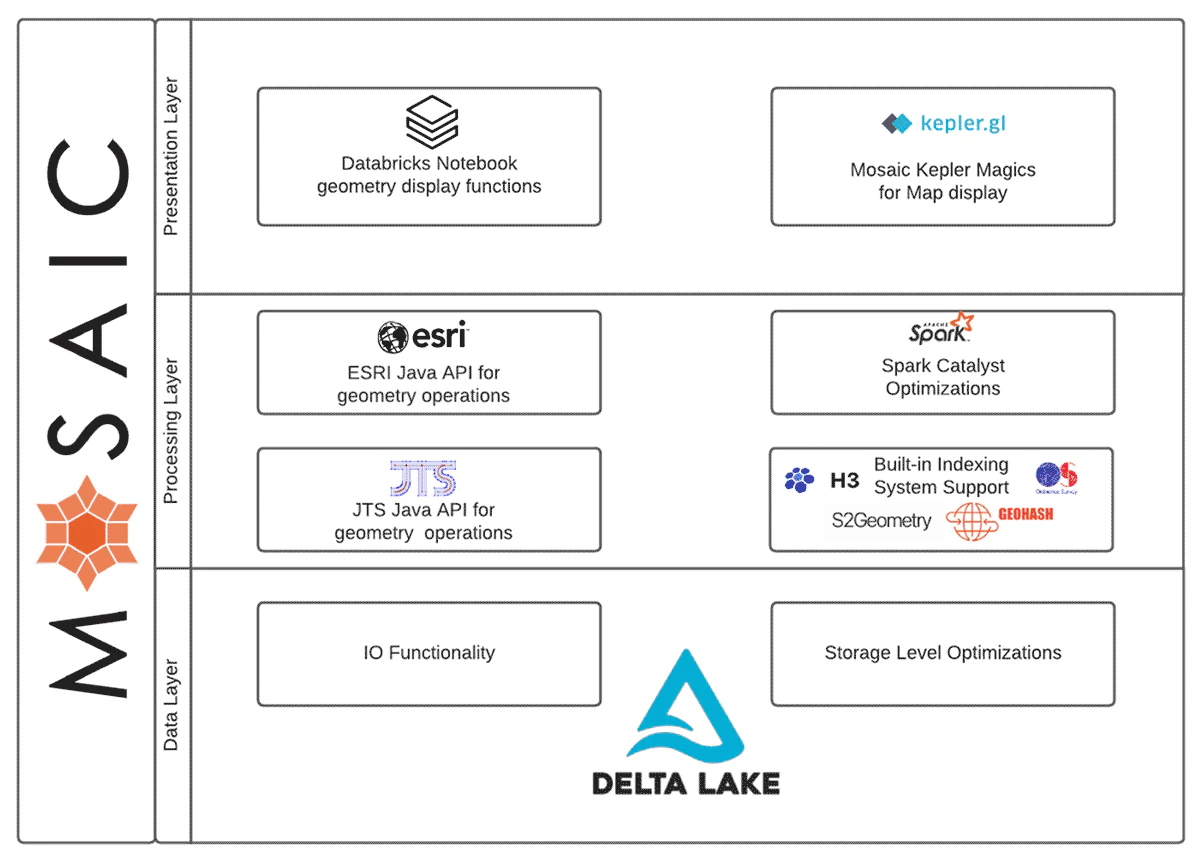
図1: Mosaicの機能的デザイン
エコシステムを活用する
Mosaicに対する我々のアイデアは、SparkとDeltaの領域と、もう一方の既存エコシステムの領域をフィットさせるというものです。我々はMosaicを、高レベルの並列性によって利益を得ることができるシステムに、地理空間情報をインテグレーションするノウハウをもたらすライブラリとして設計しています。MosaicとともにApache SedonaやGeoMesaのような人気のあるフレームワークを利用することができ、既存のアーキテクチャの拡張として、柔軟かつパワフルな選択肢となります。
一方で、追加で必要な地理空間ツールなしに、設計されたシステムをMosaicのデータアーキテクチャに移行することができるので、複数言語とのサポートと統合APIによって最低限の労力で高いスケーラビリティとパフォーマンスを活用することができます。Mosaicがネイティブにレイクハウスアーキテクチャ上に構築されることで価値が追加され、お使いの地理空間データプラットフォームで、AI/ML、高度分析の機能を解放することができます。
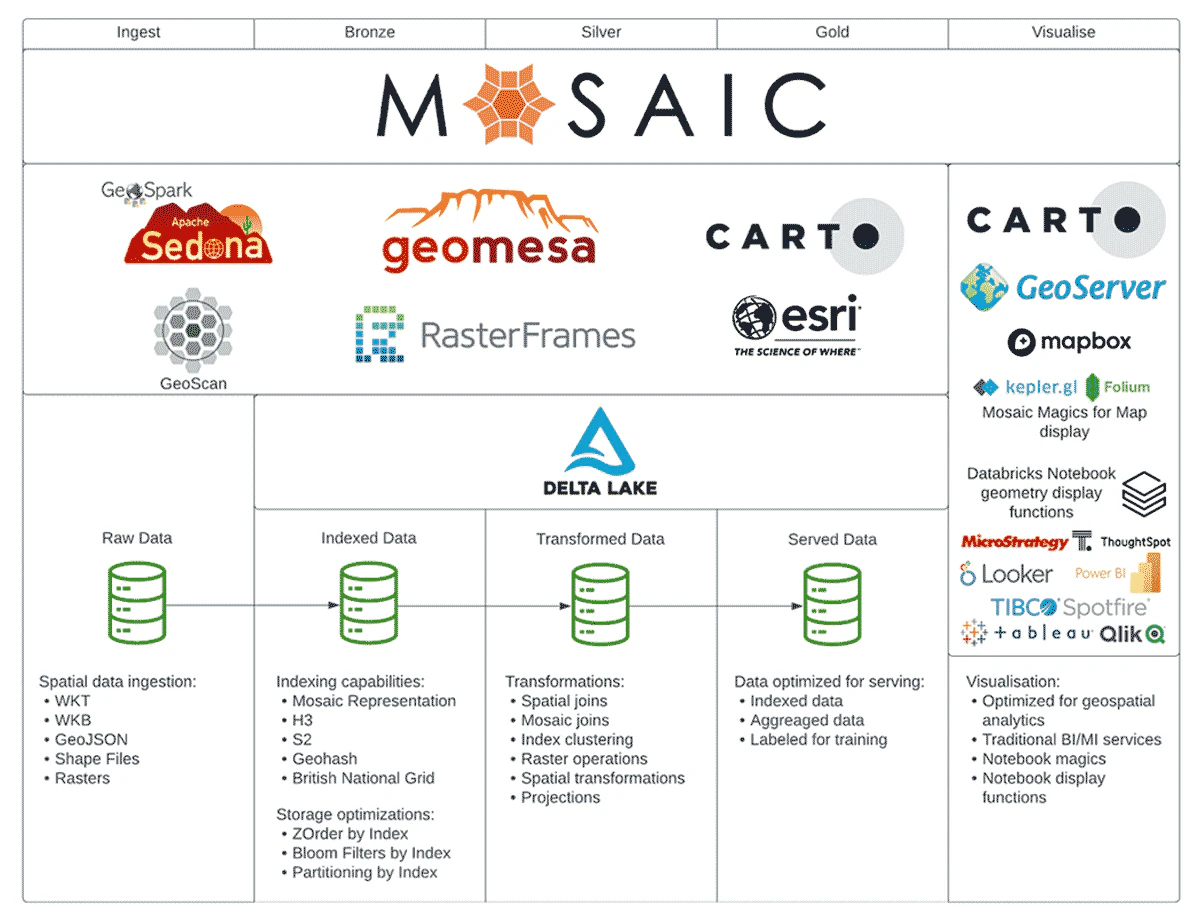
図2: Mosaicと地理空間情報エコシステム
最後に、CARTO、GeoServer、MapBoxのようなソリューションはお使いのアーキテクチャの重要なパーツであり続けます。Mosaicでは、皆様のデザイン、アーキテクチャにパフォーマンスとスケーラビリティを提供することを目的としています。ビジュアライゼーションやインタラクティブな地図は、得意とするソリューションに委任されるべきです。我々の狙いは、車輪を再発明することではなく、フィールドで特定したギャップに取り組み、モザイクにおける欠けたタイルとなることです。
立証されたパターンを活用する
Mosaicは、Databricksのお客様の課題を解決するために開発した、有用かつ、現場で開発された地理空間パターンの全てをカバーするインベントリのエクササイズから誕生しました。このプロセスのアウトプットを通じて、これらのパターンをパッケージングし、お客さまが直接活用できるフレームワークを作成することで多大なる価値を生み出せることを示しました。
Mosaicのことを、我々が現場で特定したベストプラクティスのモザイクであると言っても構いません。
我々のフレームワークにこの名前を選んだのには別の理由もあります。Mosaicの基盤は、こちらのOrdnance SurveyとMicrosoftとの共著であるブログ記事で議論した技術となっており、背後の階層型空間インデックスをグリッドとして用いてジオメトリクスを表現するためにこの技術を選択することで、複雑なポリゴンをラスターと局所化したベクトル表現の両方で表現できるようにしました。

