こちらのサンプルを動かしながら、Pandas API on Spark(Koalas)を説明します。
以前にこちらの記事も翻訳してます。
Pandas API on Sparkとは
その前にpandasの話をさせてください。Pythonを使っている人であれば、まず間違いなく使ったことがあるであろうpandas。テーブルデータを取り扱う際には欠かせないものとなっています。ですので、学校、書籍などでデータサイエンスを学ぶ際には必修科目となっていることでしょう。しかし、pandasには以下のような課題があります。
- メモリに乗り切らない大規模データは処理できません
- (通常は)並列処理が行えません
一方で、文法はわかりやすく、小規模なデータを取り扱うのであればベストな選択肢と言えます。

しかし、年を経るごとに取り扱うデータ量は増加の一途を辿っており、pandasで全てをやり切ることが困難になっているのも事実です。そう言った背景もあり、Apache Sparkなどの並列処理エンジンの人気が高まり、PythonのAPIであるPySparkも広く利用されるようになっています。
しかし、PySparkの文法はpandasとは結構異なっており、初学者にとっては敷居の高いものとなっていました。
| pandasデータフレーム | PySparkデータフレーム | |
|---|---|---|
| 列指定 | df['col'] | df['col'] |
| データフレームの可変性 | 可変 | 不変 |
| 処理実行 | 即時実行(eagerly) | 遅延実行(lazily) |
| 列の加算 | df['c'] = df['a'] + df['b'] | df = df.withColumn('c', df['a'] + df['b']) |
| 列名の変更 | df.columns = ['a','b'] | df = df.select(df['c1'].alias('a'), df['c2'].alias('b')) df = df.toDF('a', 'b') |
| 値のカウント | df['col'].value_counts() | df.groupBy(df['col']).count().orderBy('count', ascending=False) |
このようなギャップを埋める目的でスタートしたプロジェクトがKoalasです。

- 2019/4/24に発表
- Apache Spark上でpandas APIを提供することが狙い
- 馴染み深いAPIで2つのエコシステムを統合
- 小規模データと大規模データ間のシームレスな移行
- pandasユーザーのメリット
- Koalasを用いてpandasコードをスケールアウト
- PySparkの学習をより簡単に
- PySparkユーザーのメリット
- pandasライクの機能でより生産的に
そして、このKoalasプロジェクトはSpark 3.2でSparkに統合されたので、個別にKoalasをインストールしなくてもPandas API on Sparkでpandas APIを活用することができるのです!
