Infrastructure Design for Real-time Machine Learning Inference - The Databricks Blogの翻訳です。
この記事は、HeadspaceのシニアソフトウェアエンジニアであるYu Chenによるものです。
Headspaceのコア製品は、マインドフルネス、瞑想、睡眠、エクササイズ、フォーカスコンテンツを通じてユーザーの健康、幸福を改善することにフォーカスしたiOS、Android、webベースのアプリケーションです。ユーザーの生涯の旅において、一貫性のある習慣を確立するために、適切かつパーソナライズされたコンテンツをレコメンデーションすることで、ユーザーのエンゲージメントを高めるために、機械学習(ML)モデルは我々のユーザー体験におけるコアとなります。
即座に意思決定を行うためにデータを活用する場合には、MLモデルに入力されるデータは、多くのケースで最も重要となりますが、実際のところ、顧客データが取り込まれ、変換された後、機械学習と分データ分析チームが活用するまで、長い間そのままの状態で放置されています。
リアルタイムでの洞察、意思決定を行うためにユーザーデータを活用する方法を見つけることは、Headspaceのアプリのような顧客接点のある製品は、エンドツーエンドのユーザーフィードバックのループを劇的に短縮できることを意味します。直前にユーザーが実行したアクションは、ユーザーに対してより適切かつパーソナライズされ、かつ、文脈を考慮したコンテンツのレコメンデーションを実現します。
これによって、我々のモデルは、ユーザーの日々の、あるいはそれぞれのセッションを通じてアップデートされる動的な特徴量と連携できるようになります。これらの特徴量には、以下のようなものが含まれます。
- 休眠コンテンツに対する現在のセッションの離脱率
- 最近のユーザーの検索単語に対する意味のエンベッディング。例えば、ユーザーが「重要な試験に備える」と検索した場合には、その目標を達成できるように、MLモデルはフォーカスのテーマの瞑想により高い重みを割り当てます。
- ユーザーの身体データ(例:過去10分で歩数、心拍数が増加した場合には、移動、エクササイズのコンテンツをレコメンドします)
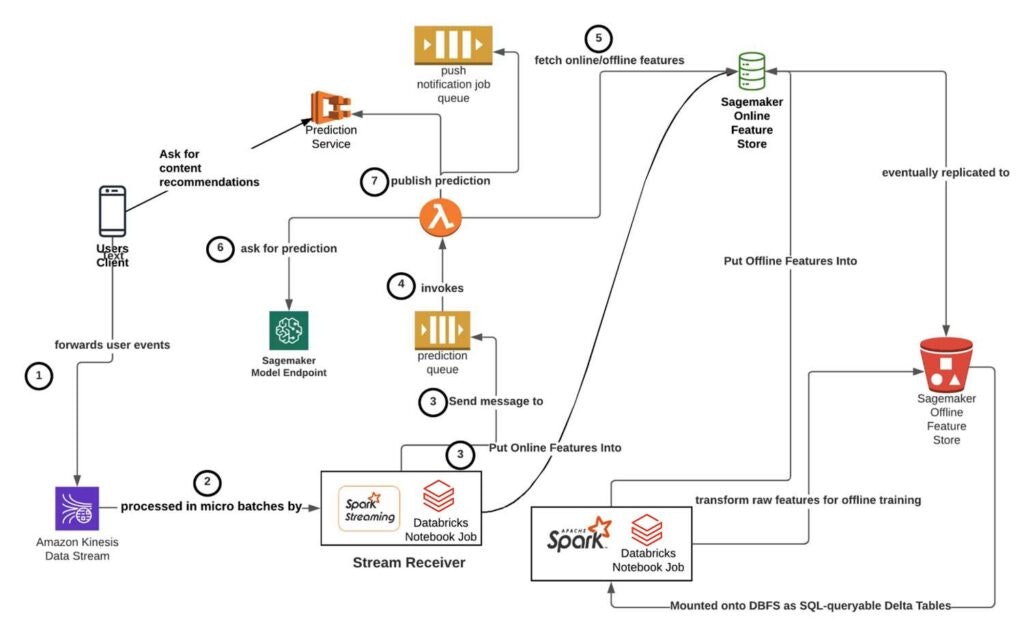
ユーザー体験を考慮して、Headspaceの機械学習チームはインフラストラクチャのシステムを、パブリッシング、レシーバー、オーケストレーション、サービングレイヤーに分解することでソリューションを設計しました。このアプローチでは、MLモデルに対するリアルタイム推論機能を提供するために、DatabricksにおけるApache Spark™の構造化ストリーミング、AWS SQS、LambdaとSageMakerを活用しました。
この記事では、我々のアーキテクチャに対する技術的ディープダイブを行います。リアルタイム推論に対する要件を説明した後で、従来型のオフラインMLワークフローを導入する際の課題を議論します。キーとなるアーキテクチャ上のコンポーネントの詳細を議論する前に、アーキテクチャの概要を説明します。
リアルタイム推論の要件
ユーザーコンテンツをパーソナライズするためのリアルタイム推論を行うためには、以下のことが必要となります。
