Seven Reasons to Learn PyTorch on Databricks - The Databricks Blogの翻訳です。
新たなコンセプトを学ぶのを容易にするのは何でしょうか、言語、システム?新たなタスクを学ぶ際に、すでに持っているスキルとのアナロジーを探しませんか?
学習の過程において、3つの望ましい特性が存在します:親しみやすさ、明確さとシンプルさです。親しみやすさは、旧来の方法と新たな方法の間に認識できる慣例性を提供することで、乗り換えを容易にします。明確さは認知の負荷を最小にします。そして、シンプルさは未知のことを受け入れる際の摩擦を低減し、結果として、新たなコンセプト、言語、システムを学ぶことを助けます。
研究者の間で人気があるだけではなく、実運用環境における機械学習の実践者によって受け入れられ、活気に満ちたコミュニティを形成しているPyTorchは、親しみやすく、学習が容易で、あなたの機械学習ユースケースに適用することができます。
これらの特性を踏まえて、この記事ではPyTorchを学ぶのが容易であるいくつかの理由を検証し、Databricksのレイクハウスプラットフォームが学習プロセスを支援するのかを説明します。

1a. PyTorchはPythonicです
Fluent PythonでLuciano RamalhoはPythonicを、簡潔かつ可読性を高くするために言語の機能を活用したPythonコードの使用方法として定義しました。Pythonのオブジェクトの構成体は特定のプロトコルに従い、これらはクラス、イテレータ、ジェネレータ、シーケンス、コンテキストマネージャ、モジュール、コルーチン、デコレータに対して一貫性のあるパターンに従った振る舞いをします。Pythonのデータモデル、モジュール、言語の構成体に少しでも触れたことがあるのであれば、PyTorch APIにおいても、torch.tensor、torch.nn.Module、torch.utils.data.Datasets、torch.utils.data.DataLoaderなど同様の構成体があることに気づきます。また、PyTorchでは、Pandasやscikit-learn、SciPyのようなPyDataパッケージを用いて簡潔なコードを記述できると言う別の側面もあります。
