How to Share and Control ML Model Access with MLflow Model Registryの翻訳です。
注意
この記事は2020/4に執筆されたものであるため、一部最新の情報で更新しています。
DatabricksのMLflowモデルレジストリにおけるエンタープライズレベルの新機能を発表できることを嬉しく思います。今やモデルレジストリは、Databricksレイクハウスプラットフォームをお使いの皆様においては、デフォルトで有効化されます。
この記事では、モデル管理における集中管理ハブとしてのモデルレジストリのメリット、どのようにしてデータチームが組織内でモデルを共有し、モデルに対するアクセスコントロールを行うのか、そして、インテグレーションや検査のためにどのようにモデルレジストリAPIを使うのかに関して説明します。
コラボレーティブモデルライフサイクル管理のための集中管理ハブ
MLflowにはすでにエクスペリメントの一部としてメトリクス、パラメーター、アーティファクトをトラッキングする機能、モデルと再現可能なMLプロジェクトをパッケージングする機能、バッチあるいはリアルタイムでサービングするプラットフォームの機能があります。これらの既存の機能に加えて、MLflowのモデルレジストリ[AWS] [Azure]は、モデルデプロイメントのライフサイクルを管理する中央リポジトリを提供します。
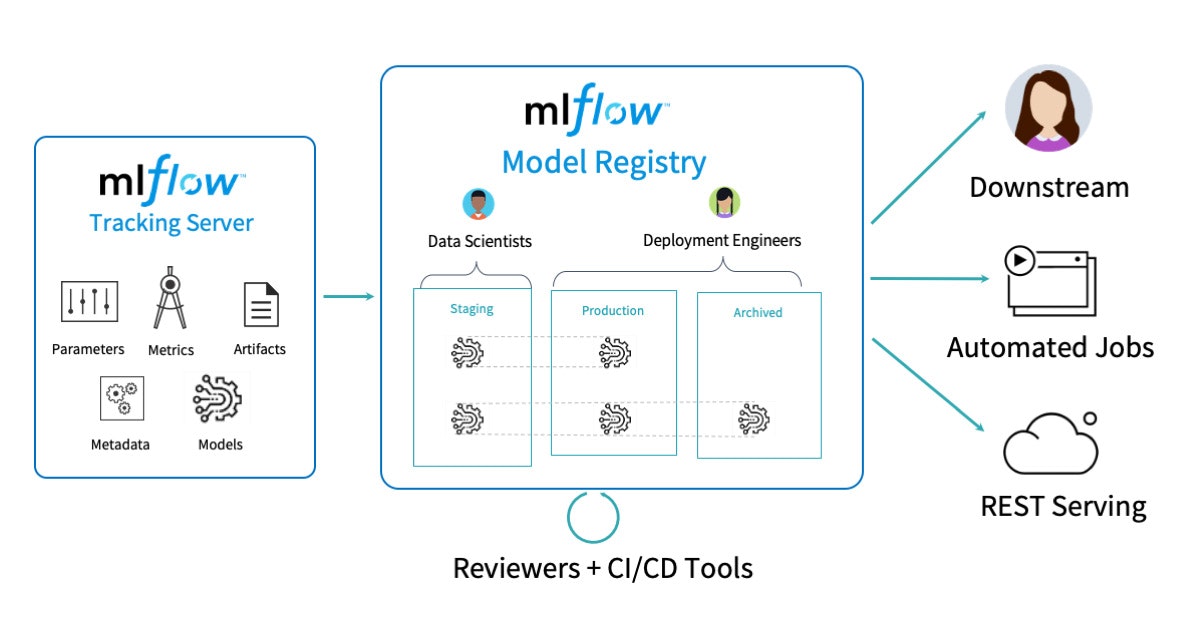
モデル管理のためのCI/CDツール、MLflow集中管理ハブのアーキテクチャおよびワークフローの概要
大企業におけるデータサイエンティストが直面する主要な課題の一つは、コラボレーションし、コードを共有し、モデルのデプロイメントのステージ変更、モデルのバージョン管理、モデルの履歴管理を行うための中央リポジトリが存在しないことです。企業全体で利用できるモデルの集中管理されたレジストリは、データチームに以下の機能を提供します。
- 登録されたモデル、モデルデプロイメントの現在のステージ、エクスペリメントのラン(モデルのトレーニング)、登録されたモデルに関連づけられたコードの検索容易性
