Deep Dive into Spark SQL's Catalyst Optimizer - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2015年の記事です。
Spark SQLはSparkで最も最新かつ技術的に関連の深いコンポーネントの一つです。SQLクエリーと新たなデータフレームAPIの両方を強化します。Spark SQLのコアは、拡張可能なクエリーオプティマイザーを構築するために洗練された方法で高度なプログラミング言語の機能(Scalaのパターンマッチングや準クォート(Quasiquotes)など)を活用するCatalystオプティマイザーです。
我々は最近SIGMOD 2015でSpark SQLに関する論文を発表(Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsiとの共著)しました。このブログ記事では、様々な形で利用されるCatalystオプティマイザーの内部原理を説明する論文のセクションを再訪します。
Spark SQLを実装するために、Scalaの機能的プログラミング構造に基づく新たな拡張可能なCatalystオプティマイザーを設計しました。Catalystの拡張可能なデザインには2つの目的がありました。第一に、特にビッグデータに関連する様々な問題(準構造化データや高度な分析)に取り組むために、Sparkに新たな最適化テクニックや機能を容易に追加できるようにしたいと考えました。第二に、例えば、外部のストレージシステムにフィルタリングや集計処理をプッシュしたり、新たなデータタイプをサポートできるデータソース固有のルールを追加したりすることで、外部の開発者がオプティマイザーを拡張できるようにしたいと考えました。Catalystはルールベース、コストベース両方の最適化をサポートしています。
コアとして、Catalystにはツリーを表現し、それらを操作するためにルールを適用できる汎用ライブラリが含まれています。このフレームワークの上に、リレーショナルなクエリー処理(エクスプレッションや論理的クエリープランなど)に特化したライブラリ、そして、クエリーのパーツをJavaのバイトコードにコンパイルするための、解析、論理的最適化、物理的プランニング、コードジェレーションといったクエリー実行における異なるフェーズを取り扱ういくつかのルールセットを構築しました。後者に関しては、Scalaの機能である準クォートを活用し、合成可能なエクスプレッションから実行時コードを容易に生成できるようにしました。最後に、Catalystは外部データソース、ユーザー定義型を含むいくつかの公開拡張ポイントを提供します。
ツリー
Catalystにおける主要なデータタイプはノードオブジェクトから構成されるツリーです。それぞれのノードには、ノード型と0以上の子要素があります。新たなノードタイプは、ScalaでTreeNodeのサブクラスとして定義されます。これらのオブジェクトは不変であり、次のサブセクションで議論するように機能的変換を用いて操作されます。
シンプルな例として、非常にシンプルな表現言語とに対する以下の3つのノードクラスがあるとします。
- Literal(value: Int): 定数値
- Attribute(name: String): 入力行の属性(xなど)
- Add(left: TreeNode, right: TreeNode): 二つの表現の和
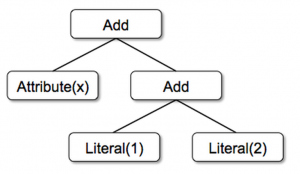
これらのクラスはツリーの構築に使用されます。例えば、x+(1+2)という表現はScalaで以下のように表現されます。
Add(Attribute(x), Add(Literal(1), Literal(2)))
ルール
ツリーから別のツリーを返す関数であるルールを用いてツリーを操作することができます。ルールは、入力のツリーに対して任意のコードを実行することができますが、最も一般的なアプローチは、サブツリーを検索し、特定の構造でサブツリーを置き換えるために一連のパターンマッチングを用いるというものです。
パターンマッチングは代数データ型のネストされた構造から値を抽出できる数多くの関数的言語です。Catalystでは、ツリーのすべてのノードに対して再帰的にパターンマッチング関数を適用し、それぞれのパターンにマッチしまたものを結果に変換する変換メソッドを提供します。例えば、以下のように定数間にAddオペレーションを適用するルールを実装することができます。
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
}