PyTorchはPyDataエコシステムと統合されているので、あなたがもし[NumPy]
(https://numpy.org/)に慣れ親しんでいるのであれば、[Torch Tensor](https://pytorch.org/docs/stable/tensors.html)を学ぶのは非常に容易になります。NumPyのarrayとtensorは非常に似た構造とオペレーションを有しています。[Apache Spark™](https://spark.apache.org/)のオペレーションにおいて[DataFrame](https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrame.html?highlight=dataframes)が中心的なデータ構造となるように、tensorはPyTorcモデルへのインプット、トレーニング、計算処理、スコアリングにおいて中心的な役割を担います。PyTorchのメンタルイメージ(以下の図)はn次元のNumPy arrayにマッピングされます。

例えば、NumPy arrayを作成し、シームレスにTorch tensorに変換することができます。以下のコードに示すように、NumPyオペレーションに対する理解はそのままtensorのオペレーションに転用することができます。
両方とも、list、tuple、dictionary、setなどのPythonオブジェクトAPIを利用する際に必要となる、馴染み深い、必須かつ直感的なオペレーションを有しています。これらのNumPyと同等のarrayオペレーションに対する理解は、Torch tensorにおいても役立ちます。以下の例を見てみましょう。



最新のPyTorch 1.8.0リリースでは、さらに高速フーリエ変換において、PyTorchのtensorとNumPyの間で同等のオペレーションを実現しています。

1b. 簡単にPyTorchをニューラルネットワークモジュールに拡張できます
