Announcing Public Preview of Volumes in Databricks Unity Catalog | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2023/7/13の記事です。
任意の非テーブルデータを発見、制御、クエリー
Data & AIサミット2023で、Databricks Unity Catalogにおけるボリュームをご紹介しました。この機能によって、ユーザーはUnity Catalogのテーブルデータに加え、構造化データ、半構造化データ、構造化データを含むいかなる非テーブルデータを発見、制御、処理、リネージの追跡が可能となります。本日、AWS、Azure、GCPで利用できるボリュームのパブリックプレビューを発表できることを嬉しく思っています。
本記事では、非テーブルデータに関連する一般的なユースケースを議論し、Unity Catalogのボリュームの主要な機能を説明し、ボリュームの実践的なアプリケーションをデモンストレーションする実際に動作するサンプルをお見せし、ボリュームを使い始める方法の詳細を説明します。
非テーブルデータのガバナンス、アクセスに関する一般的なユースケース
Databricksレイクハウスプラットフォームでは、さまざまなフォーマットの大量のデータを格納、処理することができます。このようなデータの多くはテーブルとして管理されますが、特に機械学習やデータサイエンスワークロードにおいては、テキスト、画像、音声、動画、PDF、XMLファイルのような非テーブルデータへのアクセスを必要とするユースケースが多数存在します。
我々のお客様から聞いた一般的なユースケースには以下のようなものがあります:
- 画像、音声、動画、PDFファイルのような非構造化データの大コボなコレクションに対する機械学習の実行。
