How to Parse Improperly Formatted JSON Objects in Databricks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
イントロダクション
ファイルを取り扱う際、1つ以上のJSONオブジェクトを同じファイルに書き込むカスタムAPIやアプリケーションによって生成されるプロセスが存在することがあります。複数のデバイスIDを含むファイルのサンプルを以下に示します。

さまざまな装置からの複数のデバイスデータがJSONオブジェクトの形態で生成されたテキストファイルに含まれていますが、json.load()関数を用いてこれをパースしようとすると、最初の行がデータのトップレベルの定義として取り扱われます。最初のdevice-idレコード以降の全ては無視され、ファイルないの他のレコードが読み込まれません。この関数を使用する際に、1つ以上のJSONオブジェクトが含まれているとJSONファイルは不正となります。
これに対するもっとも素直なソリューションは、ソースでフォーマットを修正することであり、これはAPIやアプリケーションが適切にフォーマットを作成するように書き直すことを意味します。しかし、レガシーなシステムやプロセスをコントロールできないことから、企業が常にこれを行えるとは限りません。このため、解決すべき問題は、無効なJSONオブジェクトを受け取り、パースできるように適切にフォーマットすることになります。
PySparkのjson.load()関数を使うのではなく、すべてのデバイスIDをカプセル化し、パースするためのテーブルにデータをロードするために、PySparkとAutoLoaderを活用します。
Databricksメダリオンアーキテクチャ
Databricksメダリオンアーキテクチャは、データを取り込み、アーキテクチャの異なるレイヤーを通過するとごとにデータを洗練する我々のデザインパターンです。
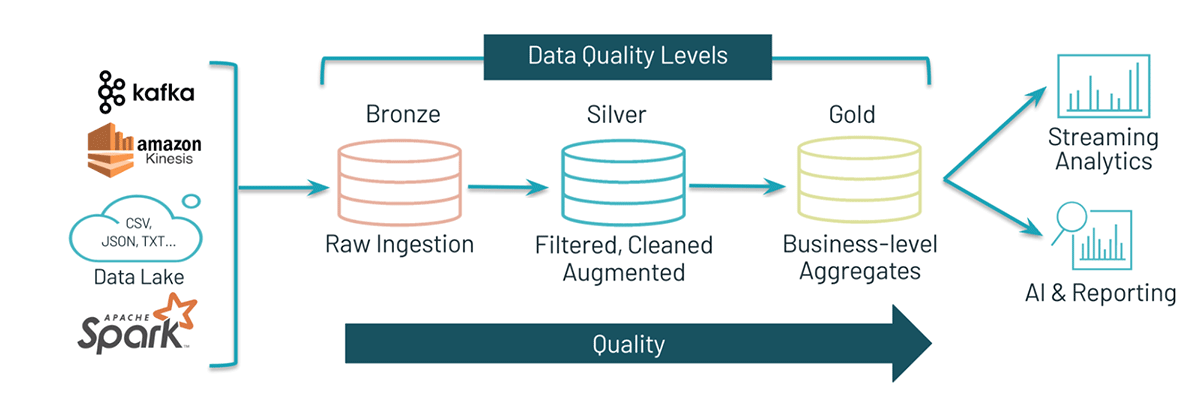
伝統的なパターンでは、外部ソースシステムからレイクハウスにデータを到着させるためにブロンズレイヤーを使用します。データにETLパターンが適用され、ブロンズレイヤーからのデータは、データの企業ビューを提供するのに十分になるように、マッチング、フィルタリング、クレンジングされます。このレイヤーはシルバーレイヤーとして提供され、アドホック分析、高度分析、機械学習(ML)のスタート地点となります。ゴールドレイヤーとして知られる最終レイヤーは、特定のビジネス要件を満たすために最終的なデータ変換処理を適用します。
このパターンでは、レイクハウスの異なるレイヤーを通過するごとにデータが整理され、データペルソナは様々なプロジェクトで必要とした際にデータにアクセスすることが可能となります。
以下では、ブロンズ-シルバー-ゴールドのアーキテクチャを用いてJSONオブジェクトをパースするプロセスをウォークスルーします。
Part1: ブロンズのロード
ブロンズオートローダーストリーム
Databricks AutoLoaderを用いることで、データレイクにデータが到着するとすぐに新規バッチやストリーミングファイルをDelta Lakeテーブルに取り込むことができます。このツールを用いることで、JSONデータを取り込み、それぞれのDelta Lakeレイヤーを進むに従い、データを洗練することができます。
AutoLoaderを用いることで、通常データが適切にフォーマットされているのであれば、データを取り込むためにJSONフォーマットを使用することができます。しかし、ここでは不適切にフォーマットされているので、AutoLoaderはスキーマを推定することができません。
代わりに、AutoLoaderのtextフォーマットを使用して、データをブロンズテーブルに取り込み、パーシングできるように後で変換処理を適用します。このブロンズレイヤーは、それぞれのロードのタイムスタンプをインサートし、ファイルのJSONオブジェクト全体が別のカラムに格納されます。