PyTorchには多層ネットワークアーキテクチャを構築するためのニューラルネットワークモジュールが含まれています。PyTorchの用語で、これらのモジュールはネットワークのそれぞれのレイヤーを構成します。ベースクラスモジュールtorch.nn.Moduleから派生させることで、シンプル、あるいは複雑な多層ニューラルネットワークを容易に構築できます。PyTorchのカスタムネットワークモジュールクラスとメソッドを定義するには、カスタムPythonオブジェクトクラスをベースクラスオブジェクトから作成するのと同様のパターンに従います。2層の線形ネットワークを定義してみましょう。

カスタムのTwoLayeredNetは、フロー、構造の観点でPythonicであることに注意してください。torch.nn.Moduleから派生したクラスは、パラメータとクラスイニシャライザを持ち、インタフェースメソッドを定義し、呼び出し可能なものとなります。すなわち、ベースクラスtorch.nn.ModuleはPythonのマジック__call__()オブジェクトメソッドを実装しています。2層ネットワークはシンプルなものですが、Pythonのベースオブジェクトからクラスを拡張する際の親和性をデモするものとなっています。
さらに、PyTorch APIの文法、構造、形態、振る舞いがあまりに慣れ親しんだものであるため、まるでPythonのアプリケーションコードを読み書きしているような感覚になることでしょう。馴染みがないちょっとしたものと言えば、PyTorchとAPIでしょうが、新たなPyDataパッケージAPIを学ぶのと違いはなく、Pythonアプリケーションコードに取り込めるものです。
さらにPythonicなコードに関しては、トレーニングループと損失関数を記述するPyTorchコード、慣れ親しんでいるPythonのイテレーティブな構造体、GPUのためのcudaライブラリの使用例を記載しているノートブックを読んでみてください。
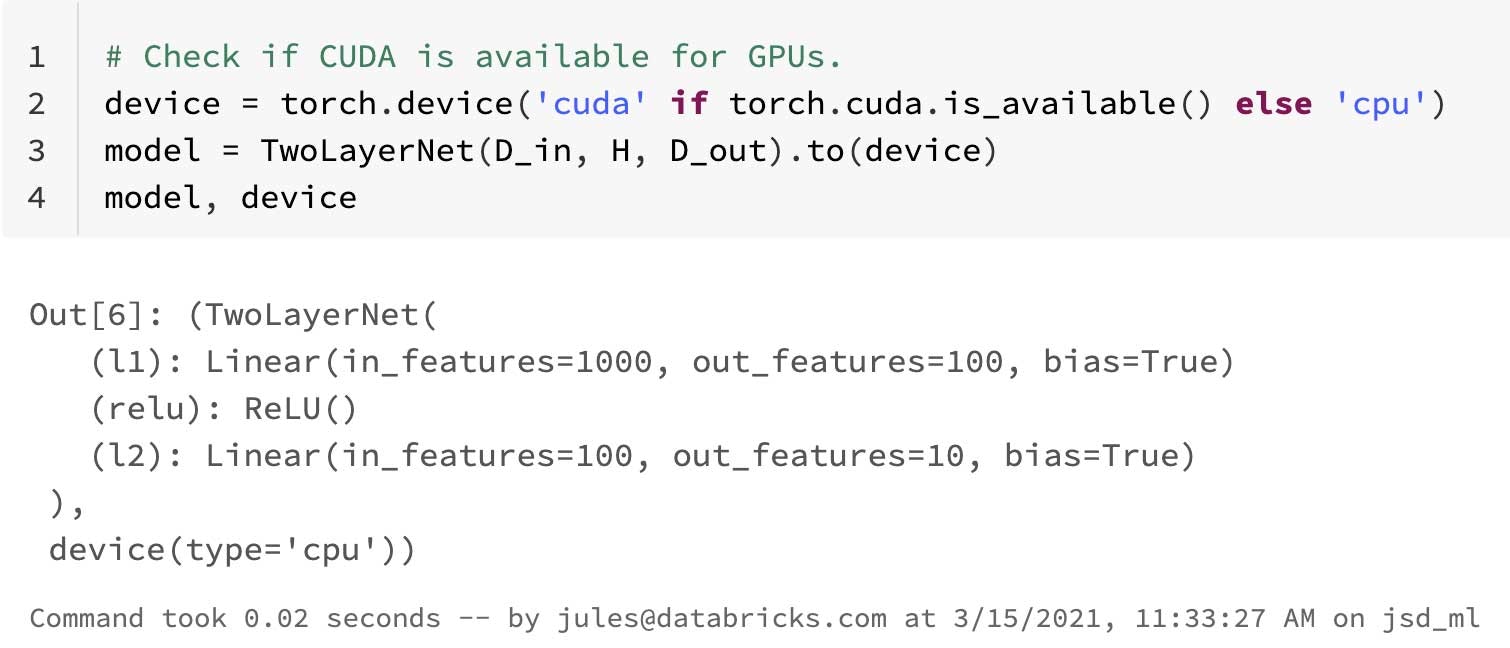
Pythonで馴染みのある言語構造体を用いて、いくつかのイテレーションを伴うシンプルなトレーニングループを定義します。
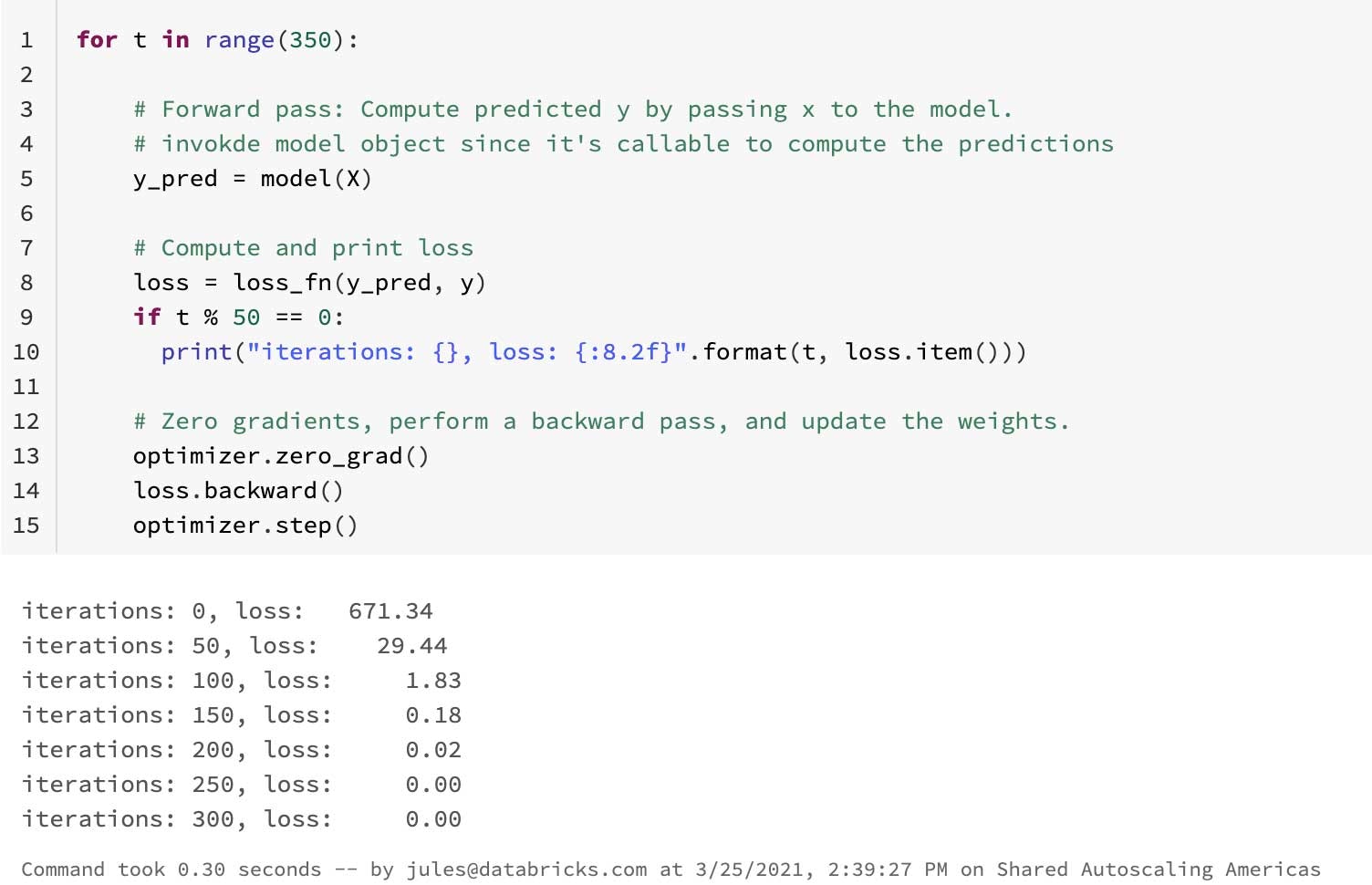
PythonのカスタムクラスとシンプルなPyTorchのニューラルネットワークの間で見分けがつくパターンとフローがこの後に続きます。また、Pythonコードのように読めます。PyTorchにおけいて認識できるPythonicなパターンは、イテレータを生成するために、どのようにDatasetとDataLoaderがPythonのプロトコルを使用するのかです。