- クライアントアプリ(iOS、Android、web)上でのユーザーの適切なイベント(アクション)に応じた取り込み、処理、転送
- リアルタイム推論モデルに用いられる特徴量セットを拡張するオンライン特徴量の高速な計算、格納、検索(m秒のレーテンシー)
- ダウンタイムを最小化(理想的には回避)しつつも、オンラインでサーブされるモデルをオンライン特徴量ストアと同期できるように、リアルタイム推論モデルのサービング及びリロード
我々のエンドツーエンドのレーテンシーの目標値(ユーザーのイベントがKinesisストリームに転送され、リアルタイムの推論予測が利用できるようになるまで)は30秒でした。
従来のMLワークフロー導入における課題
上の要件は、日次バッチで予測を行うオフラインモデルにおいては、多くのケースで解決されない(解決する必要のない)課題となります。ETL/ELTデータパイプラインから取得、変換されるレコードから推論を行うMLモデルは、通常、生データに対して数時間のリードタイムを必要とします。従来、MLモデルのトレーニング、サービングワークフローには、以下のステップが含まれており、数時間周期あるいは日次のジョブで定期的に実行されていました。
-
上流のデータストアから適切な生データの取り出し: Headspaceにおいては、我々のデータエンジニアリングチームによって維持されている上流のデータレイクにクエリーを実行するためにSpark SQLを使用しています。
- リアルタイム推論の場合: 我々は1秒あたり最大数千の予測リクエストを経験しており、バックエンドデータベースに対するSQLクエリーの使用は許容できないレーテンシーを引き起こしました。モデルのトレーニングでは完全なデータセットを取得する必要がありますが、リアルタイムの推論においては多くの場合、同じデータにおける個々のユーザーのサブセットデータのみが必要となります。このため、我々は個々のユーザー特徴量の読み書きが数m秒で行えるAWS Sagemaker Online Feature Groupsを使用しています(図のStep 3)。
- SQLとPythonを組み合わせたデータ再処理の実行(特徴量エンジニアリング、特徴量抽出など)
- リアルタイム推論の場合: 生のイベントデータのSpark Structured Streamingのマイクロバッチを、Sagemaker Feature Store Groupsからのリアルタイム特徴量で拡張します。
- モデルのトレーニング、適切なエクスペリメントのメトリクスを記録: MLflowを用いることで、Databricksノートブックのインタフェース内から、異なるエクスペリメントの実行におけるモデルおよびパフォーマンスを記録します。
- ディスクへのモデルの永続化: MLflowがモデルを記録すると、MLライブラリのネイティブフォーマットを用いてシリアライズを行います。例えば、scikit-learnのモデルはpickleライブラリを用いてシリアライズされます。
- 適切な推論データセットにおける予測の実行: この場合、我々のユーザーベースに対する新たなコンテンツのレコメンデーションを行うために、新規にトレーニングしたレコメンデーションモデルを使用します。
