Parameters Tuning — LightGBM 4.5.0.99 documentationの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
有用な他のリンクのリスト
- Parameters
- Python API
- 自動ハイパーパラメータチューニングのためのFLAML
- 自動ハイパーパラメータチューニングのためのOptuna
Leaf-wise(Best-first)ツリーのパラメーターのチューニング
他の多くの人気のツールではdepth-widthツリー成長を使用していますが、LightGBMではleaf-wiseツリー成長アルゴリズムを採用しています。depth-width成長と比べて、leaf-wiseアルゴリズムははるかに高速に収束することができます。しかし、適切なパラメーターを用いない場合にleaf-wise成長は過学習する場合があります。
leaf-wiseツリーを用いて優れた結果を得るには、いくつかの重要なパラメーターが存在します:
-
num_leaves。これはツリーモデルの複雑性を制御する主要なパラメーターです。理論的には、depth-wiseツリーと同じ数の葉を得るために、num_leaves = 2^(max_depth)を設定することができます。しかし、この簡単な変換は実際には良くありません。leaf-wiseツリーは通常、固定数の葉の数において、depth-wiseツリーよりもはるかに深くなります。深さに制限を設けないことで過学習を引き起こすことがあります。このため、num_leavesをチューニングしようとする際には、2^(max_depth)よりも小さくすべきです。例えば、max_depth=7の場合、depth-wiseツリーは優れた精度を達成できますが、num_leavesを127にすると過学習となり、70や80に設定することで、depth-wiseよりも優れた精度を得られる可能性があります。 -
min_data_in_leaf。これは、leaf-wiseツリーでの過学習を避けるための非常に重要なパラメーターです。この最適な値はトレーニングのサンプル数とnum_leavesに依存します。大きな値に設定すると、あまりに深い木に成長させることを避けることができますが、学習不足に陥る場合があります。実際には、大規模データセットにおいては数百や数千に設定する事で十分です。 -
max_depth。また、ツリーの深さを明示的に制限するためにmax_depthを使うことができます。max_depthを設定した場合、num_leavesも<= 2^max_depthの値に明示的に設定します。
高速化のために
さらなる計算資源を追加
利用するシステムにおいて、LightGBMは数多くのオペレーションを並列化するためにOpenMPを活用します。LightGBMによって使用されるスレッドの最大数は、パラメーターnum_threadsで制御することができます。デフォルトでは、これはOpenMPのデフォルトの挙動(実際のCPUコアあたり1つのスレッド、あるいは環境変数OMP_NUM_THREADSが設定されている場合にはその値)に従います。ベストなパフォーマンスを得るには、これを利用できる実際のCPUコア数に設定します。
より多くのCPUを持つマシンに移行することで、高速なトレーニングを達成できる可能性があります。
(複数マシンでの)分散トレーニングによって、トレーニング時間を削減することができます。詳細はDistributed Learning Guideをご覧ください。
GPU有効化バージョンのLightGBMを使う
LightGBMのGPU有効化バージョンを用いることで、トレーニングを高速化できる可能性があります。詳細はGPU Tutorialをご覧ください。
より狭くツリーを成長させる
LightGBMの合計トレーニング時間は、ツリーのノードの合計数が増えれば増加します。LightGBMはツリーごとのノード数を制御するために活用できるいくつかのパラメーターを提供しています。
以下での提言はトレーニングを高速化しますが、トレーニングの精度を損なう場合があります。
max_depthを減らす
このパラメーターは、それぞれのツリーのルートノードとリーフノード間の最大距離を制御する整数値です。トレーニング時間を削減するためにmax_depthを減らします。
num_leavesを減らす
LightGBMは深さに関係なく、ノードを追加することによるゲインに基づいてツリーにノードを追加します。以下のthe feature documentationの図ではこのプロセスを説明しています。
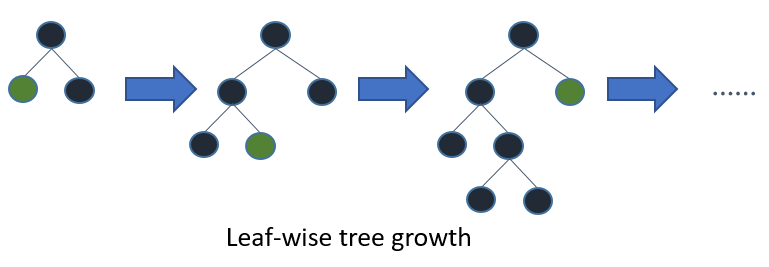
この成長戦略のため、ツリーの複雑性を制御するためだけにmax_depthを用いることは直感的ではありません。num_leavesパラメーターは、ツリーごとのノードの最大数を設定します。トレーニング時間を削減するにはnum_leavesを削減します。
min_gain_to_splitを増やす