| pandas | PySpark | Pandas API on Spark(Koalas) |
|---|---|---|
| import pandas as pd df = pd.read_csv("/path/to/my_data.csv") |
df = (spark.read .option("inferSchema", "true") .csv("/path/to/my_data.csv")) |
import pyspark.pandas as ps df = ps.read_csv("/path/to/my_data.csv") |
| df.columns = ['x', 'y', 'z1'] | df = df.toDF('x', 'y', 'z1') | df.columns = ['x', 'y', 'z1'] |
| df['x2'] = df.x * df.x | df = df.withColumn('x2', df.x * df.x) | df['x2'] = df.x * df.x |
サンプルのウォークスルー
# Pandasのread_json(from pandas import read_json)ではなく、Sparkの分散能力を活用するために、単にpyspark pandasをインポートします
from pyspark.pandas import read_json
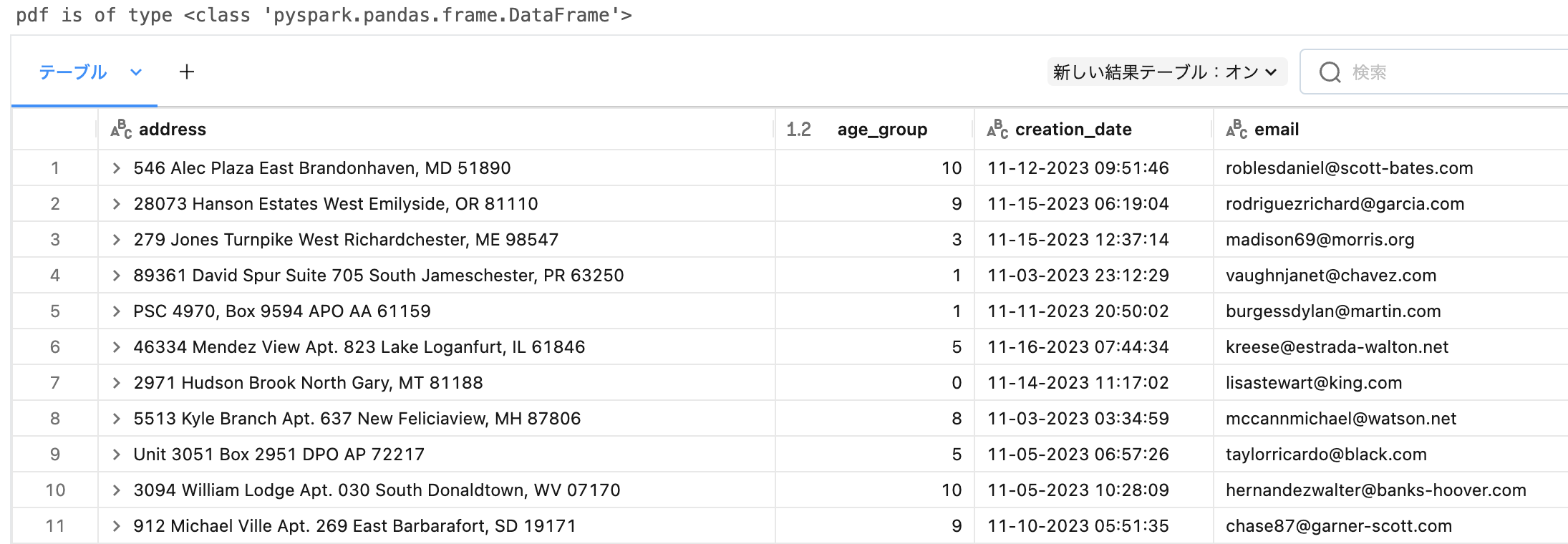
pdf = read_json(cloud_storage_path+"/koalas/users")
print(f"pdf is of type {type(pdf)}")
display(pdf)
このデータフレームはSparkデータフレームではなく、Pyspark.pandasデータフレームであることに注意してください。はまりそうなポイントが丁寧にまとめられています。以下のどのデータフレームを操作しているのかに注意を払う必要があります。
- pandasデータフレーム
- Sparkデータフレーム
- Pandas on Sparkデータフレーム
pdf is of type <class 'pyspark.pandas.frame.DataFrame'>
pandasデータフレームからPandas on Sparkデータフレームへの変換
from pyspark.pandas import from_pandas
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
# pandasデータフレームをpandas on sparkに変換し、Sparkのスピードと並列実効性の全てを手に入れます
pdf = from_pandas(df)
print(f"pdf is of type {type(pdf)}")
# 標準的なpandasオペレーションを適用します
pdf.mean()
pdf is of type <class 'pyspark.pandas.frame.DataFrame'>