- モデルのトレーニングに使用されるトレーニング、テスト、検証データセットの永続化や共有、ログやチェックポイントのディレクトリのようなオペレーションデータのロケーションの定義。
- データサイエンスにおけるデータ探索ステージでの非テーブルデータファイルのアップロードとクエリー。
- ネイティブにクラウドオブジェクトストレージAPIをサポートせず、クラスターマシンのローカルファイルシステムにファイルが存在することを前提とするツールの操作。
- クラスターライブラリ、ノートブックスコープライブラリ、ジョブの依存関係の設定の前に、.whlや.txtのような任意のフォーマットのライブラリ、証明書、設定ファイルのワークスペース横断での格納、セキュリティ保護。
- Auto LoaderやCOPY INTOを用いるなどしてテーブルにロードされる前の取り込みパイプラインの初期ステージにおける生データファイルのステージングや前処理。
- ワークスペース、リージョン、クラウド、データプラットフォームの内外での他のユーザーとの大規模ファイルコレクションの共有。
ボリュームを用いることで、フォーマットに関係なしに非テーブルデータの大規模コレクションをクラウドストレージのパフォーマンスで読み込み、処理できるスケーラブルなファイルベースのアプリケーションを構築することができます。
ボリュームとは何?どのように使うのか?
ボリュームは、Unity Catalogにおいてディレクトリやファイルのコレクションをカタログ化する新たなタイプのオブジェクトです。ボリュームは、クラウドオブジェクトストレージにおけるストレージの論理的なボリュームを表現し、構造化、半構造化、非構造化データを含む任意のフォーマットのデータへのアクセス、格納、管理する機能を提供します。これによって、Unity Catalogでテーブルデータやモデルとともに非テーブルデータの制御、管理、リネージ追跡が可能となり、統合された発見、ガバナンス体験を提供します。