図3: MosaicにおけるBNGを用いたベクトルジオメトリ表現のアプローチ
このアプローチの有効なユースケースは、ジオメトリック交差問題(ポイントインポリゴンのjoinなど)をパーティショニングするためにイギリスにおけるグリッドベースの空間インデックスであるBNGを活用することで最初から立証されています。この技術を適用するファーストパスは非常に良い結果と、意図したアプリケーションにおいて優れたパフォーマンスを達成し、より広い範囲の問題に一般化するためには非常に重要である実装がもたらされました。
これが、Mosaicにおいては、BNGの部分をH3空間インデックスシステムで理由であり、将来的なお客様の要望においては別のインデックスを取り込む可能性があります。H3は一般的な六角形を整数値のIDにマッピングするグローバル階層型インデックスシステムです。本質的に六角形は他の形状よりも優れており、精度の維持や近似距離の計算のための固有のインデックスシステム構造を活用することができます。H3はmosaicのアプローチを再現するのに十分に豊富なAPIを有しており、さらに、Databricksノートブック環境での開発を含むワークフローで空間情報をレンダリングするイネーブラであるKeplerGLとネイティブでインテグレーションされています。

図4: MosaicにおけるH3を用いたベクトルジオメトリ表現のアプローチ
Mosaicは空間の完璧なパーティションを形成するいかなる階層型空間インデックスシステムに適用できるように設計されました。空間の完璧なパーティションというものには、2つの要件があります。
- 特定の解像度においてオーバーラップするインデックスがないこと
- 特定の解像度における完全なインデックスのセットは観測された空間のエンベロープを形成すること
これら2つの条件を満たすことで、従来のラスター化とは異なりオペレーションをやり直すことができる、我々の擬似ラスター化アプローチを計算することができます。Mosaicはいくつかのインデックス戦略を可能とするAPIを公開します。
- 追加カラムとしてジオメトリに隣接して維持されるインデックス
- サテライトテーブル内に分離されたインデックス
- ジオメトリチッピングやモザイキングを通じたインデックスに対するオリジナルテーブウrのエクスプロード