A 0.083945
B -0.044224
C 0.530140
D 0.577575
dtype: float64
SparkデータフレームからPandas on Sparkデータフレームへの変換
# また、一つの指示でSparkデータフレームをPandas on Sparkデータフレームに変換することができます
# 例として、Unity Catalogからひとつのテーブルを簡単に読み込んで、データサイエンスの分析にpandas APIを活用することができます
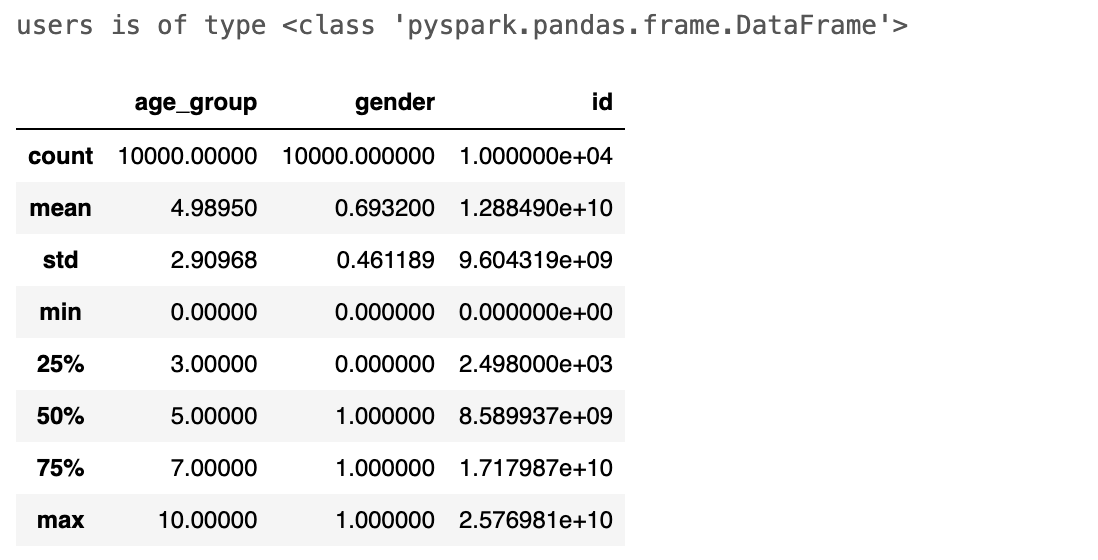
users = spark.read.json(cloud_storage_path+"/koalas/users").pandas_api()
print(f"users is of type {type(users)}")
users.describe()
データセットの探索
users["age_group"].value_counts(dropna=False).sort_values()
10.0 497
0.0 510
7.0 941
3.0 976
2.0 990
1.0 991
9.0 995
8.0 1005
5.0 1014
6.0 1025
4.0 1056
Name: age_group, dtype: int64
Pandas on Sparkデータフレームに対するSQL実行
from pyspark.pandas import sql
age_group = 2
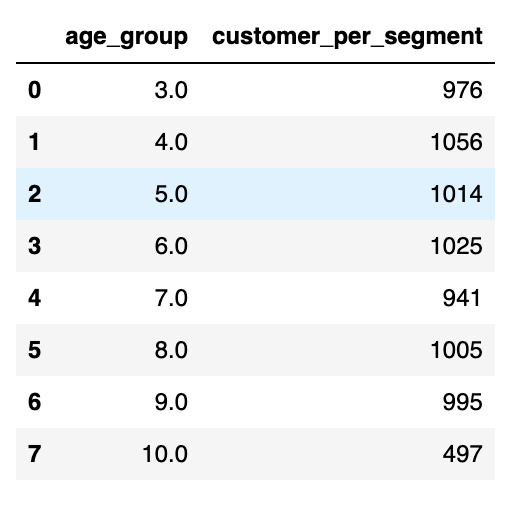
sql("""SELECT age_group, COUNT(*) AS customer_per_segment FROM {users}
where age_group > {age_group}
GROUP BY age_group ORDER BY age_group """, users=users, age_group=age_group)
可視化
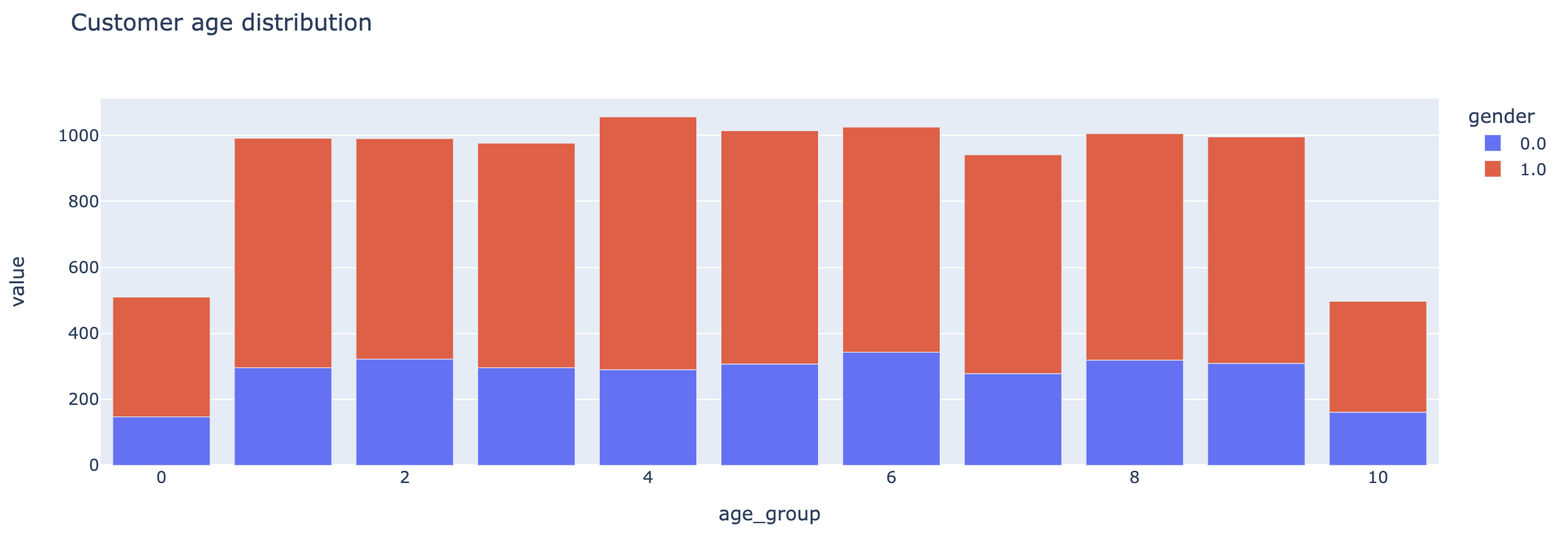
Pandas API on Sparkはインタラクティブなチャート生成でplotlyを活用しています。洞察を得るには、.plotメソッドを使用します。
df = users.groupby('gender')['age_group'].value_counts().unstack(0)
df.plot.bar(title="Customer age distribution")
まとめ
(私も)慣れ親しんでいるpandasのAPIを活用しながらも、Sparkの強力な並列分散処理能力を活用できる、Pandas API on Spark(Koalas)、是非ご活用ください!ただ、より複雑なことをやる可能性があるのであれば、このAPIを契機にしてPySparkも学ばれることもお勧めします。Databricksであれば、AIアシスタントも支援してくれます!