ボリュームに格納されている画像データセットに対する画像分類の実行
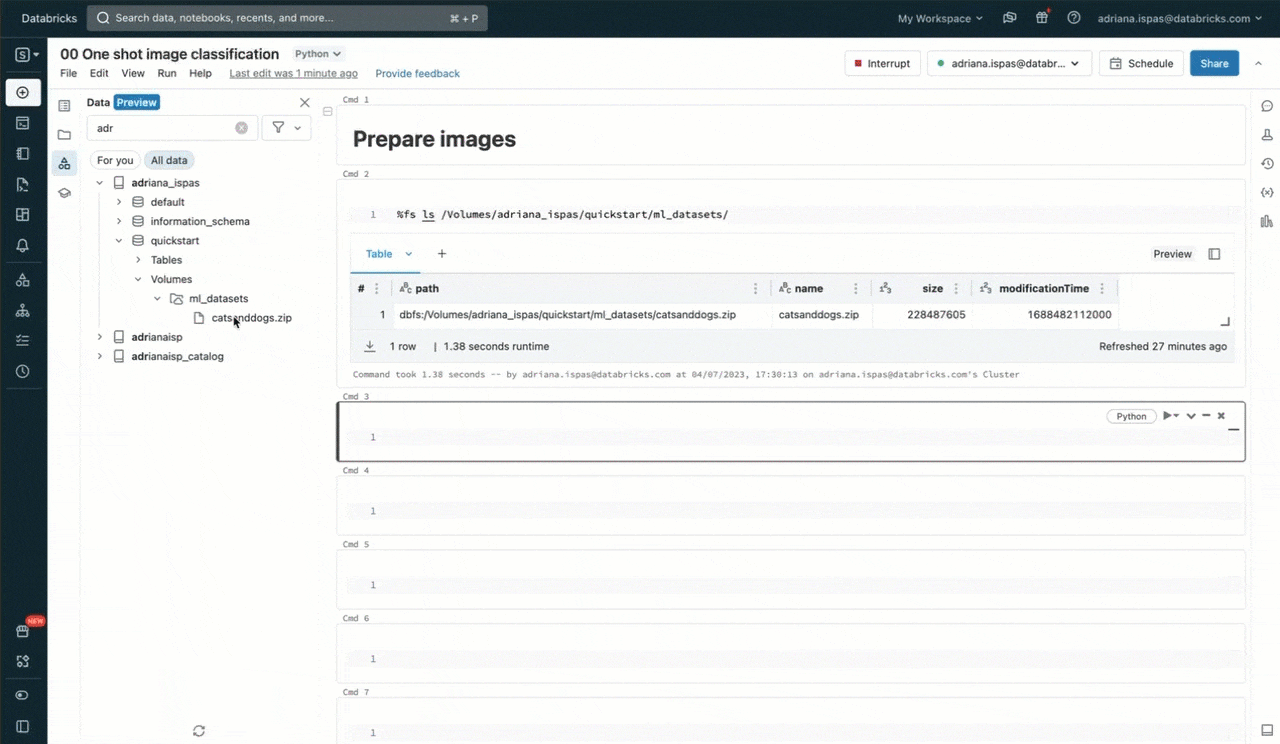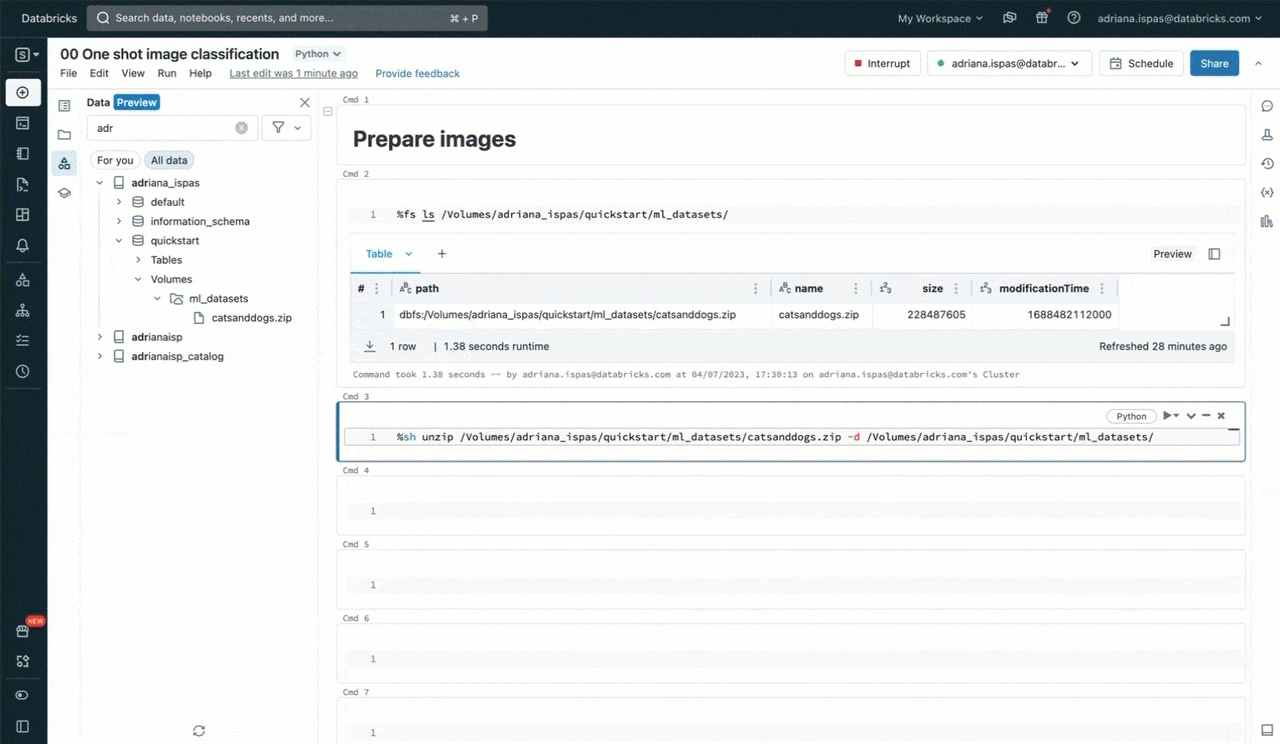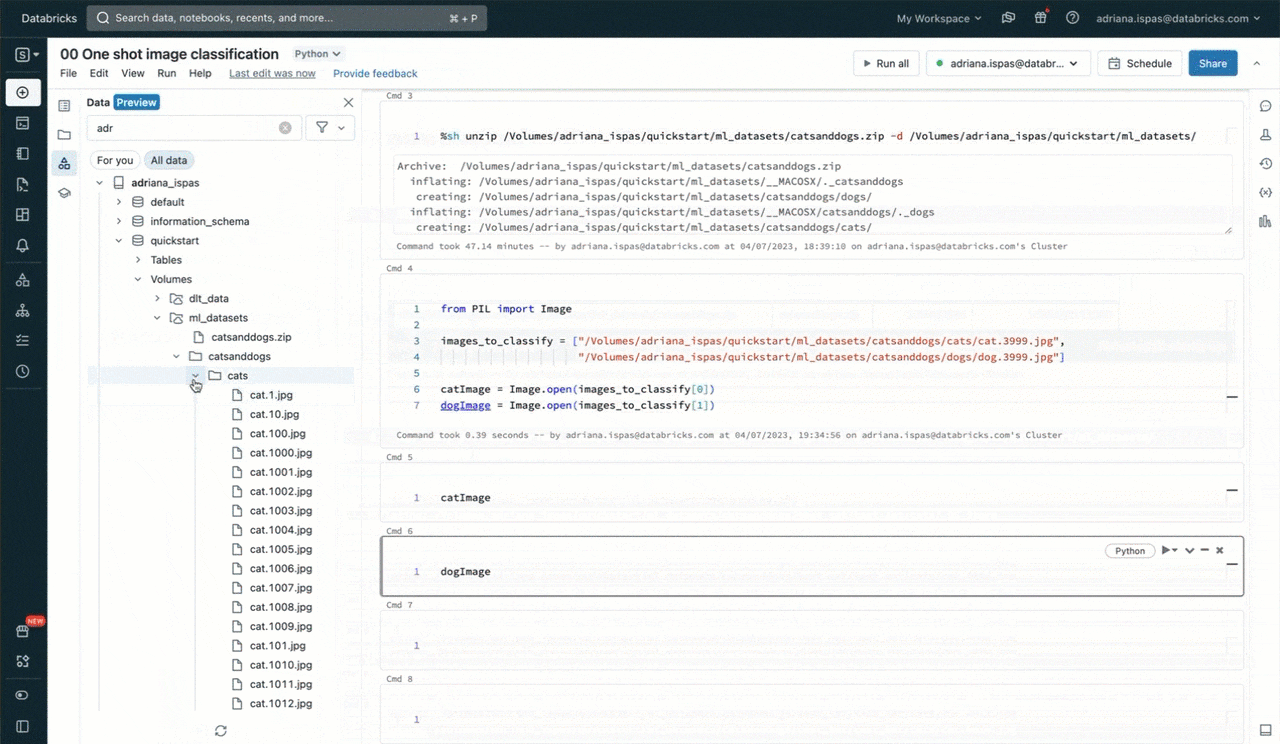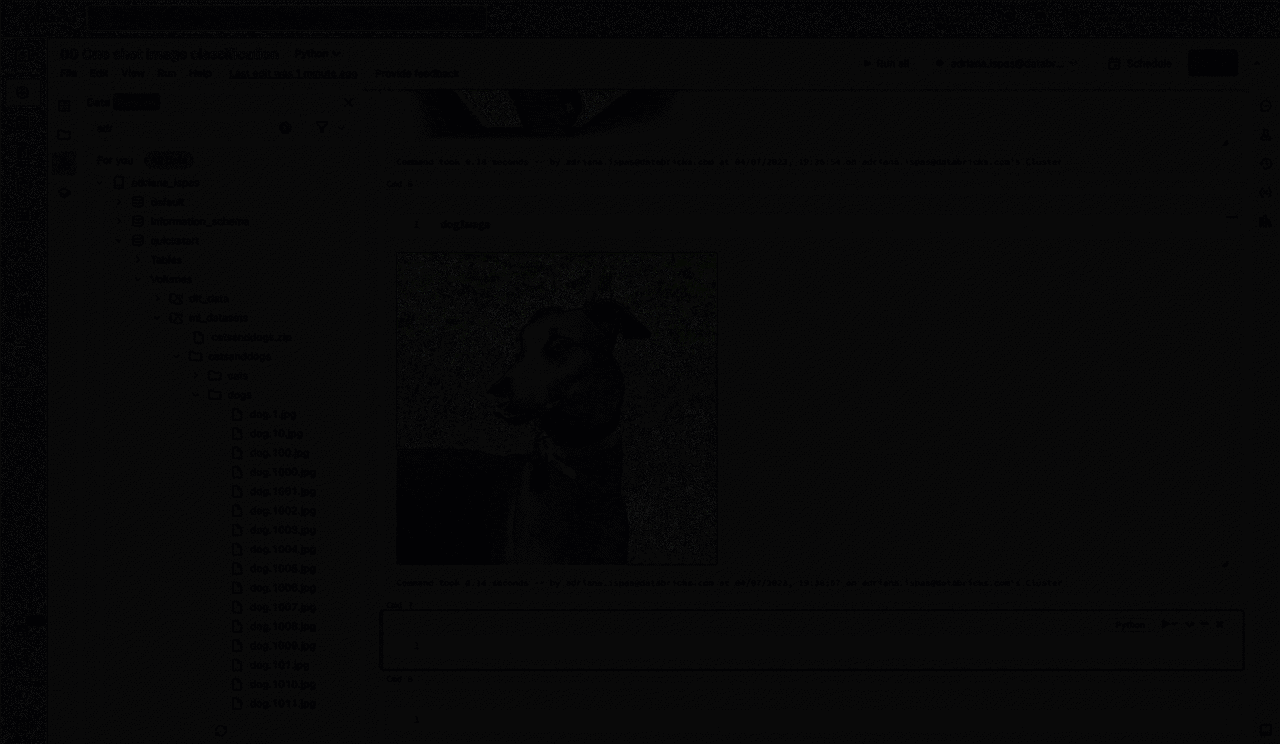
ボリュームと実際のアプリケーションをさらに理解するために、サンプルを見ていきましょう。猫と犬の画像から構成されるデータセットを用いた画像分類のために機械学習(ML)を活用したいものとします。最初のステップは、ローカルマシンにこれらの画像をダウンロードすることになります。我々の目的は、データサイエンスの用途でDatabricksにこれらの画像を取り込むことです。
これを達成するには、データエクスプローラ(現カタログエクスプローラ)のUIを活用します。Unity Catalogのスキーマに新規ボリュームを作成することで、自分自身がオーナーになります。その後で、これぼレーションする相手にアクセス権を許可し、画像ファイルを含むアーカイブをアップロードします。書き込み権限を持っている既存のボリュームにファイルをアップロードする選択肢もあることを付け加えておきます。あるいは、ノートブックやSQLエディタで、SQLコマンドを用いて自分のボリュームを作成し、権限を管理することができます。
CREATE VOLUME my_catalog.my_schema.my_volume;
GRANT READ VOLUME, WRITE VOLUME
ON VOLUME my_volume
TO `user group`;
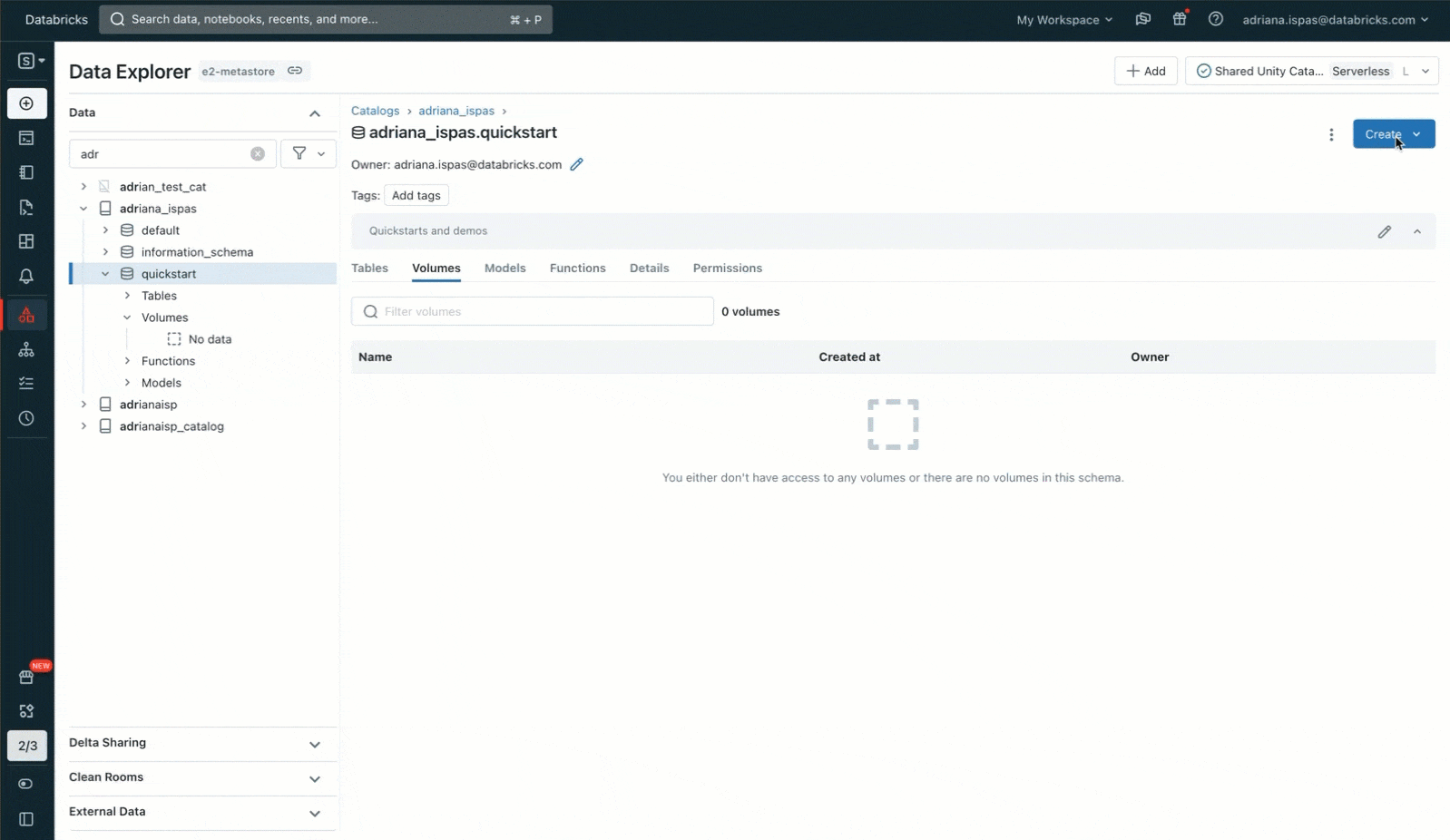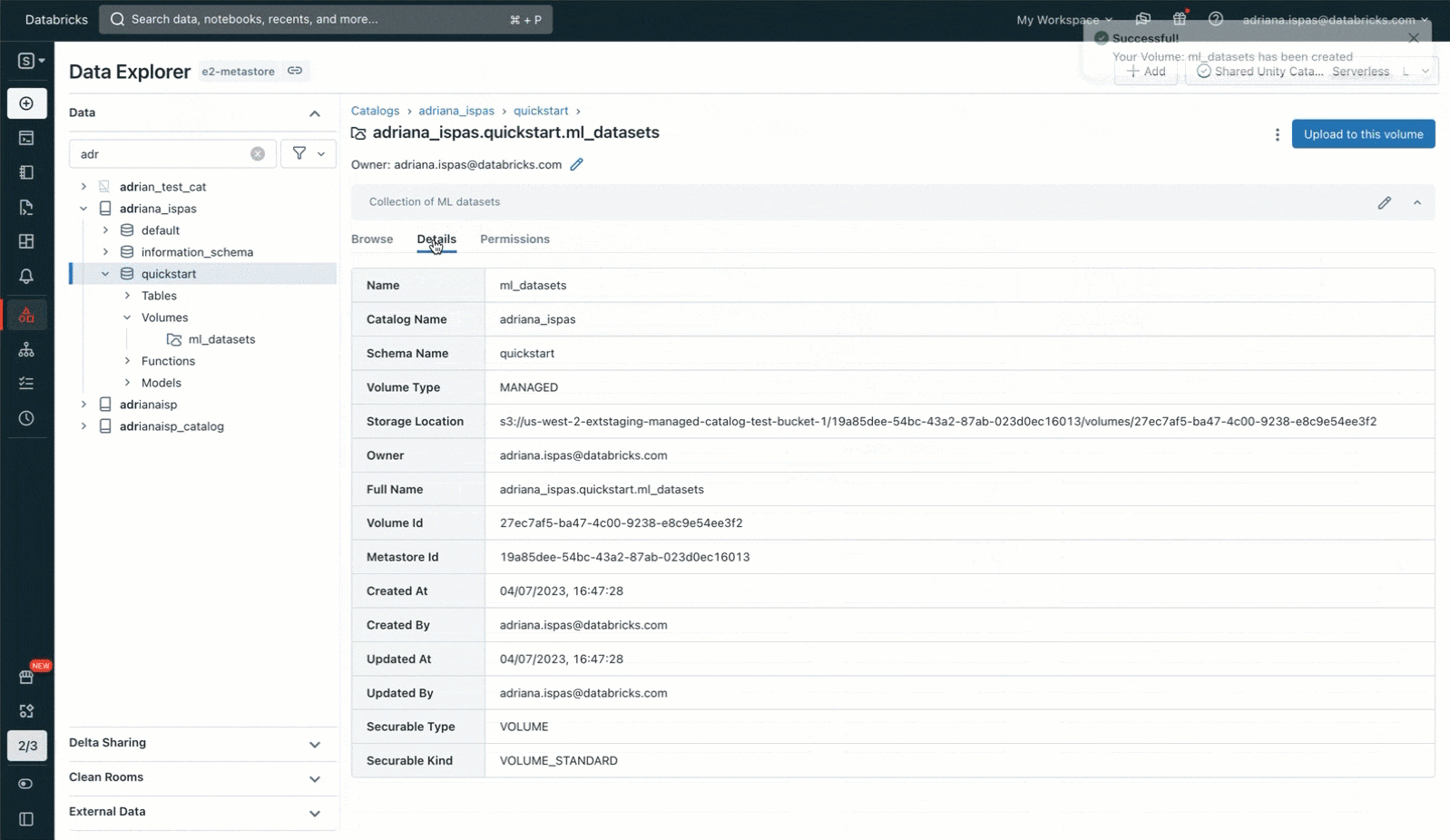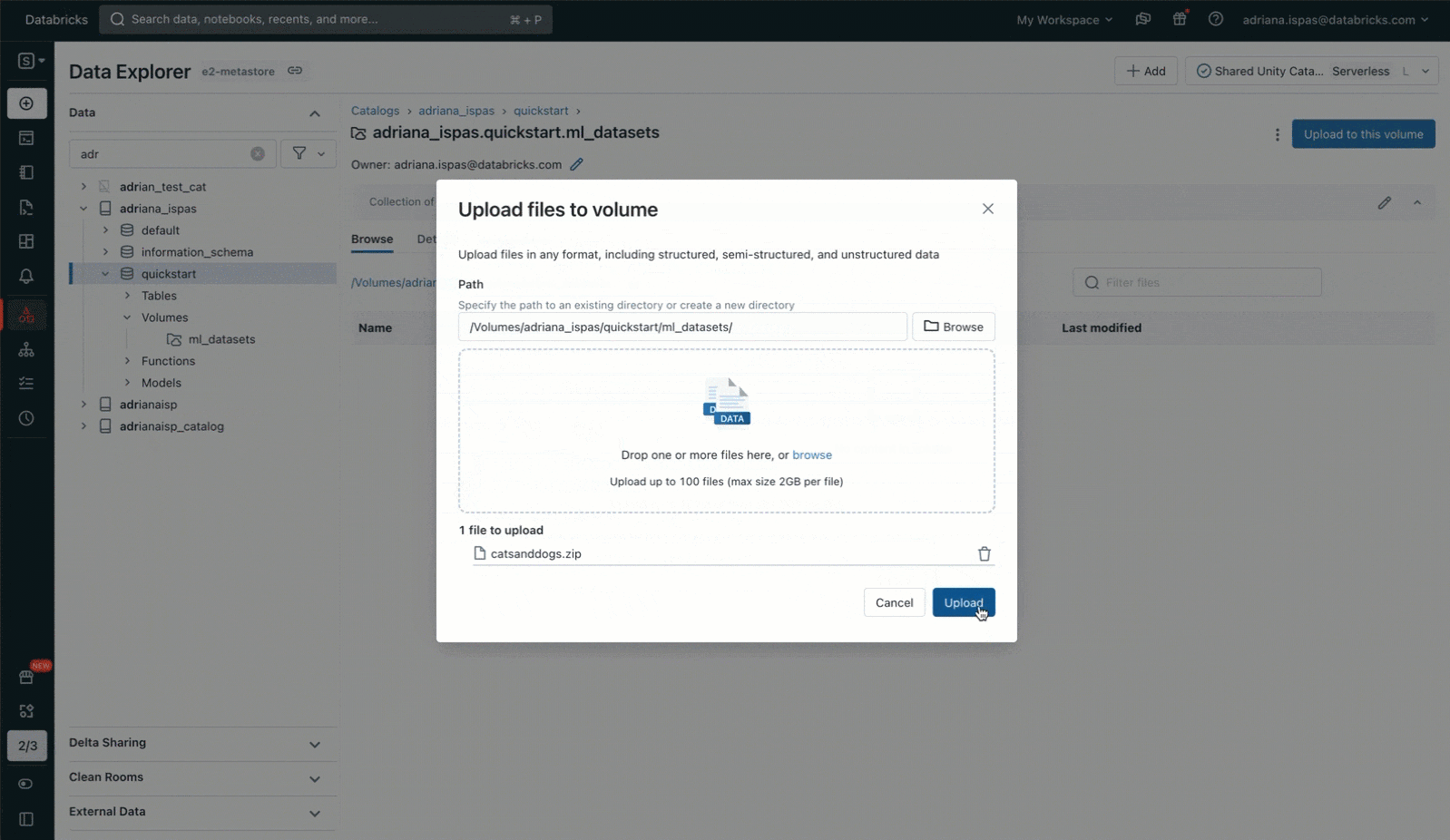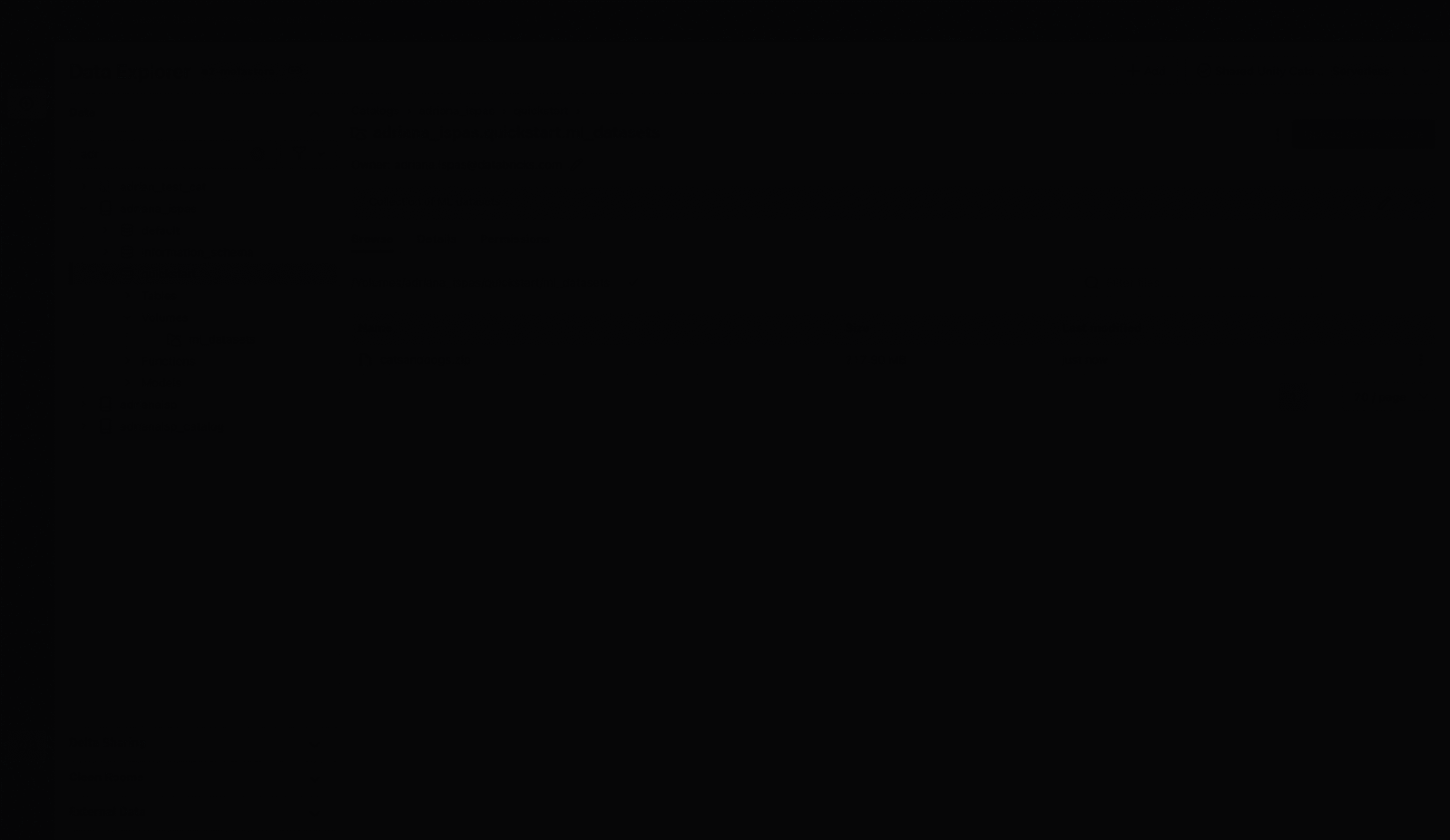