- **ユーザーに予測を提供するために永続化します。**これは、MLの予測結果をエンドユーザーに提供する際の、本番運用のアクセスパターンに依存します。
- リアルタイム推論の場合: ML-poweredというタブにナビゲートしたエンドユーザーが予測結果を取得できるように、予測結果を我々の予測サービスに登録します。あるいは、予測結果を別のSQLキューに転送し、コンテンツのレコメンデーションをiOS/Androidのプッシュ通知で送信します。
-
オーケストレーション: 従来型のバッチ推論モデルでは、異なるステージ・ステップをスケジュール、調整するためにAirflowのようなツールを活用します。
- リアルタイム推論の場合: 適切なメッセージングフォーマットに圧縮・解凍するために軽量なLambda関数を用い、Sagemakerエンドポイントを起動して必要となる事後処理、永続化を実行します。
- リアルタイム推論の場合: 適切なメッセージングフォーマットに圧縮・解凍するために軽量なLambda関数を用い、Sagemakerエンドポイントを起動して必要となる事後処理、永続化を実行します。
ユーザーはHeadspaceアプリ内で行うアクションによってイベントを生成し、最終的には、Spark構造化ストリーミングで処理するためにKinesisストリームに転送されます。ユーザーのアプリは、我々のバックエンドサービスに対してREST HTTPリクエストを行い、ユーザーIDとどのタイプのMLレコメンデーションを取得するのかを示す特徴量フラグを渡すことで、ニアリアルタイムの予測結果を取得します。アーキテクチャの他のコンポーネントについては、以下で詳細を説明します。
パブリッシング・サービングレイヤー:モデルトレーニング、デプロイメントのライフサイクル
MLモデルはDatabricksノートブックで開発され、MLflowエクスペリメントを通じて、レコメンデーションシステムに対する、Recall@kのような、コアのオフラインメトリクスを用いて評価されます。HeadspaceのMLチームは、MLflowにおけるPython関数モデルフレーバークラスを拡張するラッパークラスを記述しました。
参考資料
# this MLflow context manager allows experiment runs (parameters and metrics) to be tracked and easily queryable
with MLModel.mlflow.start_run() as run:
# data transformations and feature pre-processing code omitted (boiler-plate code)
...
# model construction
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
# training
lr.fit(train_x, train_y)
# evaluate the model performance
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
# Wrap the model in our custom wrapper class
model = ScikitLearnModel(lr)