これらのアプローチのそれぞれは、異なるシチュエーションデメリットを提供します。パフォーマンスと使いやすさのベストなトレードオフは、オリジナルテーブルをエクスプロードすることだと我々は信じています。これは、テーブルの行数を増加させますが、このアプローチは行内の偏りに対応しており、Z-OrderやBloomフィルターのようなテクニックを活用する機会を最大化します。さらに、各行に格納されているよりシンプルなジオメトリクスによって、すべての地理空間述語はシンプルな局所的ジオメトリ表現に対して動作するので、より高速に実行されるようになります。
このブログ記事のフォーカスは、Delta Lakeを活用するインデックス作成戦略に対するMosaicのアプローチにあります。Delta Lakeは、大量のビッグデータを処理する際に非常に有用な機能を提供しており、Sparkがピークのパフォーマンスを達成するのに役立ちます。地理空間情報データエンジニアリングを行い、地理空間情報システムを構築するためには、DeltaのZ-Orderingが非常に重要な機能となります。簡単にいうと、Z-Orderingはクエリーを行う際にスキップできるデータの量を最大化できるように、ストレージ上のデータを整理します。
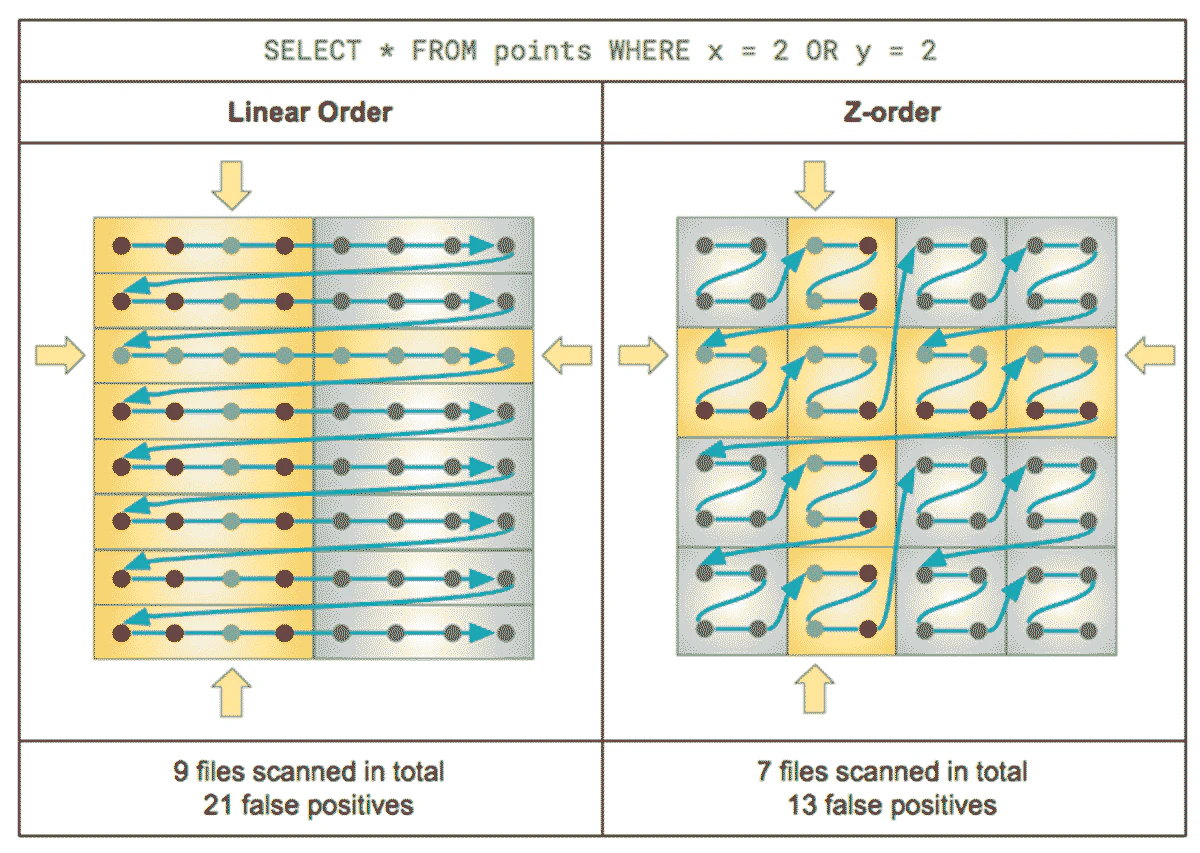
図5: ストレージ上のデータに対するZ-Orderと線形の並び替えの比較
地理空間データセットには統合された特徴量があります:これらは物理世界に位置づけられるコンセプトを表現します。適切なZ-orderingを適用することで、物理的に近いデータポイントが、ストレージ上でも近い場所に配置されるようになります。クエリーを行う際に高い局所性が得られるので有利となります。多くの地理情報クエリーは、限定された局所的なエリア、あるいは、離れている地点ではなく互いに近接しているデータポイントを一緒に処理することを狙いとしています。
このようなケースでは、H3のようなインデクシングシステムが非常に役立ちます。特定の解像度におけるH3のIDは、現実世界における近接性を持つ場合には近い値となります。このため、H3のIDはDelta LakeのZ-orderingを適用する完璧な候補となります。
Databricksにおける地理空間情報をシンプルにする
現在、ビジネスニーズに取り組むのに必要なデータの処理量は指数関数的に増加しています。これによる2つの結末は明らかなものです。
- もはや、シングルマシンにはデータが収まりません
- 企業は、クラウドによってもたらされるキーテクノロジーを用いてモダンなデータスタックを実装しています
レイクハウスアーキテクチャと、SparkやDeltaのようなサポート技術はモダンデータスタックにおける重要なコンポーネントとなっており、データの世界におけるこれらの新たな課題の解決に非常に役立つものとなっています。しかし、高度に複雑なジオメトリとの大規模なjoinを行うためにこれらのツールを使うことになると、多くのユーザーにとっては大変なタスクとなってきます。