新規ツリーノードを追加する際、LightGBMはより大きなゲインを得られる分割点を選択します。基本的にゲインは、分割点を追加することで得られたトレーニングのロスの削減となります。デフォルトでは、LightGBMはmin_gain_to_splitは0.0は設定し、これは「小さすぎる改善が認められない」を意味します。しかし、実際にはトレーニングロスにおける非常に小さい改善は、モデルの汎化エラーに意味のあるインパクトを与えないことに気づくかもしれません。トレーニング時間を削減するためにmin_gain_to_splitを増やしましょう。
min_data_in_leafとmin_sum_hessian_in_leafを増やす
LightGBMでは、トレーニングデータのサイズと特徴量の分布に応じて、少数の観測値のみを説明するツリーノードを追加することができます。ほとんどの極端なケースでは、トレーニングデータの単一の観測値のみが属するツリーノードの追加を検討しましょう。これは、うまく汎化されることはほとんどなく、過学習のサインの可能性があります。
これは、max_depthとnum_leavesのようなパラメーターで間接的に回避することは可能ですが、LightGBMではこれらの過度に特化したツリーノードの追加を直接回避する助けになるパラメーターを提供しています。
-
min_data_in_leaf: 追加されるツリーノードに最低限含まれるべき観測値の数。 -
min_sum_hessian_in_leaf: リーフにおける観測値に対するHessian(それぞれの観測値に対して評価される目的関数の二階導関数)の合計値の最小値。いくつかの回帰においては、これは単にそれぞれのノードに属すべき最小レコード数となります。分類においては、確率分布に対する合計値を表現します。このパラメータの値に対してどのように理由づけを行うのかに関する優れた説明に関しては、こちらのStack Overflowの回答をご覧ください。
成長させるツリーを減らす
num_iterationsを減らす
num_iterationsパラメーターは実行されるブースティングラウンドの数を制御します。LightGBMは学習器として決定木を用いるので、これは「木の数」と考えることができます。
num_iterationsを変更しようとする際には、learning_rateも変更しましょう。learning_rateはトレーニング時間に影響を与えません。一般的なルールとして、num_iterationsを削減した際には、learning_rateも減らすべきです。
num_iterationsとlearning_rateの適切な値を選択することは、データと目標に大きく依存するので、多くの場合、ハイパーパラメーターチューニングを通じて取りうる値から選択することになります。
トレーニング時間を削減するためには、num_iterationsを減らしましょう。
Early Stoppingを使う
Early Stoppingを有効化すると、それぞれのブースティングラウンドの後に、トレーニングプロセスには含まれないデータを含む検証セットに対して、モデルのトレーニングの精度が評価されます。そして、その精度は以前のブースティングラウンドと比較されます。モデルの精度が以降のいくつかの連続するラウンドで改善しなかった場合、LightGBMはトレーニングプロセスを停止します。
この「連続するラウンドの数」は、パラメーターearly_stopping_roundによって制御されます。early_stopping_round=1は、「検証セットでの精度が改善しなくなった初めてのタイミングでトレーニングを停止する」と言うことです。
トレーニング時間を削減するために、early_stopping_roundと検証セットを指定しましょう。
分割数の削減を検討する
以前のセクションで説明したパラメータは、幾つのツリーを構成するのか、ツリーごとに幾つのノードを構成するのかを制御します。モデルにツリーノードを追加する時間の送料を削減することで、トレーニング時間をさらに削減することができます。
以下の提案はトレーニングをスピードアップしますが、トレーニングの精度を損なう可能性があります。
データセットを作成する際、特徴量の事前フィルタリングを有効化する
デフォルトでは、LightGBMのDatasetオブジェクトが構築された際、min_data_in_leafの値に基づいていくつかの特徴料が除外されます。
シンプルな例として、feature_1という特徴量を持つ1000の観測値を持つデータセットを考えてみます。feature_1は二つの値のみを取ります: 25.0(995の観測値)と 50.0(5つの観測値)です。min_data_in_leaf = 10の場合、この特徴量は、リーフノードの少なくとも一つは観測値を5つしか持たない適切なスプリットになってしまうため分割されません。
この特徴量を再検討し、すべてのイテレーションで無視するのではなく、LightGBMはトレーニング前にDatasetを構築する際にこの特徴量を除外します。
このデフォルトの挙動はfeature_pre_filter=Falseを設定することで上書きすることができますので、トレーニング時間を削減するためにはfeature_pre_filter=Trueを設定しましょう。