model.log_params(...)
model.log_metrics(...) # record the results of the run in ML Tracking Server
# optionally save model artifacts to object store and register model (give it a semantic version)
# so it can be built into a Sagemaker-servable Docker image
model.save(register=True)
HeadspaceのMLチームのモデルラッパークラスは、MLflowモデルのDockerイメージを構築するのに必要となるメタデータ、依存関係、モデルアーティファクトを格納するMLモデルのS3バケットにディレクトリを作成し、数多くの実装ロジックを実行できるように、MLflow自身のsave_modelメソッドを呼び出します。
次に、上でS3に保存したモデルを指し示す正式なGithubリリースを作成します。これはCircleCIのようなCI/CDツールによって取り出され、MLflowモデルをテスト、ビルドし、最終的には、Sagemakerモデルエンドポイントにデプロイされるように、AWS ECRにプッシュされます。
リアルタイムモデルのアップデート、リロード
我々は頻繁にモデルの再トレーニングを行いましたが、実運用されているリアルタイム推論モデルのアップデートは厄介なものです。AWSには、実際にサービングしているSagemakerモデルをアップデートするのに活用できる、様々なデプロイメントパターン(gradual rollout、canaryなど)があります。しかし、リアルタイムモデルでは、オンライン特徴量ストアとの同期も必要となり、Headspaceのユーザーベースにおいてアップデートを完了するには30分を必要としました。モデルイメージをアップデートするたびにダウンタイムを発生させたくなかったので、モデルイメージと特徴量ストアが確実に同期するように注意深くなる必要がありました。
例えば、HeadspaceユーザーIDを協調フィルタイングモデルのユーザーシーケンスIDにマッピングするモデルを例に取ります。我々の特徴量ストアには、最も頻繁に更新されるユーザーIDとシーケンスIDのマッピングが含まれている必要があります。ユーザーの数が完全に静的であり続けない限り、モデルを更新した場合、我々のユーザーIDは推論の際に古いシーケンスIDにマッピングされ、ターゲットとしたユーザーではなく、ランダムなユーザーに対する予測を生成することになってしまいます。
ブルー・グリーンアーキテクチャ
この問題に取り組むため、DevOpsのブルー・グリーンデプロイメントのプラクティスに倣ったブルー・グリーンアーキテクチャを導入しました。ワークフローは以下のようになります。
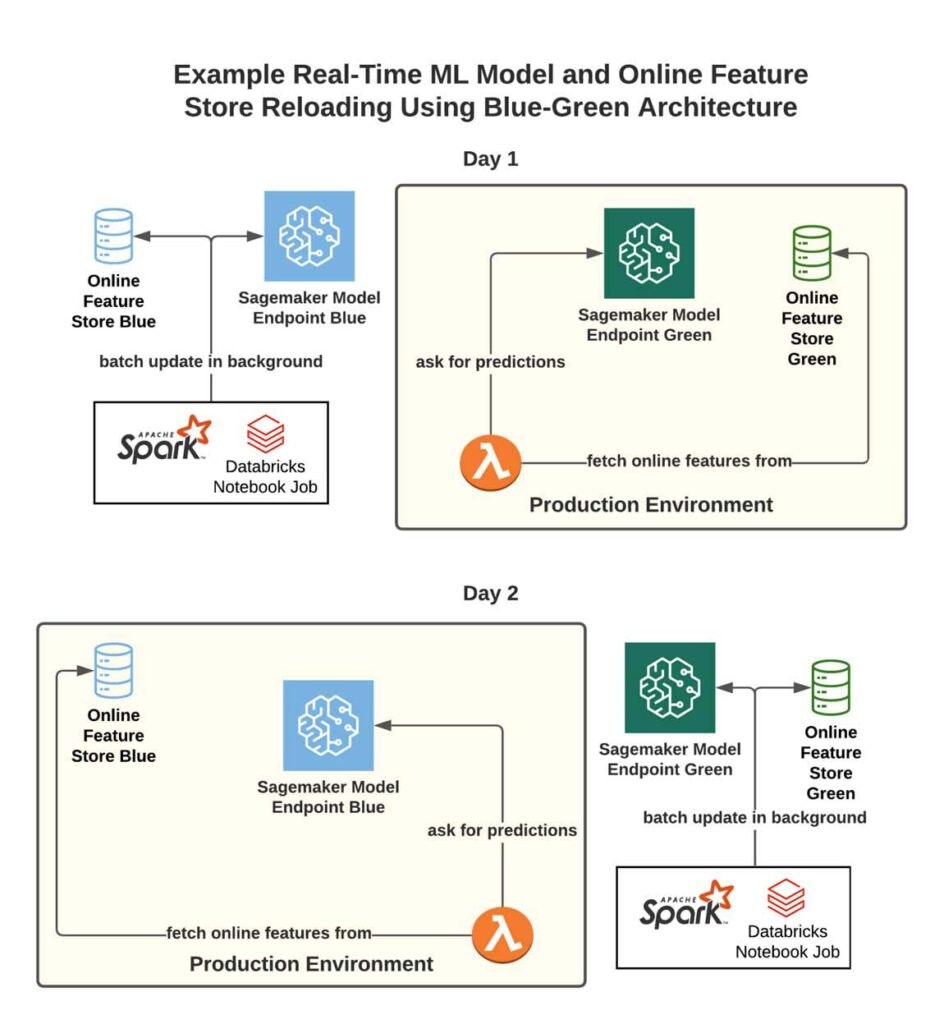
- 2つの並列のインフラストラクチャを維持します(この場合は、2つの特徴量ストアのコピー)。
- 一方をプロダクション環境に指定し、Lambdaを経由して特徴量と予測のリクエストをこちらにルーティングします。
