Introducing MLflow: an Open Source Platform for the Complete Machine Learning Lifecycleの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2018年の記事です。
機械学習の開発に携わった人は誰も、それが複雑であることを知っています。ソフトウェアは開発における通常の懸念に加え、機械学習(ML)開発では新たな複数の課題が存在します。Databricksでは、MLを活用している数百の企業と共に取り組みを行っており、同じような懸念を何度も伺っています:
- 無数のツール。 データの準備からモデルのトレーニングに至るMLのライフサイクルのそれぞれのフェーズを、数百のオープンソースツールがカバーしています。しかし、チームがそれぞれのフェーズで一つのツールを選択する従来のソフトウェア開発と異なり、MLでは結果が改善されるのかを確認するために、通常は利用可能なすべてのツール(アルゴリズムなど)をトライしたいと考えます。このため、ML開発者は膨大な数のライブラリを活用し、プロダクションに投入する必要があります。
- 実験の追跡が困難。 機械学習アルゴリズムには、膨大な数の設定可能なパラメータが存在し、あなたが一人で作業するのかチームで作業するのかにかかわらず、モデルを生成するためのそれぞれの実験でどのパラメーター、コード、データが使用されたのかを追跡することが困難です。
- 結果の再現が困難。 詳細な追跡なしには、チームが同じコードを動作させる際にトラブルに見舞われることになるでしょう。あなたがトレーニングコードをプロダクションで使用するためにエンジニアに引き渡すデータサイエンティストであっても、問題をデバックするために過去の取り組みを振り返ろうとしていても、MLワークフローのステップの再現は重要となります。
- MLのデプロイが困難。 膨大な数のデプロイメントツールや、モデルを実行するのに必要な環境(RESTサービング、バッチ推論、モバイルアプリなど)によって、モデルをプロダクションに移行することは困難となります。すべてのライブラリをそれらすべてのツールに移行するために標準化された方法は存在しておらず、新たなデプロイメントごとにリク酢を生じさせることになります。
これらの課題によって、ML開発も従来のソフトウェア開発と同じように、堅牢かつ広く利用されるものになるためには、大きく進化する必要があることは明らかです。このため、多くの企業はMLライフサイクルを管理するために内部で機械学習プラットフォームを構築し始めました。例えば、データの準備やモデルのトレーニング、デプロイメントのために、Facebook、Google、UberはFBLearner Flow、TFX、Michelangeloを開発しました。しかし、これらの内部プラットフォームは限定的なものであるだけでなく(典型的なMLプラットフォームはビルトインアルゴリズムの小規模なセットあるいは単一のMLライブラリしかサポートしていませんでした)、それらはそれぞれの企業のインフラストラクチャに紐付けられていました。ユーザーは容易に新たなMLライブラリを活用したり、より広いコミュニティに自分たちの成果を共有することができませんでした。
Databricksでは、MLライフサイクルを管理するためのより良い方法があるに違いないと信じており、だからこそ、本日アルファをリリースするMLflow: オープンソース機械学習プラットフォームを発表できることを嬉しく思っているのです。
MLflow:オープンソース機械学習プラットフォーム
MLflowは既存のMLプラットフォームからインスピレーションを得ていますが、2つの観点でオープンなものとして設計されています:
- オープンなインタフェース: MLflowはすべてのMLライブラリ、アルゴリズム、デプロイメントツール、言語と動作するように設計されています。小規模なセットのビルトイン機能のみを提供するのでは無く、さまざまなツールから利用できるようにREST APIとシンプルなデータフォーマット(ラムダ関数としてモデルを参照できる等)で構築されています。また、これによって、既存のMLコードをにMLflowを容易に追加できるので、すぐにメリットを享受でき、組織の他の人が実行できるように任意のMLライブラリを用いたコードを共有できるようになります。
- オープンソース: 我々は、ユーザーやライブラリ開発者が拡張できるようにオープンソースプロジェクトとしてMLflowをリリースします。さらに、ご自身のコードをオープンソース化したいと思うのであれば、MLflowのオープンフォーマットによって、組織におけるワークフローステップやモデルの共有が非常に容易になります。
MLflowは現時点ではアルファですが、MLコードを取り扱うための有用なフレームワークを提供するものであると信じており、フィードバックをぜひお聞かせいただきたいと思っています。この記事では、MLflowを詳細にご紹介し、コンポーネントを説明します。
MLflowアルファリリースのコンポーネント
この最初のMLflowのアルファリリースでは3つのコンポーネントが含まれます:
MLflowトラッキング
MLflowトラッキングは、ご自身の機械学習コードを実行する際に後で可視化できるように、パラメーター、コードのバージョン、メトリクスや出力ファイルを記録するためのAPIとUIです。数行のシンプルなコードで、パラメーター、メトリクス、アーティファクトを追跡することができます:
import mlflow
# Log parameters (key-value pairs)
mlflow.log_param("num_dimensions", 8)
mlflow.log_param("regularization", 0.1)
# Log a metric; metrics can be updated throughout the run
mlflow.log_metric("accuracy", 0.1)
...
