Intermittent Demand Forecasting With Nixtla on Databricks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
本書はNixtlaとDatabricksの共著です。NixtlaのCEO、共同創始者であるMax MergenthalerとCTO、共同創始者であるFederico Garza Ramírezに感謝の意を表します。
ノートブックをダウンロードして詳細を学ぶには、需要予測ソリューションアクセラレータをチェックしてください。
企業が適切なタイミングに適切な場所に(そして適切な価格で)適切な商品を提供する能力は、需要を予測する能力に依存しています。このため、多くの企業において需要予測は重要なプラクティスとなっています。
予測が完全に正確であることは期待されていません。常に我々が考慮できない要因が存在しています。しかし、これまで企業は使用できるソフトウェアパッケージに合わせてデータを加工することを強いられ、計算キャパシティの制約を受けていました。これによって、現在の多くの企業において予測精度の劣化が引き起こされており、劣化は30%以上とも言われています。
この結果は劇的なものでした。予測とオペレーションの間の繋がりによって、予測精度の10%から20%の増加は在庫コストを5%削減し、収益を2から3%改善します。不正確な予測を活用することで、これらの企業はお金を失うだけでなく、予測結果に対する解釈において意見や勘に依存し続けることとなり、研究を繰り返すことでプロセスにパイアスを混入させてしまうことになりました。
このような予測の解釈に対する依存性や介入によって、多くのサプライチェーンの近代化において中心的位置を占める一連の自動化プロセスを一歩全死させようとする企業の能力を危険に晒すことになります。近代化できない企業は、すぐに自分達がお客様に同じスピード、効率性、柔軟性で商品をデリバリーする競合と競争していることを知り、競争が激化する市場で不利な状況に自分達を置いてしまうことになりました。
多くの企業がきめ細かい需要予測に移行しています
多くの企業が前進する方法は自分達の需要予測プロセスに対して突飛な再検討を行うことではなく、利用可能な最新情報を提供できるレベルで需要予測を行うという本来のゴールに立ち返るというものです。企業におけるいろいろな場所では、微妙に物事が異なますが、定常的に我々はさまざまなチームがより細かい粒度で予測を実装し、狭くなり続ける時間ウィンドウでより頻繁に予測をデリバリーしていることを目撃しています。
これは困難であるように聞こえるかもしれませんが(数年前はそうでした!)、技術の進歩とクラウドの利用によって、デリバリーがより容易になっています。Databricksにおいて我々は、数千万の予測を生成しているお客様に定常的に遭遇しており、多くの場合、時間ウィンドウは一日あたり1時間、2時間を超えることがありません。入力データの高速処理は重要なことですが、本当に重要なのはこれらのプロセスで必要となるモデルを迅速にトレーニングするために必要な数百、時には数千の仮想コアをかき集めることです。
クラウド以前の世界では、そのようなリソースを利用できるかどうかは、予測の生成に必要な狭い時間ウィンドウ以外はアイドル状態となっているデータセンターの高価なサーバーに投資を行う企業の意思に依存していました。ごく一部の人たちだけが費用の正当性を主張することができました。
しかし、クラウドが力学を変化させました。計算資源を所有するのではなく、必要な数分間だけレンタルすれば良いのです。Databricksを活用することで、企業は今では彼らの需要予測サイクルに応じてクイックにリソースを配備、廃棄することができ、タイムリーかつコスト効率が高い方法で必要な結果をデリバリーするのに必要な膨大なキャパシティを活用できるようになりました。
きめ細かい予測は多くの場合において需要の断続的なパターンを生じさせます
きめ細かい需要予測における計算資源の制約を取り払うことで、企業は自分達がオペレーションをおこなっているレベルで正確に予測をデリバリーすることができるようになっています。これには、局所的なレベルにおける正確な需要パターンをキャプチャする予測のデリバリーに関する計り知れないポテンシャルがあります。しかし、多くの場合、これには断続的な需要のパターンも含まれます。