- モデルのアップデートを行うシアには、補助用のインフラストラクチャ(「ブルー」環境)をアップデートするためのバッチプロセス/スクリプトを使用します。アップデートが完了したら、特徴量・予測のLambdaがブループロダクション環境をポイントするように切り替えます。
- モデル(および対応する特徴領ストア)をアップデートするたびにこれを繰り返します。
レシーバーレイヤー:Apache Sparkの構造化ストリーミングスケジュールジョブによるイベントストリームの取り込み
Headspaceのユーザーイベントアクション(アプリへのログイン、特定のコンテンツの再生、サブスクリプションの更新、コンテンツの検索など)は、集約されてKinesisデータストリームに転送されます(図のStep 1)。Kinesisストリームからのデータを処理するために、DatabricksじのSpark構造化ストリーミングフレームワークを活用しました。構造化ストリーミングには以下のようなメリットがあります。
- データサイエンティスト、データエンジニア、アナリストで共有可能な**統合された言語(Python/Scala)、フレームワーク(Apache Spark)**を活用できるので、複数のHeadspaceチームで、慣れ親しんだデータセット・データフレームAPIと抽象化を用いてユーザーデータを取り扱うことができます。
- 我々のチームがビジネス要件を満たすためにカスタムのマイクロバッチロジックを実装することができます。例えば、ユーザーごとにカスタムのイベントタイムウィンドウやセッションのウォーターマークロジックに基づくマイクロバッチを定義し実行することができます。
- MLエンジニアにとって重荷となっている、インフラストラクチャの管理工数を劇的に削減できるDatabricksのインフラストラクチャツールを活用できます。これらのツールには、ジョブのスケジュール、自動リトライ、効率的なDBUクレジットプライシング、イベント失敗を知らせるメール通知、ビルトインのSparkストリーミングダッシュボード、そして、ユーザーアプリのイベントアクティビティに応じて迅速にオートスケールする機能が含まれます。
構造化ストリーミングは、連続的なイベントストリームをそれぞれのチャンクに分割し、到着し続けるイベントを小さなマイクロバッチデータフレームとして処理するためにマイクロバッチを使用しています。
ストリーミングデータパイプラインは、イベント時間(クライアントデバイスで実際にイベントが発生した時間)と処理時間(データがサーバーに到着した時間)を区別する必要があります。ネットワーク分断、クライアント側のバッファリング、他のホストの問題などが、これらの時間に関して無視できない不一致を引き起こします。構造化ストリーミングAPIでは、シンプルなロジックのカスタマイゼーションによって、これらの不一致をハンドリングすることができます。
df.withWatermark("eventTime", "10 minutes") \
.groupBy(
"userId",
window("eventTime", "10 minutes", "5 minutes"))
以下のパラメーターを用いて構造化ストリーミングジョブを設定しました。
- 最大同時実行数は1
- 無制限のリトライ