mlflow.log_metric("accuracy", 0.45)
# Log artifacts (output files)
mlflow.log_artifact("roc.png")
mlflow.log_artifact("model.pkl")
結果をローカルファイルあるいやサーバーに記録し、複数のランを比較できるように、いかなる環境(例えば、スタンドアローンのスクリプトやノートブック)でもMLflowトラッキングを活用することができます。Web UIを用いることで、複数のランの出力を参照、比較することができます。また、チームでは異なるユーザーからの結果を比較するためにこのツールを活用することができます:
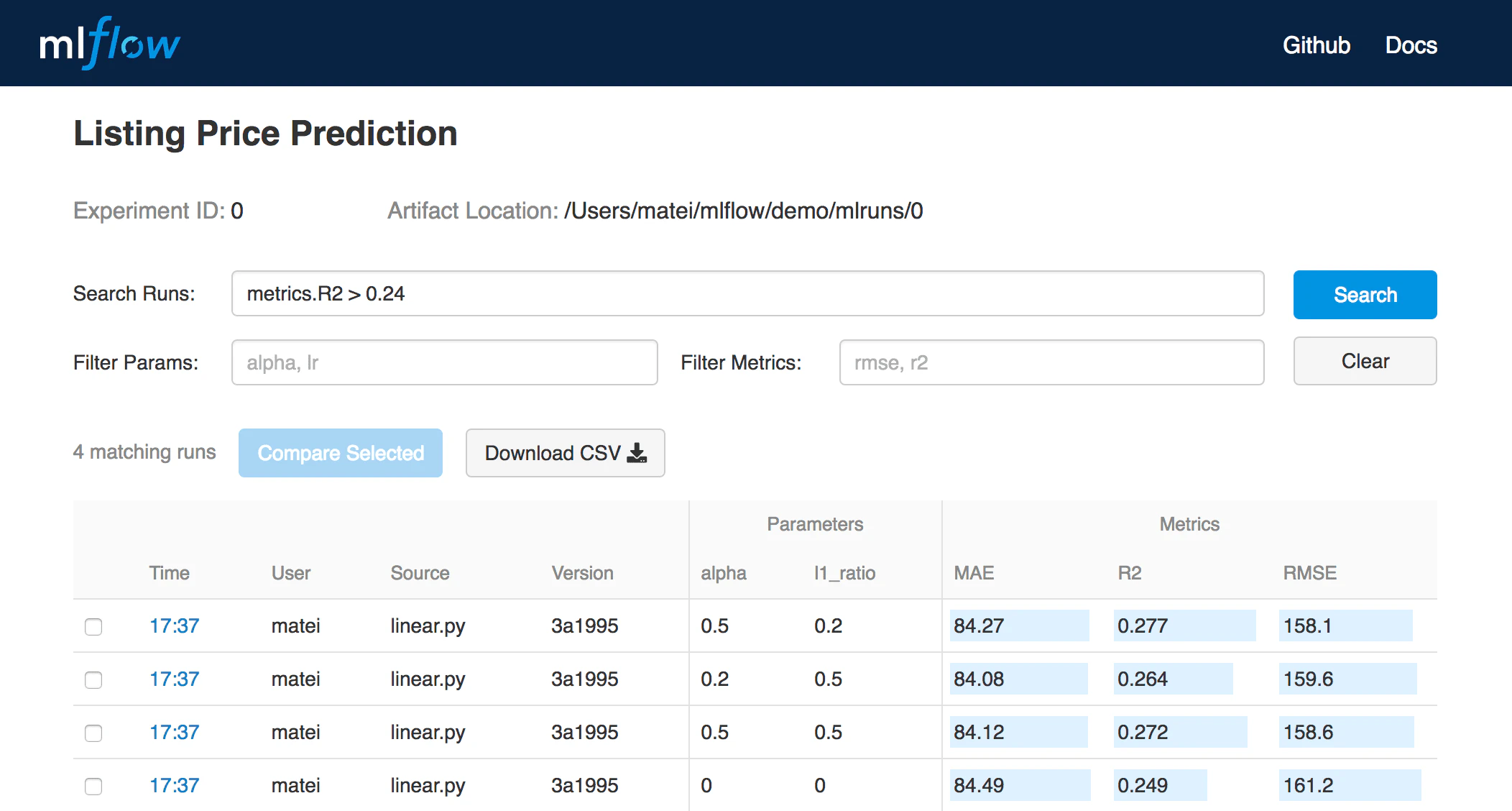
MLflowトラッキングのUI
MLflowプロジェクト
MLflowプロジェクトは、再利用可能なデータサイエンスコードをパッケージングするための標準フォーマットを提供します。それぞれのプロジェクトは、コードやGitリポジトリのディレクトリであり、依存関係やコードの実行方法を指定するためのディスクリプタファイルを使用します。MLflowプロジェクトはMLprojectと呼ばれるシンプルなYAMLファイルによって定義されます。
name: My Project
conda_env: conda.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
プロジェクトでは、Conda環境を通じて自身の依存関係を指定することができます。プロジェクトには、名前付きパラメーターを用いてランを起動する複数のエントリーポイントを含めることができます。ローカルファイルあるいはGitリポジトリに対してmlflow runコマンドラインツールを用いてプロジェクトを実行することができます:
mlflow run example/project -P alpha=0.5
mlflow run git@github.com:databricks/mlflow-example.git -P alpha=0.5
MLflowは自動でプロジェクトに適切な環境をセットアップして実行します。さらに、プロジェクトでMLflow Tracking APIを使っている場合には、実行されたプロジェクトのバージョン(すなわち、Gitコミット)とすべてのパラメーターを記憶します。これによって、全く同じコードを容易に再実行することができます。
プロジェクトのフォーマットによって、企業であっても、オープンソースコミュニティであっても、容易に再現可能なデータサイエンスコードを共有できるようになります。MLflowトラッキングと組み合わせることで、MLflowプロジェクトは再現可能性、拡張可能性、実験における偉大なツールを提供します。
MLflowモデル
