こちらのノートブックギャラリーのGet started with logging for ML projects with MLflowをウォークスルーした内容です。DatabricksではMLflowがマネージドサービスとして提供されているので、お手軽に機械学習モデルを管理することができます。
ノートブックの翻訳版はこちらになります。
イントロダクション
このノートブックでは、MLflowラン(MLflowにおけるトレーニングの単位)をスタートし、モデル、モデルのパラメーター、評価メトリクス、その他のランのアーティファクトを記録するために、どのようにMLflow logging APIを使うのかを説明します。PythonでMLflowトラッキングを使い始める最も簡単な方法は、MLflowのautolog() APIを使うことです。それぞれのトレーニングランにおいて記録するメトリクスを制御したい、あるいは、テーブルやプロットの様な追加のアーティファクトを記録したい場合には、このノートブックで説明されている様にmlflow.log_metric()やmlflow.log_artifact() APIを使うことができます。
セットアップ
- Databricksランタイムを使っている場合には、PyPIからmlflowライブラリをインストールする必要があります。Cmd 3をご覧ください。
- Databricks機械学習ランタイムを使っている場合は、mlflowライブラリは既にインスオールされています。
このノートブックでは、シンプルなデータセットに対してランダムフォレストモデルを作成し、モデルと選択したモデルパラメーターとメトリクスを記録するためにMLflowトラッキングAPIを使用します。
ライブラリのインストール
mlflowライブラリをインストールします。
これはDatabricksクラスターを使っている場合にのみ必要となります。クラスターでDatabricks機械学習ランタイムが稼働している場合には、Cmd 4までスキップしてください。
# If you are running Databricks Runtime version 7.1 or above, uncomment this line and run this cell:
#%pip install mlflow
# If you are running Databricks Runtime version 6.4 to 7.0, uncomment this line and run this cell:
#dbutils.library.installPyPI("mlflow")
ライブラリのインポート
必要なライブラリをインポートします。
import mlflow
import mlflow.sklearn
import pandas as pd
import matplotlib.pyplot as plt
from numpy import savetxt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
データセットの準備
scikit-learnからデータセットをインポートし、トレーニングデータセット、テストデータセットを作成します。
db = load_diabetes()
X = db.data
y = db.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
モデルのトレーニングおよび記録
ランダムフォレストモデルを作成し、mlflow.log_param()、mlflow.log_metric()、mlflow.log_model()、mlflow.log_artifact()を用いて、モデル、モデルのパラメーター、評価メトリクス、その他のアーティファクトを記録します。これらの機能によって、どのパラメーター、メトリクスを記録するのかを正確に制御することができ、テーブルやプロットの様なランの他のアーティファクトを記録することもできます。
with mlflow.start_run():
# モデルのパラメーターを設定します
n_estimators = 100
max_depth = 6
max_features = 3
# モデルを作成し、トレーニングします
rf = RandomForestRegressor(n_estimators = n_estimators, max_depth = max_depth, max_features = max_features)