これによって、よく使われるunzipユーティリティを用いて画像アーカイブの抽出に進むことができます。コマンドにボリュームに対応するパスを含めていることに注意してください。このパスは、Unity Catalogリソースの階層構造に対応しており、Unity Catalogで定義されているアクセス権に従います。
%sh unzip /Volumes/my_catalog/my_schema/my_volume/catsanddogs.zip -d
/Volumes/my_catalog/my_schema/my_volume/catsanddogs/
このコマンドを実行するには、サイドバーを通じてボリュームのコンテンツに簡単にアクセスできるノートブックを使用することができます。さらに、ファイルの一覧や画像の表示のようにファイルに関連するコマンドをタイプするプロセスを簡単にするために「パスのコピー」機能を活用することができます。
from PIL import Image
image_to_classify = "/Volumes/my_catalog/my_schema/my_volume/catsanddogs/cat3999.jpg"
image = Image.open(image_to_classify)
display(image)
以下のスクリーンショットでは、完全なインタラクションの流れを示しています。
事前に定義されたリストのラベルを用いて画像を分類するために、Unity CatalogのMLflowモデルレジストリに事前に登録されているゼロショット画像分類モデルを活用します。以下のコードスニペットでは、どのようにモデルをロードし、分類を行い、判定結果を表示するのかを示しています。以下に示しているスクリーンショットでは、これらのインタラクションを示しています。