データセットを作成する際、max_binやmax_bin_by_featureを減らす
LightGBMのトレーニングは、トレーニングスピードを改善し、メモリ要件を削減するために、連続的な特徴量を離散的なビンに分割します。このビニングはDataset構成時に一度行われます。ノード追加の際に検討される分割数はO(#feature * #bin)なので、特徴量ごとのビンの数を減らすことで、評価されるべきスプリットの数を削減することができます。
max_binは、特徴量が分割されるビンの最大数を制御します。max_bin_by_featureを設定することで、特徴量ごとにこの最大値を設定することができます。
トレーニング時間を削減するために、max_binやmax_bin_by_featureを減らしましょう。
データセットを作成する際、min_data_in_binを増やす
候補となる分割ポイントとしてビンの境界を評価したとしても、最終的なモデルをそれほど変更しない可能性があるような少数の観測値を含むビンがいくつか存在する場合があります。min_data_in_binを設定することで、ビンの粒度を制御することができます。
トレーニング時間を削減するにはmin_data_in_binを増やしましょう。
feature_fractionを減らす
デフォルトでは、LightGBMはトレーニングプロセスにおいてDatasetのすべての特徴量を考慮します。feature_fractionを> 0と<= 1.0の間の値に設定することで、この挙動を変更することができます。例えば、feature_fractionを0.5に設定することで、それぞれのツリーの構成の最初に、特徴量の50%をランダムに選択するようにLightGBMに指示することができます。これによって、それぞれのツリーノードを追加するために評価すべきスプリットの総数を削減することができます。
トレーニング時間を削減するためにfeature_fractionを減らしましょう。
max_cat_thresholdを減らす
LightGBMは、カテゴリー特徴量の最適な分割ポイントを特定するためのカスタムのアプローチを採用しています。このプロセスでは、LightGBMはカテゴリー特長量を二つのグループに分割する分割点を探索します。これらは時に「k-vs.-rest」スプリットと呼ばれます。max_cat_thresholdの値を大きくすると、探索する分割点が多くなり、グループのサイズも大きくなります。
トレーニング時間を削減するために、max_cat_thresholdを減らしましょう。
データを減らす
バギングを使う
デフォルトでは、LightGBMはそれぞれのイテレーションでトレーニングデータに含まれるすべての観測値を使用します。代わりに、LightGBMにトレーニングデータをランダムにサンプリングするように指示することができます。置き換えなしの複数のランダムサンプルに対するこのようなトレーニングプロセスは「バギング」と呼ばれます。
新規サンプルをどの程度の頻度で取得するのかを制御するために、bagging_freqを0より大きい整数値に設定しましょう。サンプルのサイズを制御するために、bagging_fractionを> 0.0と< 1.0の間で設定します。例えば、{"bagging_freq": 5, "bagging_fraction": 0.75}は、LightGBMに「5つのイテレーションごとに置き換えなしに再サンプリングを行い、トレーニングデータから75%のサンプルを抽出してください」ということを指示します。
トレーニング時間を削減するために、bagging_fractionを減らしましょう。
構築したデータセットをsave_binaryを指定して保存する
これはLightGBM CLIにのみ適用されます。パラメーターsave_binaryを引き渡すと、トレーニングデータセットとすべての検証セットは、LightGBMで解釈できるバイナリーフォーマットで保存されます。これによって、Datasetの構成の際に行われたビニングやその他の作業を再度実行する必要がないため、次回はスピードアップします。
精度改善のために
- 大きな
max_binを使う(遅くなる可能性あり) - 大きな
num_iterationsと小さなlearning_rateを使う - 大きな
num_leavesを使う(過学習の可能性あり) - 大きなトレーニングデータを使う
-
dartを試す
過学習に対応する
- 小さな
max_binを使う - 小さな
num_leavesを使う -
min_data_in_leafとmin_sum_hessian_in_leafを使う -
bagging_fractionとbagging_freqを設定してバギングを使う -
feature_fractionを設定して、特徴量のサブサンプリングを使う - 大きなトレーニングデータを使う
- 正則化のために
lambda_l1、lambda_l2、min_gain_to_splitを試す - 深いツリーに成長しないように
max_depthを試す -
extra_treesを試す -
path_smoothを増やしてみる