- 新規スケジュールジョブクラスター(All-Purposeクラスターではありません)
スケジュールジョブクラスターを活用することで、関係するインフラストラクチャの障害発生確率を削減しつつも、DBUコストを劇的に引き下げることができました。障害のあるクラスターでジョブがスタートした場合、これには依存関係、インスタンスプロファイルの設定ミス、アベイラビリティゾーンのキャパシティ不足などが考えられますが、背後のクラスターの問題が解決するまでこのジョブは失敗しますが、別のクラスターのジョブは干渉を避けることができます。
次に、クライアント側のユーザーイベントを集約するように設定されたAmazon Kinesisストリームから読み込みを行うようにストリームクエリーをポイントします(図のStep 2)。以下のようなロジックでストリームクエリーが設定されます。
processor = RealTimeInferenceProcessor()
query = df.writeStream \
.option("checkpointLocation", "dbfs://pathToYourCheckpoint") \
.foreachBatch(processor.process_batch) \
.outputMode("append") \
.start()
ここで、outputModeはストリーミングのシンクに対してどのように書込みを行うのかのポリシーを定義し、3つの値append、complete、updateを指定することができます。我々の構造化ストリーミングジョブは到着するイベントのハンドリングですので、「新規」レコードのみを処理するようにappendを選択しました。
失敗したストリーミングクエリーをgracefulに再開できるようにチェックポイントを設定することは良いアイデアです。これによって、失敗あの直後から処理を「再生」することができます。
ビジネスユースケースに応じて、ASAPでそれぞれのマイクロバッチをスタートするように*processingTime = "0 seconds"*を設定することで、レーテンシーを削減する選択も可能です。
query = df.writeStream \
.option("checkpointLocation", "dbfs://pathToYourCheckpoint") \
.foreachBatch(process_batch) \
.outputMode("append") \
.trigger(processingTime = "0 seconds") \
.start()
さらに、我々のSpark構造化ストリーミングジョブクラスターには、Sagemaker Feature Groupsとやりとりを行い、予測ジョブのSQSキューにメッセージを送信できるように適切なIAMポリシーが設定された特別なEC2インスタンスプロファイルが設定されています。
最終的には、それぞれの構造化ストリーミングジョブには異なるビジネスロジックを組み込む必要があるので、マイクロバッチごとに起動される異なるマイクロバッチ処理関数を実装する必要がありました。
我々のケースでは、最初にAWS Sagemaker Feature Storeでオンラン特徴量を計算・更新するprocess_batchを実装し、ユーザーイベントをジョブキューに転送しました(Step 3)。