1c. 簡単にPyTorchデータセットをDataLoader向けにカスタマイズできます
PyTorchのデータロードのユーティリティのコアは、torch.utils.data.DataLoaderです。トレーニングのエポックにおいて入力バッチに対してイテレートする、PyTorchイテレーティブトレーニングプロセスの重要なパーツです。DataLoaderはPythonのsequenceとiterableプロトコルを実装します。これには、オブジェクトに対する__len__、__getitem__マジックメソッドが含まれます。これもまた非常にPythonicな振る舞いと言えます。実装の一部では、listに対する理解、tensorに変換するためのNumPy array、n番目のデータアイテムにアクセスするためのランダムアクセスを利用します。これら全てがPythonで行うアクセスパターン、振る舞いに合致しています。
モデルをトレーニングするために使用する、温度のシンプルなカスタムDatasetを見てみましょう。他の複雑なデータセットには、画像、tensorの大量の特徴量データセットなどが挙げられます。

PyTorchのDataloaderクラスは、カスタムのFahrenheitTemperaturesクラスオブジェクトをパラメータとしたインスタンスを受け取ります。ユーティリティクラスはPyTorchトレーニングループにおける標準となっています。イテレータのようにデータバッチに対してイテレートする能力を有しています。これもまた、非常にPythonincであり、物事を行う直感的な方法と言えます。

ここではカスタムのDatasetを実装しているので、これを使ってPyTorchトレーニングループを実行しましょう。

上で述べたPythonicな理由は、Databricksのレイクハウスプラットフォームと直接関係はありませんが、親しみやすさ、明確さ、シンプルさ、そしてPyTorchのコードを書くためのPythonicな方法に関する考え方は共通しています。次に、Databricksレイクハウスプラットフォームの機械学習ランタイムのどのような側面が、PyTorchを学ぶ助けとなるのかを検証していきます。