classification_labels = ["fox", "bear", "dog", "cat"]
import mlflow
mlflow.set_registry_uri("databricks-uc")
registered_model_name = "my_catalog.my_schema.my_model_name"
model_uri = f"models:/{registered_model_name}/1"
loaded_model = mlflow.transformers.load_model(model_uri)
predictions = loaded_model(image_to_classify, candidate_labels = classification_labels)
print(f"Picture has classification result: {predictions[i]}")
以下のリンクをクリックすると別タブで画像が開きます
Unity Catalogにおける重要なボリュームの機能
Unity Catalogにおける非テーブルデータの管理。 ボリュームはテーブル、モデル、関数とともにUnity Catalogのスキーマでカタログ化され、Unity Catalogのオブジェクトモデルのコア原則に従いますので、デフォルトでデータはセキュリティ保護されます。十分な権限を持つデータスチュワードはボリュームを作成することができ、そして、ボリュームの所有者となりコンテンツにアクセスできる唯一のユーザーとなります。他のユーザーやグループにボリュームのコンテンツを読み書きする権限を与えることができます。ボリュームに格納されるファイルはワークスペース横断でアクセスすることができ、適切なワークスペースに親のカタログをバインディングすることで、ボリュームへのアクセスを特定のワークスペースに限定することもできます。