MLflowモデルは、フレーバーと呼ばれる複数のフォーマットで、機械学習モデルをパッケージングするための慣習です。MLflowはさまざまなモデルのフレーバーのデプロイに役立つ多くのツールを提供します。それぞれのMLflowモデルは、任意のファイルとモデル使用できるフレーバーを一覧するMLmodelデスクリプタファイルを含むディレクトリとして保存されます。
time_created: 2018-02-21T13:21:34.12
flavors:
sklearn:
sklearn_version: 0.19.1
pickled_model: model.pkl
python_function:
loader_module: mlflow.sklearn
pickled_model: model.pkl
この例では、このモデルは、sklearnあるいはpython_functionモデルフレーバーのいずれかをサポートするツールで使用することができます。
MLflowは、さまざまなプラットフォームに数多くの一般的なモデルタイプをデプロイするためのツールを提供します。例えば、python_functionフレーバーをサポートするすべてのモデルは、DockerベースのRESTサーバー、Azure MLやAmazon SageMakerのようなクラウドプラットフォームにデプロイすることができ、バッチ推論やストリーミング推論のためにApache Sparkのユーザー定義関数としてデプロイすることもできます。Tracking APIを用いてMLflowモデルをアーティファクトとして出力した場合には、MLflowは自動でプロジェクトや実行されたランを記録します。
MLflowを使い始める
MLflowを使い始めるには、mlflow.orgの手順に従うか、Githubのアルファリリースコードをご覧ください。コンセプトやコードに関するフィードバックをお待ちしています!
DatabricksでホストされているMLflow
ホスティングされているバージョンのMLflowを実行したいのであれば、databricks.com/product/managed-mlflowにサインアップしてください。DatabricksにおけるMLflowは、ノートブック、ジョブ、Delta Lake、Databricksのセキュリティモデルを含むDatabricksレイクハウスプラットフォームとインテグレーションされており、セキュアかつプロダクションレベルの方法で既存のMLflowジョブを大規模に実行することができます。
次は?
我々はMLflowをスタートさせたばかりであり、今後も多くの機能がもたらされます。プロジェクトのアップデートだけでは無く、新たなメジャーコンポーネント(モニタリングなど)、ライブラリのインテグレーション、すでにリリースされているものに対する拡張(より多くの環境タイプのサポート)などの導入も計画しています。さらなる情報に関しては我々のブログ記事を楽しみにしていてください。
Spark+AI SummitのMLflowキーノートを見る