2. Pythonパッケージのインストールは不要です
Databricksレイクハウスプラットフォームの一部として、機械学習(ML)ランタイムには最新のPython、PyTorch、PyDataエコシステムパッケージと追加の標準的なMLライブラリが事前にインストールされており、パッケージをインストール、管理する必要がありません。アウトオブボックス、かつ、すぐに使えるランタイム環境は、パッケージをインストール、管理すると言う負荷からあなたを解放します。追加のPythonパッケージをインストールしたいのであれば、シンプルに%pip installを呼び出すだけです。ご利用のクラスターにおけるパッケージ管理をサポートする機能は、Databricks利用者から人気があり、開発モデルライフサイクルにおいて広く利用されています。
事前インストールされたパッケージの一覧を表示するには、%pip listを実行します。

3. 簡単にCPU、GPUを活用できます
ディープラーニングにおけるニューラルネットワークには、数値主体の計算が含まれ、ここには大規模かつ高ランクのtensorに対する行列操作やドット積が含まれます。GPUを必要とする計算量が多いPyTorchアプリケーションに対しては、GPU対応MLランタイムのクラスターを作成し、データをGPUで処理するように指示します。このようにして、全てのトレーニングはGPUで行われるようになり、上の例ではcudaを用いたTwoLayeredNetの例を示しました。
この例ではシンプルなコードを示しており、二つのランダムに生成されたtensorに対する行列積をしていることに注意してください。実際のPyTorchアプリケーションでは、auto-grad計算や順伝搬、逆伝搬を通じてより計算量が必要となる処理が行われます。

4. 簡単にTensorBoardを活用できます
他のブログ記事で発表したように、Databricksランタイム(DBR)の一部として、TensorBoardを利用できます。マジックコマンドは同じノートブック内にTensorBoardから得られるトレーニングメトリクスを表示します。ノートブックを離れて、他のタブでTensorBoardを起動する必要はありません。このインプレースのTensorBoardの可視化は、シンプルさと開発者のエクスペリエンスの観点で重要な改善であると言えます。