rf.fit(X_train, y_train)
# テストデータセットに対して予測を行うためにモデルを使用します
predictions = rf.predict(X_test)
# このランで使用されたモデルのパラメーターを記録します
mlflow.log_param("num_trees", n_estimators)
mlflow.log_param("maxdepth", max_depth)
mlflow.log_param("max_feat", max_features)
# モデルの評価に使用するメトリックを定義します
mse = mean_squared_error(y_test, predictions)
# このランのメトリックの値を記録します
mlflow.log_metric("mse", mse)
# このランで作成されたモデルを記録します
mlflow.sklearn.log_model(rf, "random-forest-model")
# 予測値のテーブルを保存します
savetxt('predictions.csv', predictions, delimiter=',')
# 保存したテーブルをアーティファクトとして記録します
mlflow.log_artifact("predictions.csv")
# グラフィック機能を活用できる様に残差(residual)をpandasデータフレームに変換します
df = pd.DataFrame(data = predictions - y_test)
# 残差のプロットを作成します
fig, ax = plt.subplots()
ax.plot(df)
plt.xlabel("Observation")
plt.ylabel("Residual")
plt.title("Residuals")
# プロットを図として記録します
plt.savefig("residuals_plot.png")
mlflow.log_figure(fig, "residuals_plot.png")
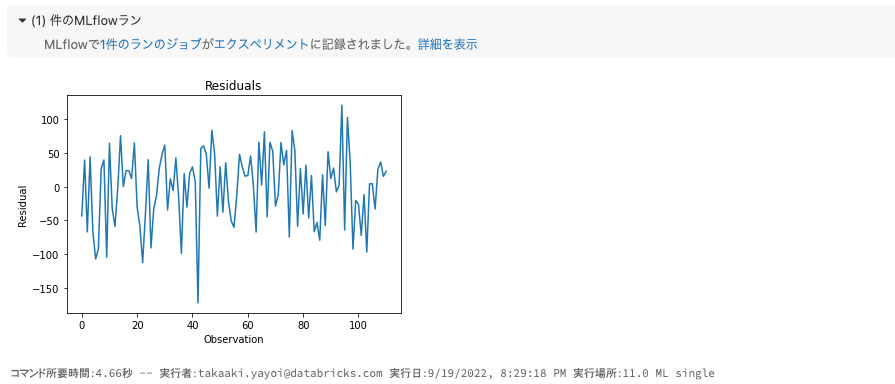
結果の確認
結果を見るには、このページの右上のエクスペリメントをクリックします。

エクスペリメントサイドバーが表示されます。このサイドバーには、このノートブックのそれぞれのランのパラメーターとメトリクスが表示されます。最新のランを表示させるには、表示をリフレッシュする回転矢印アイコンをクリックします。
ランの日時の右側にある矢印付き四角アイコンをクリックすると、新規タブでランページが開きます。
このページでは、ランから記録されたすべての情報が表示されます。
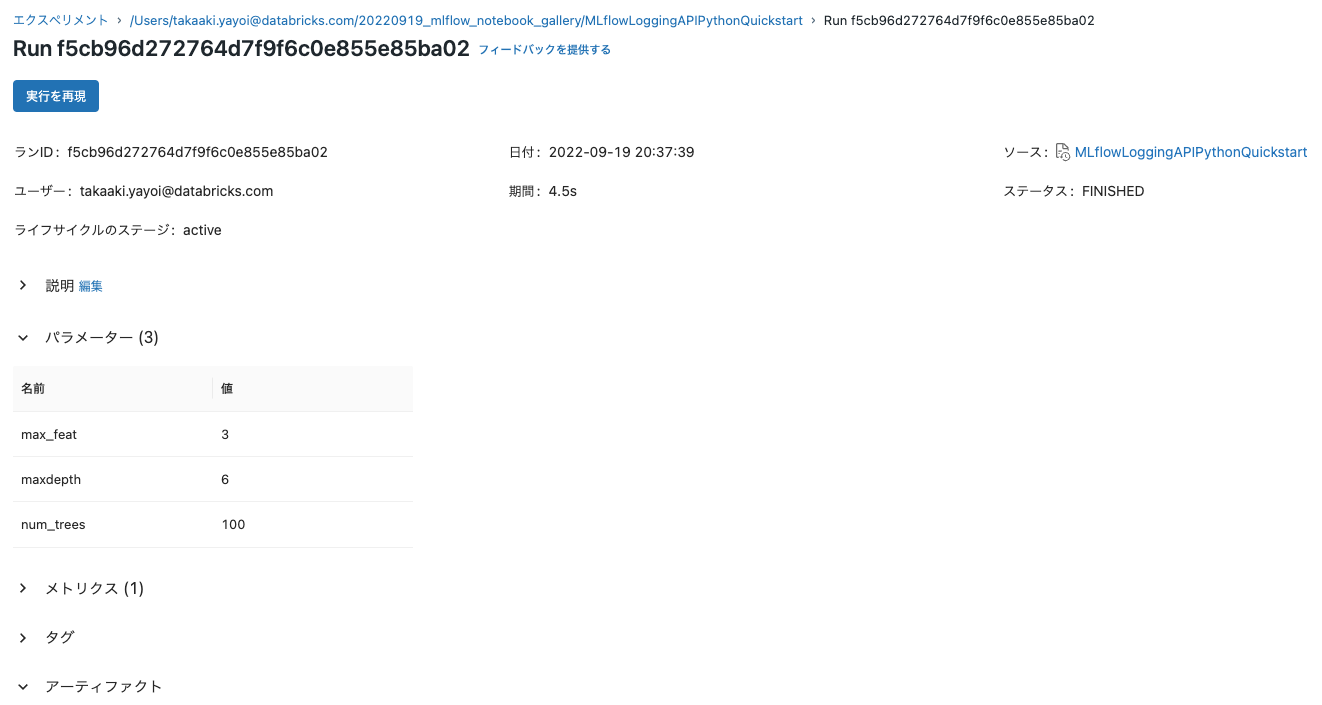
記録されたモデル、テーブルやプロットを参照するには、アーティファクトのセクションまで下にスクロールします。

オートロギング
ランダムフォレストモデルを作成し、今度はmlflow.sklearn.autolog()を用いて、パラメーター、メトリクス、モデル自身を記録します。
# 一般的な autolog() を有効化します
# mlflow.autolog() を使用するには mlflow 1.12.0 以降が必要です
mlflow.autolog()
# autolog() が有効化されるとすべてのモデルパラメーター、モデルのスコア、フィッティングされたモデルが自動で記録されます
with mlflow.start_run():
# モデルパラメーターを設定します
n_estimators = 100
max_depth = 6
max_features = 3
# モデルを作成し、トレーニングします
rf = RandomForestRegressor(n_estimators = n_estimators, max_depth = max_depth, max_features = max_features)
rf.fit(X_train, y_train)
# テストデータセットに対して予測を行うためにモデルを使います
predictions = rf.predict(X_test)
オートロギングを活用すると、細かい指定なしに必要な情報を記録することができます。カスタマイズが必要であれば上述のAPIを使う形となります。