x+(1+2)のツリーにこれを適用することで、x+3を得ることができます。ここでのcaseキーワードは、Scalaの標準的なパターンマッチング構文であり、値を抽出するためにオブジェクトの名前(ここではc1とc2)とオブジェクトの型に対してマッチングを行うために使用することができます。
変換に指定されるパターンマッチングの表現は部分的関数であり、とり得るすべての入力ツリーのサブセットにのみマッチすればいいことを意味します。Catalystはツリーのどの部分にルールを適用するのかをテストし、マッチしない下流のサブツリーにスキップしていきます。この能力によって、指定された最適化が適用されるツリーに対してのみルールを適用し、マッチしないものに関してはルールを適用しないことが可能となります。このため、新たタイプのオペレーターがシステムに追加されてもルールを編集する必要はありません。
ルール(と一般的にはScalaのパターンマッチング)は同じ変換処理の呼び出しの中で複数のパターンにマッチすることができ、一度に複数の変化処理するさいに非常にシンプルになります。
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
case Add(left, Literal(0)) => left
case Add(Literal(0), right) => right
}
実際には、ルールは完全にツリーを変換する際には複数回実行する必要がある場合があります。Catalystはルールをバッチにグルーピングし、固定ポイントに到達するまで、すなわち、ルールを適用した後のツリーが変化を止めるまでそれぞれのバッチを実行します。固定ポイントまでのルールの実行は、それぞれのルールがシンプルで自己完結的でありながらも、最終的にはツリー全体に影響を及ぼすことを意味します。上の例では、繰り返されるアプリケーションは(x+0)+(3+3)のように固定倍の大規模なツリーになり得ます。別の例として、最初のバッチがすべての属性にタイプを割り当てる表現を解析し、2つ目のバッチが定数量の処理を行う際にこれらのタイプを使用するというものがあります。それぞれのバッチの後では、開発者は新たなツリーに対して、多くの場合では再帰的マッチングを通じたサニティチェック(すべての属性に型が割り当てられていることを確認するなど)を行うことができます。
最後に、ルールの条件と本体には、任意のScalaコードを含めることができます。これによって、Catalystはシンプルなルールによる簡潔性を持ちつつも、オプティマイザー向けのドメイン固有言語よりも優れた力を手に入れることができます。
我々の経験では、不変のツリーに対する関数的変換は、オプティマイザーを理解しデバッグしやすいものにします。また、まだ活用していませんが、これらはオプティマイザーにおける並列化を可能にします。
Spark SQLでのCatalystの使用
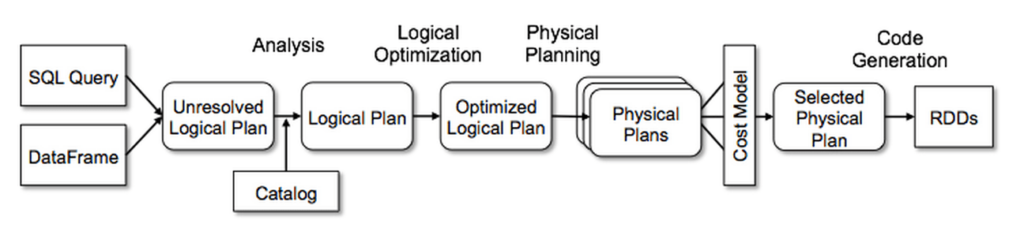
以下のようにCatalystの汎用ツリー変換フレームワークを4つのフェーズで使用します。
- 参照関係を解決するために論理的プランを解析
- 論理的プランの最適化
- 物理的プランニング
- クエリーのパーツをJavaバイトコードにコンパイルするためのコードジェネレーション
物理的プランニングのフェーズでは、Catalystは複数のプランを作成し、コストに基づいて比較を行う場合があります。他の全てのフェーズは純粋にルールベースとなります。それぞれのフェーズでは、異なるタイプのツリーノードを使用します。Catalystには、エクスプレッション、データタイプ、論理的、物理的オペレーターのライブラリが含まれています。以降でそれぞれのフェーズを説明していきます。
解析
Spark SQLは、SQLパーサーから返却されるabstract syntax tree (AST)、あるいはAPIを用いて構築されるデータフレームオブジェクトから得られる計算するリレーションからスタートします。両方のケースで、リレーションに解決されていない属性参照やリレーションが含まれている場合があります。例えば、SQLクエリーSELECT col FROM salesでは、colの型、あるいは適切なカラム名なのかどうかは、salesテーブルを参照するまではわかりません。型が不明、入力テーブル(あるいはエイリアス)とマッチングしていない場合には属性は未解決(unresolved)と呼ばれます。Spark SQLはこれらの属性を解決するためにルールと、すべてのデータソースにおけるテーブルを追跡するカタログオブジェクトを使用します。属性とデータ型が紐づけられていない「未解決論理的プラン」ツリーからスタートし、以下の処理を行うルールを適用します。
- 名前を用いてカタログからリレーションを検索