マネージドあるいは外部ボリュームによる柔軟なストレージ環境。 マネージドあるいは外部ボリュームを設定する選択肢があります。マネージドボリュームはUnity Catalogスキーマのデフォルトストレージロケーションにファイルを格納するので、ローカルマシンからアップロードしたファイルからクイックなデータ探索を行うなどのケースで、クラウドストレージへのアクセスを設定する初回のオーバーヘッドなしに、ファイルに対して制御されたロケーションを必要とする際には、便利なソリューションとなります。外部ボリュームは、ボリュームを作成する際に参照する外部のストレージロケーションにファイルを格納し、Databricks内からアクセスするために、他のシステムによって生成されるファイルをステージングする必要がある場合には有用です。例えば、IoTデバイスや医療機器によって大量の画像、動画データが生成されるクラウドストレージロケーションに対する直接のアクセスを提供することができます。
クラウドストレージのパフォーマンスとスケーラビリティでのデータ処理。 ボリュームの背後にはクラウドオブジェクトストレージがあり、クラウドストレージの堅牢性、可用性、スケーラビリティ、安定性のメリットを享受することができます。クラウドストレージのパフォーマンスで高トラフィックのワークロードを実行するためや、ペタバイト以上のデータを大規模に処理するためにボリュームを活用することができます。
最新のユーザーインタフェースによる生産性の向上。 ボリュームは、データエクスプローラ、ノートブック、リネージ、データ追加、クラスターライブラリ設定ユーザーインタフェースを含むDatabricksのプラットフォーム体験とシームレスに統合されています。さまざまなアクションでユーザーインタフェースを活用することができます: ボリュームのアクセス権や所有者の管理。