from pyspark.sql.dataframe import DataFrame as SparkFrame
class RealTimeInferenceProcessor(Processor):
def __init__(self):
self.feature_store = initialize_feature_store()
def process_batch(self, df: SparkFrame, epochID: str) -> None:
"""
Concrete implementation of the stream query’s micro batch processing logic.
Args:
df (SparkFrame): The micro-batch Spark DataFrame to process.
epochID (str): An identifier for the batch.
"""
compute_online_features(df, self.feature_store)
forward_micro_batch_to_job_queue(df)
オーケストレーションレイヤー:イベントキューと特徴量トランスフォーマーとしてのLambdaの分離
Headspaceのユーザーは、我々のリアルタイム推論モデルが最新のレコメンデーションを生成するために処理するイベントを生成します。しかし、ユーザーイベントアクティビティのボリュームは均等に分布していません。数多くの増減があり、我々のユーザーは特定の時間帯に最もアクティブになります。
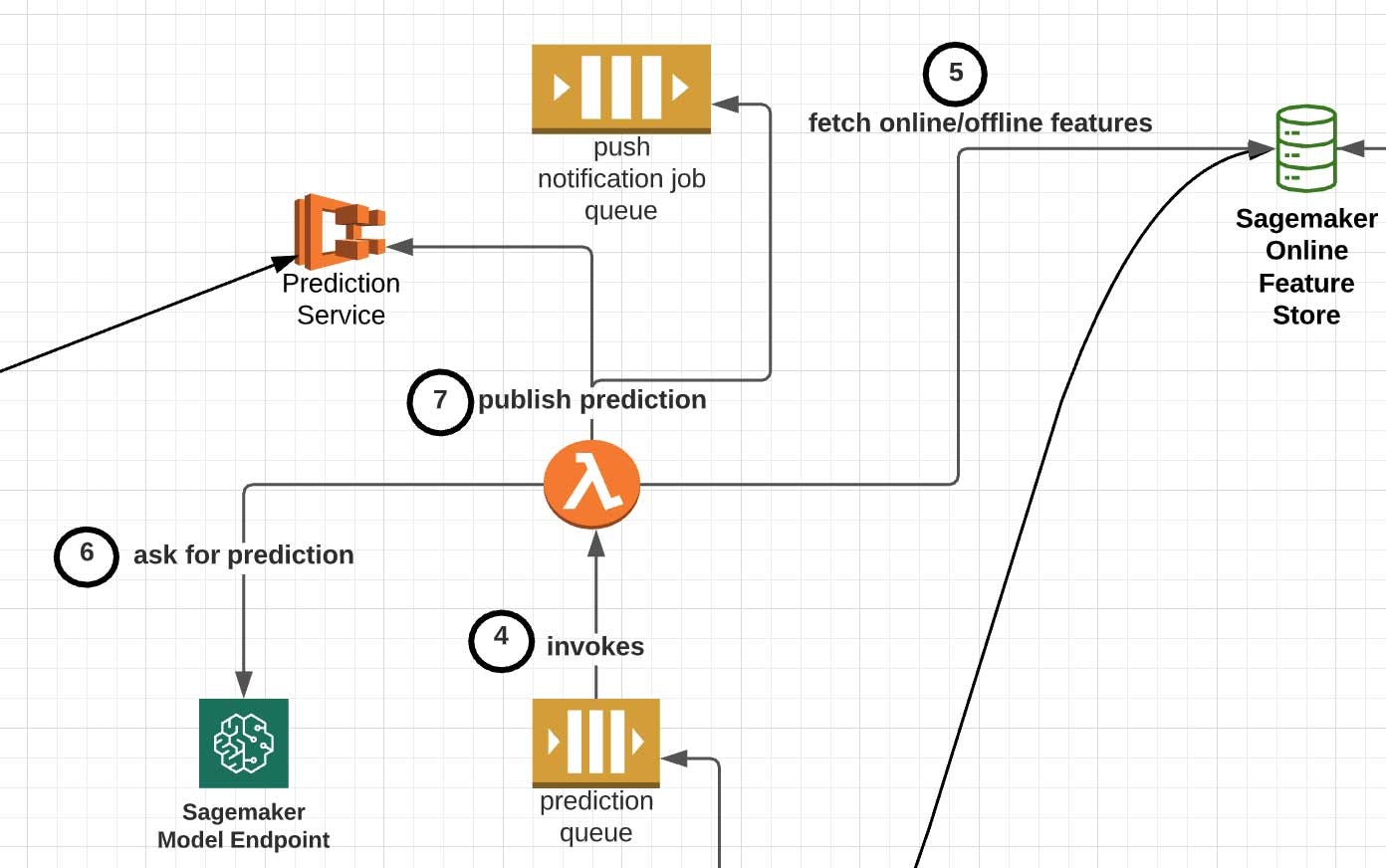
SQL予測ジョブキューに投入されたメッセージは、以下の処理を行うAWS Lambda関数(図のStep 4)で処理されます。
- メッセージを解凍し、レコメンデーションの対象となるユーザーに関するオンライン・オフライン特徴量を取得します(図のStep 5)。例えば、ユーザーの利用期間、性別、言語などの属性でイベントの時系列・セッションベースの特徴量を拡張する場合があります。
- 最終の前処理ビジネスロジックを適用します。協調フィルタリングモデルで活用できるHeadspaceユーザーIDからユーザーシーケンスIDへのマッピングなどが挙げられます。
- Sagemakerでサーブされる適切なモデルを選択し、入力特徴量を与えて起動します(図のStep 6)。
- 下流の目的地にレコメンデーションを転送します(図のStep 7)。実際の位置は、ユーザーにレコメンデーションコンテンツをプルダウンしてもらうのか、ユーザーにプッシュでレコメンデーションするのかに依存します。
プル: この方法には、クライアントのアプリのリクエストに基づき、Headspaceアプリの数多くのタブに最新のパーソナライズされたコンテンツを提供することに責任を持つ、内部の予測サービスへの最終的なレコメンデーションコンテンツの永続化が含まれます。以下に、アプリの「Today」タブにパーソナライズされたレコメンデーションをユーザーに提供する、リアルタイム推論インフラストラクチャの実験の例を示します。