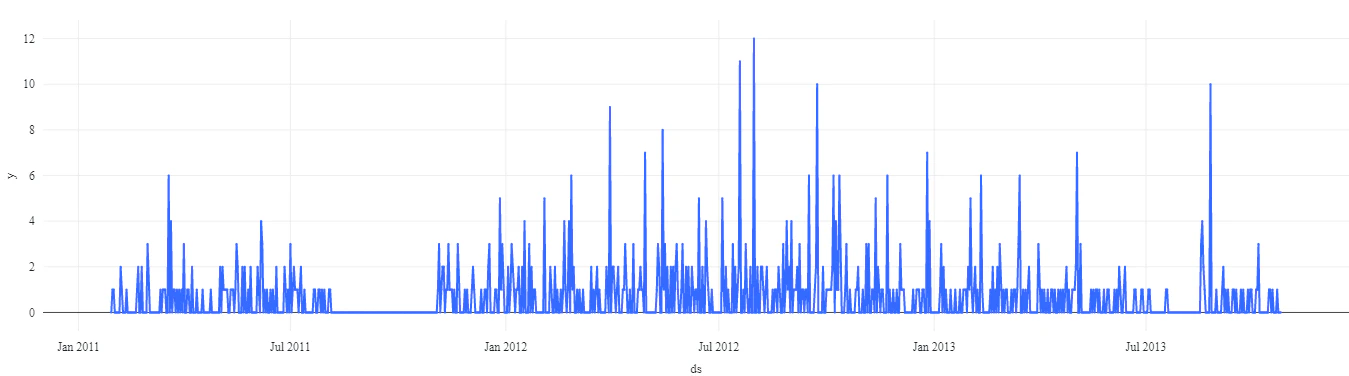
図1. 特定の店舗における特定商品SKUの断続的な需要
簡単に言うと、すべての製品がすべての場所で毎日売れている訳ではありません。この問題は多くの場合、集計データではマスクされてしまいますが、より詳細な粒度に移行するとこれらの極初期的な期間の不活性状態が頻繁に出現するようになります。
断続的需要を難しいものにしているのは、多くの場合、特定のユニットが売れるかどうかを決定づける要素である、いわゆる今日対明日がデータからキャプチャできないと言うことです。そうではなく、より広範な期間におけるユニットの割合を検証し、特定の日付でこれらのユニットのいくかが売れる確率の推定にフォーカスする必要があります。
これは、多くの企業がこれまでベースとしていたモデルで適用されているものとは非常に異なる時系列予測のアプローチです。これらのモデルは、多くの場合データをハイレベルのトレンド、季節性、繰り返しのパターンをキャプチャする要素に分解することで、特定の日において移動が予測される正確なユニットの予測にフォーカスしています。これらの要素は多くの場合、まばらに存在する時系列データでは効率的に推定することができず、これらのアプローチやこのアプローチを中心としているソフトウェアパッケージをこのレベルの粒度で利用できなくしてしまっています。
特別なテクニックを用いて断続的な需要をモデリングする必要があります
断続的需要の予測モデルは1970年代から存在していました。しかし、学術界や実践者はマクロレベルの計画に必要とされる高レベルの予測にエネルギーを注いでおり、そして、当時の計算能力の制限から、この領域は多くのケースでエッジケースとして取り扱われていました。このため、これらのモデルへのアクセスは、数多くのワンオフのライブラリや、さまざまな予測コミュニティのビジョンから大きくかけ離れたソフトウェアパッケージに限定され続けてきました。Nixtlaにようこそ。

図2. Nixtla予測エコシステム
Nixtlaは、一貫性があり使いやすい方法で広範な予測の能力を活用できるようにすることを目的とした一連のライブラリです。散在しているソフトウェアパッケージから必要な機能を探し出すことにフラストレーションを感じている実践者によって開発されており、Nixtlaでは標準化とパフォーマンスに重きを置いており、企業は断続的需要の予測を含む現実世界の予測の問題を比較的簡単に解くことが可能となります。
多くの企業がクラウドを活用してタイムリーな方法で膨大な数の予測を生成しようとしていることを知り、NixtlaはFugueエンジンとして知られる高性能、自動スケールアウトエンジンをライブラリに組み込みました。Databricksと組み合わせることで、企業は高速かつコスト効率が高い方法で膨大なボリュームの予測結果を生成できるようになります。
NixtlaとDatabricksによる断続的な需要の予測のデモンストレーション
NixtlaとDatabricksによる大規模な断続的需要の予測をデモンストレーションするために、Walmartによって提供されているM5データセットの一部として含まれている3万以上の店舗・アイテムの組み合わせのそれぞれに対する予測を行うために、一連のノートブックを開発しました。データセットのそれぞれの店舗・アイテムは日次レベルの断続的需要パターンを含む時系列を表現しています。それぞれの時系列の(平均)68%の日付ではユニットが売れていません。
このノートブックでは、複数のテクニックを用いてこれらのアイテムのそれぞれの予測をどのように生成するのかをデモするだけではなく、それぞれの店舗・アイテムの組み合わせでベストな予測に到達するために、企業がモデルのタイプから最適なものを見つけ出すために、どのように自動化できるのかも説明します。また、どのようにして、企業がより堅牢かつ大規模な予測評価を行えるのかを理解できるようにするために、時系列の交差検証のような高度なテクニックも紹介します。
このデモンストレーションが、皆様の企業において依存性のあるサプライチェーンプロセスを改善するための需要予測の生成に至る新たな道を探索し、サプライチェーンの近代化への次の一歩を踏み出す助けになればと考えています。
詳細を学ぶためにノートブックをダウンロードするには、需要予測ソリューションアクセラレータをチェックしてください。