-
colのような名前付き属性を、指定されたオペレーターの子要素の入力にマッピング - ユニークなID(あとで
col = colのような表現の最適化を実現します)を与えるために、どの属性が同じ値を参照しているのかを判断 - エクスプレッションを通じた型の伝播および強制。例えば、
colを解決するまでは1 + colの型を知ることができず、場合によっては互換性のある型にサブ表現をキャストする場合があります。
全体として、アナライザーのルールは1000行程度のコードになります。
論理的最適化
論理的最適化のフェーズでは、論理的プランに標準的なルールベースの最適化を適用します。(ルールを用いて複数のプランを生成することで、コストベースの最適化が行われます。)これらには定数のフォールディング、述語のプッシュダウン、プロジェクションの刈り込み、nullの伝播、ブーリアン表現のシンプル化などが含まれます。一般的に、多くのシチュエーションでルールを追加することは非常にシンプルであることを見出しました。例えば、Spark SQLに固定精度のDECIMALタイプを追加する際、DECIMALとより精度の低いものに対するsumやaverageのような集計処理を最適化したいと考えました。SUMやAVGエクスプレッションのdecimalを見つけ出し、それらをスケールされていない64bitのLONGにキャストし、集計を行い、結果をキャストし直すためには12行のコードを必要としただけでした。このルールをシンプルにしたバージョンのSUMのエクスプレッションは以下のようになります。
object DecimalAggregates extends Rule[LogicalPlan] {
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case Sum(e @ DecimalType.Expression(prec, scale))
if prec + 10 <= MAX_LONG_DIGITS =>
MakeDecimal(Sum(UnscaledValue(e)), prec + 10, scale) }
}
別の例として、シンプルな正規表現を用いたLIKEエクスプレッションを、String.startsWithやString.containsを用いた12行のコードで最適化しました。ルールで任意のScalaコードを使える自由度によって、サブツリーの構造をパターンマッチングする以上のこの種の最適化を表現しやすくします。
物理的プランニング
物理的プランニングフェーズでは、Spark SQLは論理的プランを受け取り、Spark実行エンジンと一致する物理的オペレーターを用いて1つ以上の物理的プランを生成します。そして、コストモデルを用いてプランを選択します。この時点では、joinアルゴリズムを選択するために、コストベースの最適化のみが用いられます。小規模であることを知っているリレーションに対して、Spark SQLはSparkで利用できるピアツーピアのbroadcastを用いてbroadcast joinを使用します。このフレームワークはより広範なコストベースの最適化をサポートしていますが、全体的なコストはルールを用いて再帰的に推定されます。このため、将来的にはより豊富なコストベースの最適化を実装するつもりです。
また、物理的プランナーはパイプラインプロジェクションやSparkのmapオペレーションに対するフィルタリングのようなルールベースの物理的最適化も実行します。さらに、論理的プランを述語、プロジェクションプッシュダウンをサポートするデータソースにプッシュすることも可能です。以降のセクションでこれらデータソースに対するAPIを説明します。
全体として、物理的プランニングのルールは約500行のコードになります。
コードジェネレーション
クエリー最適化の最後のフェーズには、それぞれのマシンで実行するJavaバイトコードの生成が含まれます。Spark SQLは多くの場合、CPUを必要とする処理を行うインメモリのデータセットを操作するので、処理を高速化するためのコードジェネレーションをサポートしたいと考えました。しかしながら、多くの場合コードジェネレーションエンジンは、主にコンパイラーのために構築が複雑なものとなります。Catalystはコードジェネレーションをよりシンプルなものにするために、Scala言語の特殊な機能である準クォートを活用しています。準クォートを用いることで、バイトコードを生成するために実行時にScalaコンパイラーに入力されるScala言語におけるabstract syntax tree(AST)のプログラムによる構築が可能となります。エクスプレッションを評価し、生成されたコードをコンパイル・実行するために、SQLのエクスプレッションを表現するツリーをScalaコードのASTに変換するためにCatalystを使用します。