ボリュームエンティティの作成、名前変更、削除のようなアクションを通じたボリュームのライフサイクル管理。ファイルの一覧、アップロード、ダウンロードを含むVol.コンテンツの管理。ノートブックの隣からボリュームとコンテンツの参照。リネージの調査。クラスターのソース、ジョブライブラリの設定などです。
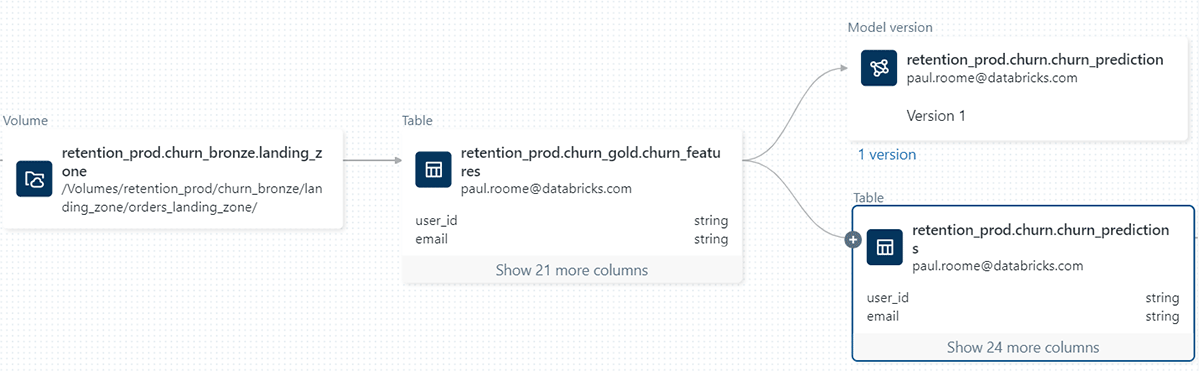
ボリュームのリネージ
ファイルの操作で慣れ親しんだツールを活用。 ボリュームでは、ファイルにアクセスするために、Unity Catalogの階層構造を反映し、Databricksで使用する際には定義されたアクセス権に準拠する専用のパスフォーマットが導入しています:
/Volumes/<catalog>/<schema>/<volume>/<path_to_file>
Apache Spark™やSQLコマンド、REST API、Databricksファイルシステムユーティリティ(dbutils.fs)、Databricks CLI、Terraform、さまざまなOSのライブラリ、ファイルユーティリティを使う際にファイルを参照するためにこのパスを使用することができます。

Unity Catalogで管理されるデータに対する新たな処理能力の解放。 ボリュームは、s3a://、abfss://、gs://のようなクラウド固有のAPIやHadoopコネクタに対する抽象化レイヤーを提供し、Apache Spark™のSparkアプリケーションやネイティブでオブジェクトストレージをサポートしないツールで、クラウドに格納されているデータファイルの操作を容易にします。ボリュームの専用のファイルパスを用いることで、実際の処理は背後のクラウドストレージにマッピングされますが、ファイルがクラスターノードのローカルに存在するかのようにボリュームのコンテンツにアクセス、参照、処理できるようになります。これは特にPandas、scikit-learn、TensorFlow kerasなどの様々なデータサイエンス、MLライブラリを操作している際に有益となります。