PyTorch FashionMNISTサンプルを実行してTensorBoardのロギングを体験してみましょう。最初に、SummaryWriterを定義し、PyTorchのtorchvision.models.resnet50モデルにおけるDataLoaderにFashionMNISTのDatasetを与えます。

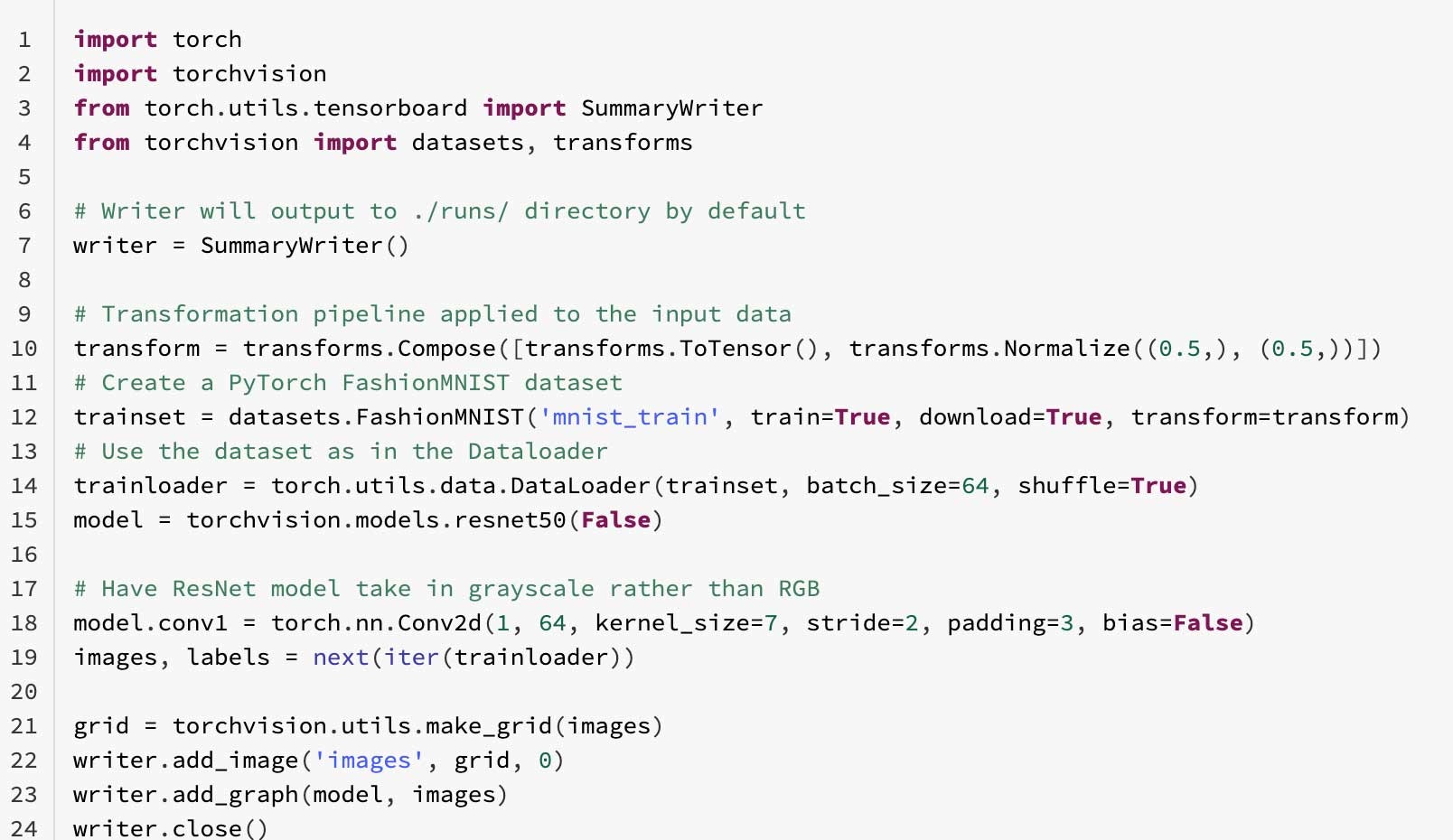
Databricksノートブックのマジックコマンドを使うことで、TensorBoardをノートブックのセルの中に起動でき、トレーニングメトリクスとモデルの出力を確認できます。
%load_ext tensorboard
%tensorboard --logdir=./runs
5. PyTorchはMLflowと統合されています
Databricksをよりシンプルなものにしようと言う弛まない努力を通じて、PyTorch Lightningを含むMLライブラリにおいて、MLflowエンティティ(メトリクス、タグ、パラメータ、アーティファクト)を自動的にロギングするMLflow fluent tracking APIをエンハンスしました。画面右上にあるExperimentからアクセスできるDatabricksワークスペースの重要なパーツであるMLflowのUIを通じて、全てのエクスペリメントを参照できます。トレーニングにおける全てのエクスペリメントのランは自動でMLflowのトラッキングサーバーによって記録されます。MLflowエンティティを記録するために明示的にトラッキングAPIを使用する必要はありません。またこれは、画像、ディクショナリー、テキストアーティファクトなd追加のエンティティのトラッキング、記録を妨げるものではありません。
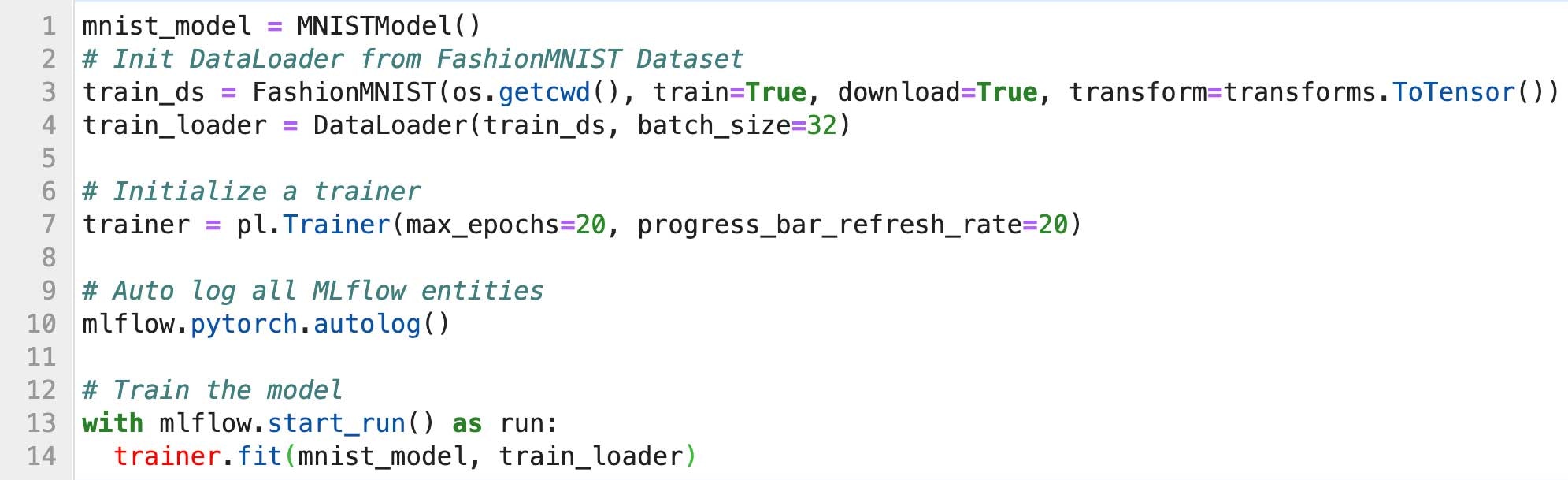
こちらが、トレーニングループステップのみを含む(バリデーション、テストは除く)ミニマムのPyTorch Lightning FashionMNISTのサンプルです。こちらはMLflowエンティティをMLflowがどのように自動で記録するのか、ノートブックでどのようなランが行われたのかを確認するために用いるMLflow UIがどのようなものであるか、モデルを登録しサービング、デプロイするのかをデモするためのものです。