シンプルな例として、上のセクションで紹介した(x+y)+1のようなエクスプレッションを記述できるAdd、Attribute、Literalのツリーを考えてみます。コードジェネレーションがない場合、このようなエクスプレッションはAdd、Attribute、Literalのツリーを下っていくことで、データの行ごとに解釈される必要があります。これは、実行を遅くさせる大量の枝と仮想的な関数呼び出しを引き起こします。コードジェネレーションを用いることで、以下のように特定のエクスプレッションツリーをScalaのASTに翻訳する関数を記述することができます。
def compile(node: Node): AST = node match {
case Literal(value) => q"$value"
case Attribute(name) => q"row.get($name)"
case Add(left, right) => q"${compile(left)} + ${compile(right)}"
}
qで始まる文字列は準クォートであり、文字列のように見えますが、これらはコンパイル時にScalaコンパイラでパースされ、コード内でASTを表現することを意味します。準クォートでは、$ノーテーションを用いることで変数や他のASTを組み合わせることができます。例えば、Literal(1)は1に対するScala ASTとなり、Attribute("x")はrow.get("x")になります。最終的には、Add(Literal(1), Attribute("x"))のようなツリーは1+row.get("x")のようなScalaのAST表現になります。
準クォートは適切なASTやリテラルのみで置き換えられることを保証するために、コンパイル時に型チェックを行いますので、文字列結合よりもはるかに使いやすいものとなり、実行時にScalaのパーサーを実行するのではなく、直接ScalaのASTに変換されます。さらに、それぞれのノードに対するコードジェネレーションは、小要素によって返却されるツリーがどのような構成であるのかを知る必要がないので、構築が非常に容易です。最後に、Catalystが見逃したエクスプレッションレベルの最適化が存在する場合、Scalaコンパイラーによって結果のコードがさらに最適化されます。以下の図では、準クォートを用いることで、手でチューニングしたプログラムと同等のパフォーマンスを発揮できることを示しています。
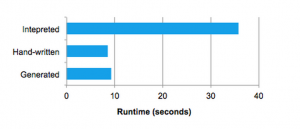
我々はコードジェネレーションに準クォートを用いることは非常にわかりやすいことを知り、Spark SQLの新たなコントリビュータであっても新たなタイプのエクスプレッションをクイックに追加できることを知りました。また、準クォートはネイティブのJavaオブジェクトを実行するというゴールとも適合します。これらのオブジェクトからフィールドにアクセスする際、オブジェクトをSpark SQLのRowにコピーし、Rowのアクセサメソッドを使用する必要なしに、直接必要なフィールドにアクセスするコードを生成することができます。最後に、コンパイルするScalaコードは直接我々のエクスプレッションインタプリタを呼び出せるので、まだ生成していないコードのエクスプレッションに対するインタプリタの評価結果とコード生成された評価を組み合わせることは非常にわかりやすいこととなります。
全体として、Catalystのコードジェネレーターは約700行のコードとなります。
このブログ記事では、Spark SQLのCatalystオプティマイザーの内部原理をカバーしました。非常に洗練され、シンプルなデザインによって、Sparkコミュニティがクイックにプロトタイプ、実装、エンジンの拡張を行うことを可能にしました。こちらの論文の残りの部分をチェックすることもできます。今年のSIGMODに参加するのであれば、我々のセッションに立ち寄ってください!
以下の記事からSpark SQLに関する詳細を知ることができます。
- Apache SparkのSpark SQL and DataFrame Programming Guide
- Yin HuaiによるData Source API in Sparkのプレゼンテーション
- Reynold XinによるIntroducing DataFrames in Spark for Large Scale Data Science
- Michael ArmbrustによるBeyond SQL: Speeding up Spark with DataFrames