このノートブックの最初の部分では、Bronze Deltaストリームが生成され、当該場所に到着する生のファイルを取り込み始めます。データがブロンズDeltaテーブルにロードされると、シルバーテイブルへのロードとパーシングの準備が整ったことになります。
Part2: シルバーのロード
これでデータがブロンズテーブルにロードされたので、異なるレイヤーにデータを移動させる次のパートは、データに変換処理を適用することとなります。ここには、正規表現を用いてテーブルをパースするためのユーザー定義関数(UDF)が関係してきます。不適切にフォーマットされたに対して、それぞれのれキー度の適切な場所の前後にブラケットをラッピングし、後のパースで使用するデリミタを追加しまうs。
スラッシュデリミタの追加

結果:

デリミタでレコードを分割し、arrayにキャスト
これらの結果によって、このカラムは我々が追加したスラッシュデリミタによってそれぞれのレコードに分割するためにsplit関数を組み合わせて使用することができ、それぞれのレコードをJSON arrayにキャストすることができます。このアクションは、後でexplode関数を使う際に必要となります。


Apache Spark™によるデータフレームのexplode
次に、explode関数を用いることで、カラム内の配列を異なる行にパースすることができます。


最終的なJSONオブジェクトスキーマを取り出す
最後に、シルバーDeltaテーブルにロードするための最終的なスキーマを取り出すために、パースされた行を使用します。

シルバーオートローダーストリーム
このスキーマとSpark関数from_jsonを用いることで、シルバーDeltaテーブルに流れ込むAutoLoaderのストリームを構築することができます。

シルバーテイブルにストリームをロードすることで、個々のJSONレコードを持つテーブルを手に入れることができます。



Part3: ゴールドのロード
これで、個々のJSONレコードがパースされたので、カラムからネストされたデータを取り出すためにSparkのselect表現を用いることができます。このプロセスによって、ネストされた値のそれぞれに対してカラムが作成されます。

ゴールドテーブルのロード
このデータフレームを用いることで、それぞれの行に個々のデバイスの読み取り値を持つ最終的にパースされたテーブルを手に入れるために、データをゴールドテーブルにロードすることができます。



ビジネスレベルのテーブルの構築
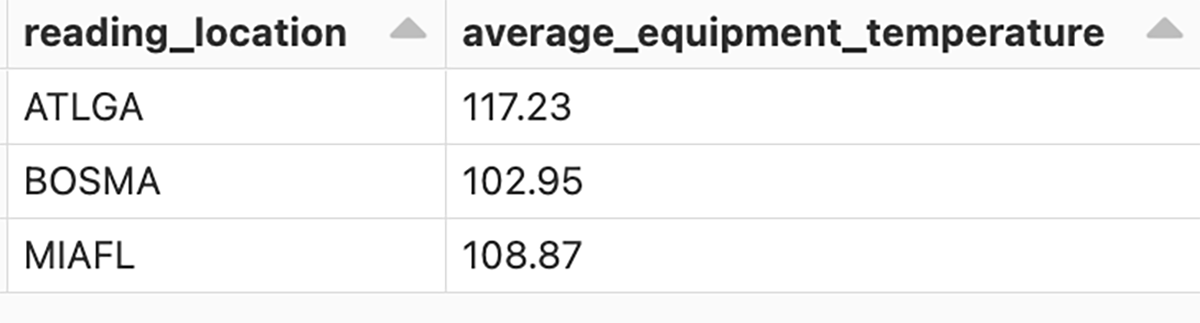
最後にゴールドテーブルを用いて、読み取り場所ごとの平均気温を取得するために気温データを集計し、分析のためのビジネスレベルテーブルにロードします。

集計テーブルの結果

まとめ
Databricks AutoLoaderとSpark関数を用いることで、複数のファイルにまたがる個々のJSONオブジェクトをパースするブロンズ-シルバー-ゴールドのメダリオンアーキテクチャを構築することができました。ゴールドテーブルにロードすることで、データを集計して様々なビジネスレベルのテーブルにロードすることができます。このプロセスは、履歴データをクリーンなデータに簡単に変換できるように、企業の要件に合わせてカスタマイズすることができます。
試してみてください!シミュレートされたJSONデータを構築し、レコードをパースし、様々なビジネスレベルテーブルを構築するために、ブロンズ-シルバー-ゴールドアーキテクチャを使用するために、添付ノートブックを使ってください。