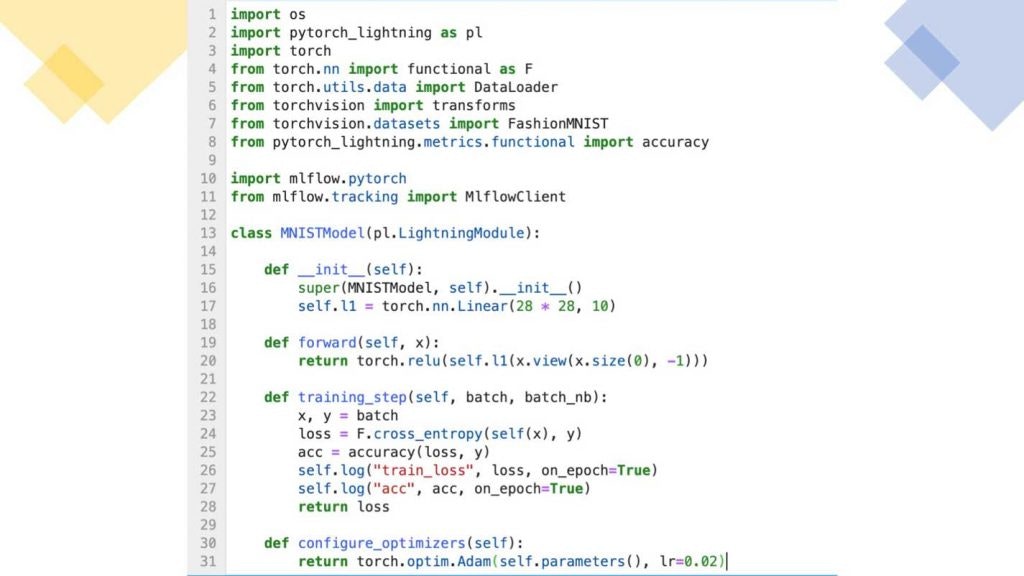
Pythonクラスを作成するのと同じようにPyTorchモデルを作成し、FashionMNIST DataLoader、PyTorch Lightning Trainerを使用し、trainer.fit()メソッドにおけるすべてのMLflowエンティティを自動で記録します。
6. MLflowに記録されたPyTorchモデルをTorchScriptに変換できます
TorchScriptはPyTorchコードからシリアライズ可能、最適化可能なモデルを作成するための方法です。MLflowに記録されたPyTorchモデルをTorchScriptフォーマットに変換し、高性能かつ独立したプロセスを保存、読み込み(デプロイ)できます。あるいは、エンドポイントとしてDatabricksのクラスターにデプロイし、サービングすることもできます。
このプロセスには以下のステップが含まれます。
- MLflow PyTorchモデルを作成
- JITを用いてモデルをコンパイルし、TorchScriptモデルに変換
- TorchScriptモデルを記録あるいは保存
- TorchScriptモデルをロードあるいはデプロイ
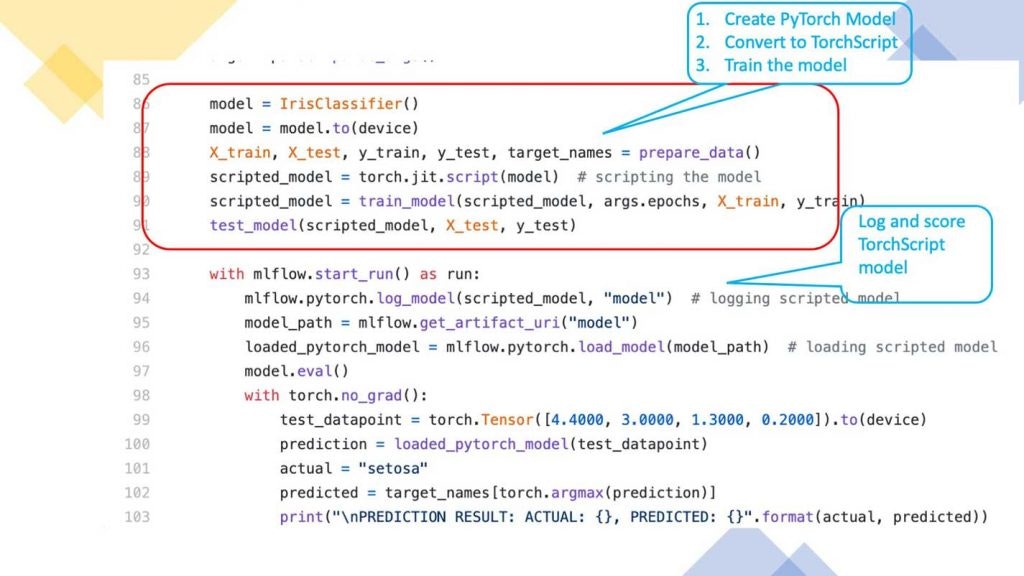
簡潔にするためにここには全てのコードを含めていませんが、GitHub MLflow examplesディレクトリでIrisClassificationとMNISTのサンプルコードを確認することができます。
7. すぐにPyTorchの分散トレーニングチュートリアルを実行できます
最後のポイントとして、DatabricksレイクハウスのMLRクラスターを活用して、PyTorchモデルトレーニングを分散することが可能であることが挙げられます。我々は、a)シングルノードでのトレーニングとb)トレーニングを分散処理するためにどのようにHorovodライブラリに移行すべきかを説明するチュートリアルを提供しています。これらのチュートリアルを学ぶことで、あなたのPyTorchモデルをどのように分散処理するのかを理解できるようになります。すぐ利用でき、簡単にインポートできるノートブックをクラスターに取り込むことで、これらのノートブックは分散トレーニングを学ぶための素晴らしい手段となりいます。推奨されるセットアップに従い、モデルがトレーニングされる様子をご覧ください。