これまではこのようなコンセプトが複数のフレームワークによってもたらされていたため、エンドユーザーは多くの場合気づいておらず、ユーザーがシステムを完全にコントロールする能力を限定してましたが、MosaicはではDatabricksにおける地理空間処理にシンプルさをもたらし、コンセプトを実現できるようになります。ここでの狙いは、以降の処理、解析、可視化におけるベースラインとして動作するコアの地理空間データエンジニアリングを適用しつつも、変化するユーザーのニーズに対応できるモジュール化されたシステムを提供することです。Mosaicでは、JTSやEsriタイプを用いたジオメトリクスの実行時表現をサポートしています。シンプルさを念頭に置いて、Mosaicでは両方のジオメトリパッケージで動作する統合抽象化レイヤを提供し、SparkにおけるデータセットAPIの利用に最適化されるように設計されています。2つのパッケージ間の切り替えが複雑なものであってはなく、クエリーを構成する方法に影響を与えてはならないので、統合することが重要です。
%python
from mosaic import enable_mosaic
spark.conf.set(
"spark.databricks.mosaic.geometry.api",
"JTS"
)
enable_mosaic(spark, dbutils)
left_df.join(
right_df,
on=["h3_index"],
how="inner"
).groupBy(
key
).count()
図6: H3とJTSを用いたMosaicクエリー
%python
from mosaic import enable_mosaic
spark.conf.set(
"spark.databricks.mosaic.geometry.api",
"ESRI"
)
enable_mosaic(spark, dbutils)
left_df.join(
right_df,
on=["h3_index"],
how="inner"
).groupBy(
key
).count()
図7: H3とEsriを用いたMosaicクエリー
上のアプローチでは、同じノートブック上ではなく、異なるタスクに対してJTSやEsriジオメトリパッケージ間を容易に切り替えられるように意図しています。単一のノートブックやパイプラインの単一のステップでは単一のMosaicコンテキストを使用することを強くお勧めします。
地理情報関連のクエリーや変換処理において、使いやすいAPIをまとめるインデクシングパターンを提供することで、Spark、Deltaの両方とインテグレーションすることで、お使いの大規模システムの完全なる潜在能力を解き放ちます。
