Solution Accelerator: LLMs for Manufacturing | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
GoogleのVaswaniらによるトランスフォーマーに関する先進的な論文の発表以来、大規模言語モデル(LLM)が生成AIの領域の大部分を占めることになりました。疑うことがないことですが、OpenAIのChatGPTの発展によって、個人的利用や企業のニーズに応えるために、LLMに対する興味が非常に大きなものとなりました。ここ数ヶ月では、GoogleはBardをリリースし、MetaはLlama 2をリリースし、大規模なテクノロジー機能と比類する能力を示しています。
製造業やエネルギー業界は、オペレーションコストの増大によってより高い生産性を実現するという課題に直面しています。データフォワードな企業はAIに投資を行っており、最近ではLLMに対する投資も強化しています。重要なことですが、データフォワードな企業はこれらの投資から大きな価値を解き放っています。
DatabricksはAI技術の民主化を信じています。我々は全ての企業が自身のLLMをトレーニングする能力を与えられ、自分たちのデータとモデルを所有すべきであると信じています。製造業やエネルギー業界では、多くのプロセスがプロプライエタリであり、それらのプロセスは競合優位性を維持するため、あるいは熾烈な競争の中でオペレーションのマージンを改善するために重要なものです。秘密のソースは、それらを特許や記事を通じて公表するのではなく、取引の秘密として保持します。公開されているLLMの多くは知識の解放を必要とし、この基本的な要件を満たしていません。
ユースケースに関してこの業界で頻繁に起きる質問は、自分たちの従業員を更なるアプリやデータで圧倒することなしに、彼らを増強できるのかということです。そこには、よりAIで強化されたアプリを従業員のために構築、提供するという課題が存在しています。しかし、生成AIとLLMの出現によって、複数のアプリへの依存性を低減し、より少ないアプリに知識を拡張する能力を統合できるものと我々は信じています。
この業界における幾つかのユースケースはLLMによるメリットを享受することができます。これらのいくつかは以下のようなものとなります:
- カスタマーサポートエージェントの拡張。カスタマーサポートエージェントは、質問を持つお客様においてどのようなオープン/未解決の問題があるのかをクエリーできるようにし、顧客を支援するためにAIによって支援されたスクリプトを提供できるようにしたいと考えています。
- インタラクティブなトレーニングを通じたドメイン知識の捕捉と普及。この業界は、「種族の」知識とよく呼ばれる深いノウハウによって支配されています。従業員の高齢化によって、このドメイン知識を恒久的に捕捉するという課題に直面することになります。LLMは、トレーニングに容易に活用できる知識の貯水池として動作することになります。
- フィールドサービスエンジニアの能力の拡張と診断。フィールドサービスエンジには、多くの場合において複雑に絡まり合った膨大なドキュメントにアクセスする際に課題に直面します。問題の新台に要する時間を削減するためにLLMを活用することで、信じられないほどに効率を高めることができます。
このソリューションアクセラレータでは、上記の(3)の項目にフォーカスしており、インタラクティブにコンテキストを考慮するQ/Aセッションの形態で、知識ベースを用いてフィールドサービスエンジニアを支援するユースケースを提供します。製造業者が直面する課題は、プロプライエタリなドキュメントのデータをLLMにどのように構築、取り込むのかという話となります。スクラッチでLLMをトレーニングすることは、非常に高コストであり、数百万ドル、数十万ドル模様することになります。
そうではなく、企業は事前トレーニング済みの基盤LLMモデル(MosaicMLのMPT-7BやMPT-30Bなど)を活用し、自分たちのプロプライエタリデータを用いて、これらのモデルを拡張、ファインチューニングします。これによってコストを10ドル、100ドルにまで引き下げ、10000倍のコスト削減を行うことができます。以下の図1においてファインチューニングに至る完全なパスは左から右に示されており、Q/Aクエリーに至るパスは右から左に示されています。
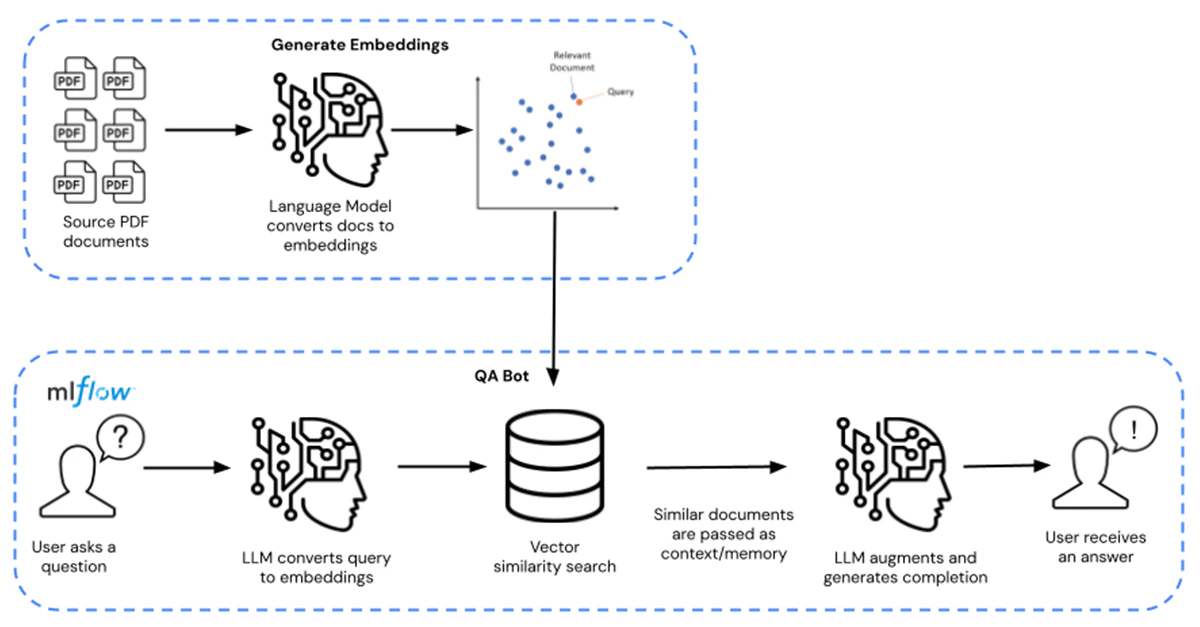
図1. プロプライエタリなドメイン固有のデータに対するコンテキスト認知のQ/AチャットボットとしてLLMのファインチューニングと活用
このソリューションアクセラレータでは、このLLMはPDFドキュメント形式で配布されている化学的なファクトシートで拡張されています。これは、お好きなプロプライエタリなデータで置き換えることができます。このファクトシートはエンベディングに変換され、モデルのリトリーバとして活用されます。モデルをコンパイルするためにLangchainが活用され、DatabricksのMLflowにホスティングされます。デプロイメントは、GPU推論機能を持つDatabricksのモデルサービングエンドポイントの形態で行われます。
これらのアセットをダウンロードして、皆様の企業を拡張しましょう。なぜ、DatabricksがLLMの構築、提供に適したプラットフォームであるのかをより理解したいのであれば、Databricks担当者にご連絡ください。
こちらからソリューションアクセラレータを探索してください。