© r/memes – Watching a train model meme
それぞれのノートブックには、MLRをセットアップするためのステップバイステップのガイド、あなたのモデルをどのようにCPU、GPUに適合させるのか、Horovodライブラリを用いてどのように分散トレーニングするのかを説明しています。
- Train a simple PyTorch Model
- Use PyTorch on a Single Node
- Single node PyTorch to distributed deep learning
- Simplify data conversion from Apache Spark™ to PyTorch
さらに、PyTorchコミュニティはスターターチュートリアルとして、素晴らしいLearning with PyTorch Examplesを提供しています。シンプルにコードをDatabricksノートブックにカットアンドペーストするか、Jupyterノートブックをインポートして、Python IDEと同様にMLRで実行できます。これらに取り組んでいる過程で、PyTorchのPythonicかつ必須そして直感的な本質を体感することでしょう。
また、Data + AI Summit(終了)では、数多くのPyTorchの実運用ユースケースを説明するセッションが開催されますので、興味がある方はご登録ください。
次のステップ
サンプルノートブックを用いて、MLRクラスターでPyTorchチュートリアルを実行することができます。Databricksアカウントをお持ちでない場合にはフリートライアルをご利用いただき、DatabricksレイクハウスプラットフォームでPyTorchをお試しください。シングルノードでのトレーニングであれば、機能は限定(CPUのみの利用など)されていますが、無料のDatabricksコミュニティエディションをご利用いただけます。