プッシュ: この方法には、プッシュ通知、あるいは、アプリ内のモーダル上のプッシュレコメンデーションのために別のSQSキューへのレコメンデーションの送信が含まれます。例として以下の画像をご覧ください。上はユーザーによる睡眠コンテンツに対する最近の検索によってトリガーされるアプリ内モーダルプッシュレコメンデーションであり、下は最近ユーザーが完了したコンテンツに基づくiOSのプッシュ通知です。
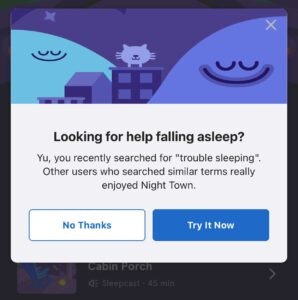

特定の瞑想を完了するか、検索を行った数分のうちに、ユーザーに対するコンテキストを最優先としつつも、適切な次のコンテンツを提供するためにこれらのプッシュ通知が行われます。
さらに、イベントキューを活用することで、予測ジョブのリクエストを再トライすることができます。予測ジョブが特定期間で完了しなかった場合に、リトライのために別のLambda関数が起動されるように、SQSキューに対して小規模のタイムアウトウィンドウ(10-15秒)を設定することができます。
まとめ
インフラストラクチャ、アーキテクチャの観点から、異なるサービス間で柔軟に引き渡しを行えるポイントを設計することに優先度を置くということが主な学びとなりました。我々の場合、パブリッシング、レシーバー、オーケストレータ、そしてサービングレイヤーとなります。例えば、
- 我々の構造化ストリームジョブが予測SQSキューに送信する際のメッセージペイロードにはどのようなフォーマットを使うべきか?
- それぞれのSagemakerモデルが期待するモデルのシグネチャとHTTP POSTペイロードはどのようなものであるべきか?
- 本番環境で安全かつ信頼性高く再トレーニングしたモデルを更新できるように、どのようにモデルイメージとオンライン特徴量ストアを同期すべきか?
これらの疑問に積極的に取り組むことで、複雑のMLアーキテクチャの様々なコンポーネントを、小規模かつモジュール化されたインフラストラクチャのセットに分離することができました。
HeadspaceのMLチームは、今でもこのインフラストラクチャでプロダクションユースケースをロールアウトし続けていますが、初期のA/Bテストと実験によって、他のHeadspaceの取り組みや業界ベンチマークと比較して、コンテンツのスタート率、コンテンツの完了率、直接/合計のプッシュ開封率に大きな改善が認められました。
リアルタイム推論の能力を持つモデルを活用することで、Heaspaceはユーザーのアクションからパーソナライズされたコンテンツレコメンデーションに要するリードタイムを劇的に削減することができました。現在のセッション内での、最近の検索、コンテンツの開始・離脱・一時停止、アプリ内のナビゲーション、バイオメトリクスデータのようなイベントストリームは、ユーザーがHeadspaceアプリを操作している間であっても、ユーザーに対して最新のレコメンデーションを継続的に提供することができます。
Databricksにおける機械学習に関して知りたいのでしたら、Data+AI Summit 2021のキーノートで説明されている概要をご覧ください。また、Databricksにおける機械学習のホームページにあるリソースを参照ください。
Headspaceに関しては、www.headspace.comをご覧ください。