Unity Catalogでボリュームを使い始める
Unity CatalogのボリュームはDatabricksのエンタープライズ、プロプランのDatabricks Runtime 13.2以降で利用できます。ボリュームを簡単に使い始められるように、ステップバイステップのガイドをご用意しました。すでにDatabricksアカウントをお持ちであれば、初めてのボリュームを作成するための詳細な手順を示しているドキュメントに従ってください(AWS | Azure | GCP)。ボリュームを作成した、コンテンツを探索するためにデータエクスプローラを活用し(AWS | Azure | GCP)、ボリューム管理のためのSQL構文を学習することができます(AWS | Azure | GCP)。また、ボリュームを最大限に活用するためのベストプラクティスを確認することをお勧めします(AWS | Azure | GCP)。Databricksが初めてであり、まだアカウントをお持ちでない場合には、はじめにUnity Catalogのボリュームのメリットを体験するために、フリートライアルにサインアップしてください。
Delta Sharingによるボリュームの共有や、アップロード、ダウンロード、ファイル削除のようなファイル管理オペレーションのためのREST APIを含むエキサイティングなボリュームの機能を楽しみにしていてください。
What's new with Unity CatalogでのData & AIサミットのセッションや、ベストな実装プラクティスのためのディープダイブセッションや、Everything You Need to Know to Manage LLMsをご覧いただくことも可能です。