%python
df = df.withColumn(
"index", mosaic_explode(col("shape"))
)
df.write.format("delta").save(location)
%sql
CREATE TABLE table_name
USING DELTA
LOCATION location
OPTIMIZE table_name
ZORDER BY (index.h3)
図8: DeltaのZ-orderingと組み合わせたMosaicのエクスプロード
この擬似ラスター化のアプローチによって、WHERE句を追加、削除することで、容易に許容できる精度による高速joinと高精度joinとを切り替えることができます。
%python
# rasterized query
# faster but less precise
left_df.join(
right_df,
on=["index.h3"],
how="inner"
).groupBy(
key
).count()
図9: インデックスのみを用いたMosaicクエリー
%python
# detailed query
# slower but more precise
left_df.join(
right_df,
on=["index.h3"],
how="inner"
).where(
col("is_core") ||
st_contains(col("chip"), col("point"))
).groupBy(
key
).count()
図10: チップ詳細を用いたMosaicクエリー
なぜ、このアプローチを選んだのでしょうか?シンプルさは多くの側面を持っており、よく見逃されるシンプルさの側面は、お使いのコードがどれだけ明示的かということです。明示的であることは、ほぼ常に暗黙的であることよりも優れています。挙動を決定するために設定値を用いるのではなく、WHERE句を用いることで可読性がより高いコードとなり、容易にコードを解釈できるようになります。さらに、コードの挙動には一貫性があり、ワークスペースや他のプラットフォームにコードをコピーしたとしても、動作を再現することができます。
最後に、お使いの既存のソリューションがH3の機能を活用していおり、データの構造を見直したくないのであれば、Mosaicは皆様の地理空間パイプラインの簡素化を通じて多大なる価値をもたらすことができます。MosaicはネイティブでサポートされるH3の機能のサブセットを提供します。
%python
df.withColumn(
"indices", polyfill(col("shape"))
)
図11: シェイプのpolyfillのためのMosaicクエリー
%python
df.withColumn(
"index", point_index_geom(col("point"))
)
図12: ポイントインデックスのMosaicクエリー
イノベーションを加速する
Mosaicの主な動機付けは、シンプルさとより広範なエコシステムとのインテグレーションです。しかし、パフォーマンスと計算処理能力を保証できないのであれば、このような柔軟性はあまり意味のないものになります。2つの主要なオペレーションにおいてMosaicを評価しました:ポイントインポリゴンのjoinとポリゴン交差のjoinです。さらに、インデクシングステージにおいて期待するパフォーマンスを評価しました。両方のユースケースで、我々は事前にインデックスを作成し、データをDeltaテーブルに格納しました。Z-orderオペレーションを使用する前後で両方のオペレーションを実行し、皆様の地理情報処理の取り組みにDeltaがもたらすメリットをハイライトしました。
polygon-to-polygon joinにおいては、polygon-intersects-polygonリレーションシップにフォーカシしました。このリレーションシップは、2つのポリゴンが交差するかどうかを表現するブール値を返却します。H3の解像度が7、8、9、そして、20万ポリゴンから500万ポリゴンのデータセットを用いてベンチマークを行いました。
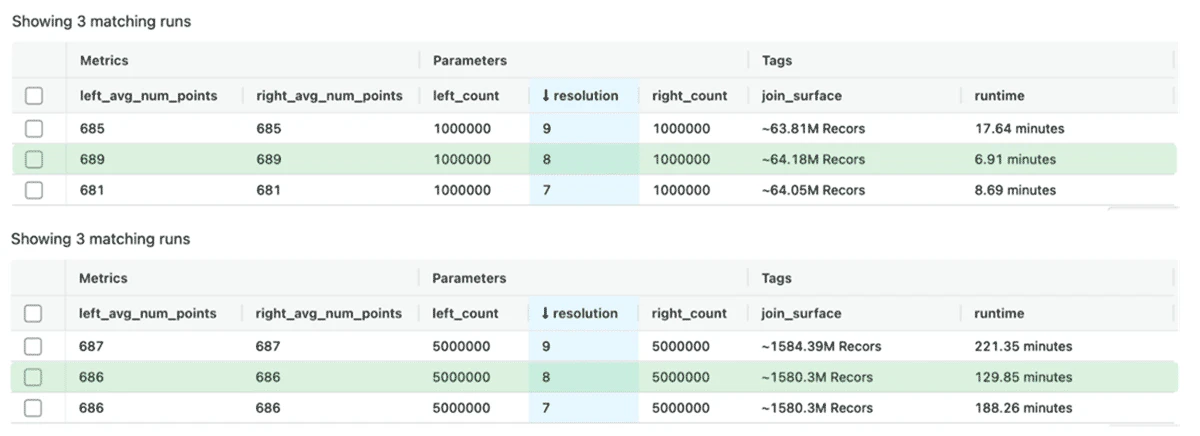
図13: Mosaicにおけるポリゴン交差のベンチマーク
解像度7と8の結果を比較すると、解像度8の方が平均して良い結果となっていることがわかりました。さらに、特筆すべきこととしては、最大のワークロードである500万ポリゴンと500万ポリゴンのjonは15億のマッチングを必要としますが、解像度7では3時間かかっていましたが、解像度8では2時間強で処理が終わりました。適切な解像度を選択することは重要なタスクです。あまりに粗い解像度(低い解像度の値)を選択すると、ジオメトリクスを表現しきれないリスクを引き起こし、地理空間情報データの偏りを解決できずパフォーマンスが低下する可能性が出てきます。詳細すぎる解像度(高い解像度の値)を選択すると、ジオメトリクスを細かく表現しすぎるリスクを引き起こし、データの爆発を引き起こし性能が劣化します。適切なバランスを取ることが重要であり、我々のベンチマークでは適切な解像度を選択することが重要であることを強調する、30%程度の実効性能の最適化が認められました。我々のデータセットでは、シェイプごとのノード数は平均680から690の値であり、Mosaicのアプローチを用いることで大量の複雑な形状をハンドリングできることを示しています。
解像度を9に増やすとパフォーマンスの低下が認められました。これはポリゴンに多くのインデックスを使用することで過剰表現の問題に直面しているためです。これによって、インデックスのマッチングの解決に多くの時間を要することになり、全体的なパフォーマンスを低下させています。このため、我々はMosaicに、データセットを解析し、お使いのポリゴンに必要なインデックス数の分布を提示する機能を追加しました。
%python
from mosaic import MosaicAnalyzer
analyzer = MosaicAnalyzer()
optimal_resolution = analyzer.get_optimal_resolution(geoJsonDF, "geometry")
optimal_resolution
図14: Mosaicにおける最適な解像度の特定
完全なベンチマークについては、実行するオペレーションの全体像を議論し、得られた結果に対するさまざまな分析結果を提供しているMosaic documentation pageをご覧ください。
ユースケースの地図を構築する
Mosaicによって、パフォーマンスと表現能力、シンプルさのバランスを取ることができました。このようなバランスを取ることで、地理空間エコシステムにおける将来のDatabricksの製品への投資、パートナーシップに備えたモダンかつスケーラブルなエンドツーエンドのユースケースを実現する道を整備しました。我々は様々な業界のお客様とともに作業しており、現実世界における数多くのアプリケーションを特定しています。向こう数ヶ月を通じて、我々はソリューションアクセラレータ、チュートリアル、使い方のサンプルを開発する予定です。Mosaicのgithubリポジトリには、既存および今後のコードリリースとともにこれらのコンテンツが格納されます。Databricks Reposを用いてMosaicノートブックサンプルに容易にアクセスすることができ、モダンな地理空間データプラットフォームをキックスタートすることができます。追加コンテンツを楽しみにしていてください!
使ってみる
レイクハウスでの地理空間情報分析を加速するために、DatabricksでMosaicをトライしてみませんか。そして、詳細についてはコンタクトしてください。類似のユースケースを用いてサポートさせていただきます。
- MosaicはこちらのDatabricks Labsリポジトリから利用できます。
- 詳細なMosaicのドキュメントはこちらです。
- 最新のコードサンプルにはこちらからアクセスできます。
- 最新のアーティファクトやバイナリに関してはこちらの指示に従ってください。