- モデルに対するデプロイメントのステージへの遷移
- 登録されたモデルの異なるバージョンを異なるステージにデプロイできるので、MLOpsエンジニアは異なるモデルバージョンに対してテストおよびデプロイが可能
- 履歴保持のために古いモデルをアーカイブ
- モデルのライフサイクルにおけるアクティビティ、アノテーションの詳細を記録
- モデル登録、ステージ変更、モデル変更に対するきめ細かいアクセスコントロール
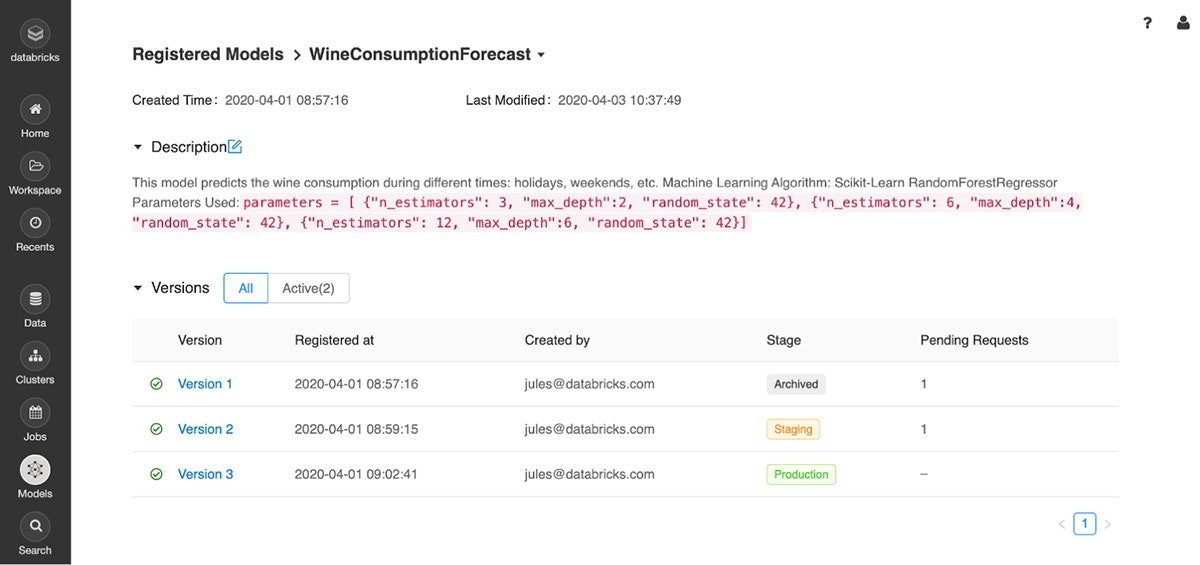
モデルレジストリがモデルのライフサイクルにおいて異なるステージにあるそれぞれのバージョンを表示
モデルステージ管理に対するアクセスコントロール
近年のデータ、機械学習のイノベーションにおいて、モデルはビジネス戦略においてかけがえのない資産となりました。ビジネス上の問題を解決するためのソリューションの一部としてのモデルは、機械の故障予測から電力消費、財務パフォーマンスの予測、不正、異常検知から購入した商品に関連するアイテムの提案まで多岐に渡ります。
センシティブなデータを取り扱う際には、トレーニングやスコアリングを行うためにそのデータを取り扱うモデルにおいても、許可されたユーザーのみがモデルにアクセスできるようにするために、アクセスコントロールリスト(ACL)が必須となります。一連のACLを通じて、データチームの管理者は、モデルのライフサイクルを通じて、モデルに対するオペレーションに対するきめ細かいアクセス制御を行うことができ、不適切なモデルの使用や、許可されないモデルの本格運用への投入を防ぐことができます。
Databricksのレイクハウスプラットフォームにおいては、Databricksのアクセスコントロール、アクセス権モデル[AWS][Azure]に従って、登録された個々のモデルに対してアクセス権を設定することができます。
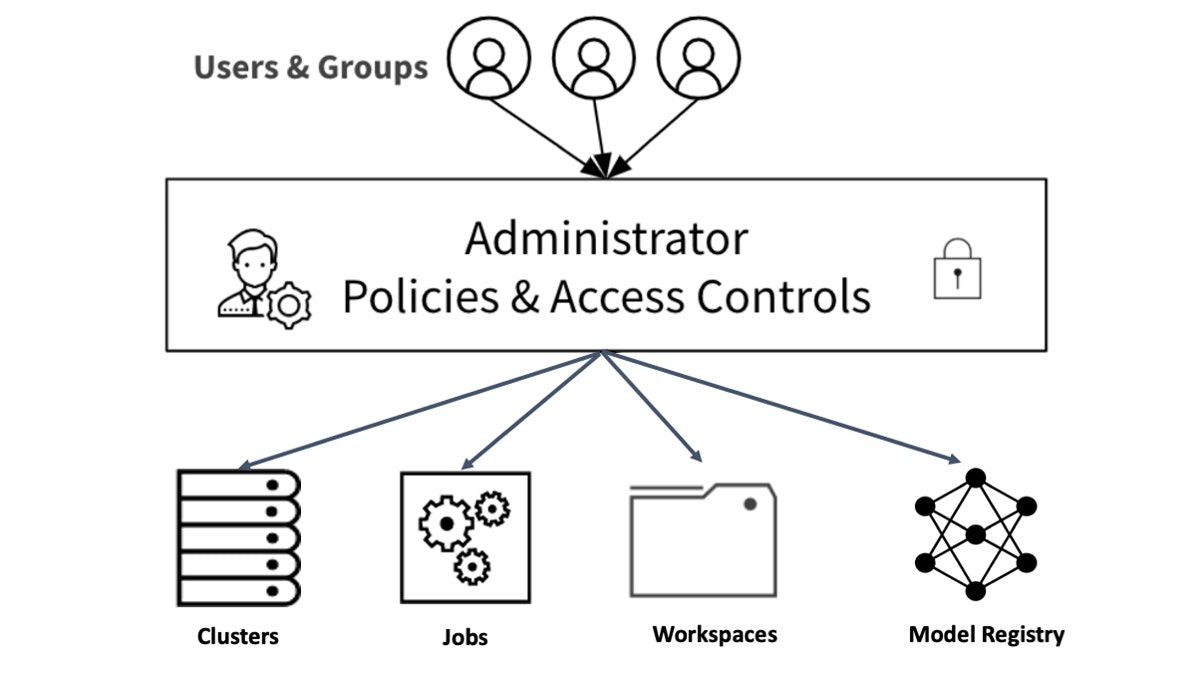
Databricksアセットに対するアクセスコントロールのポリシー
DatabricksワークスペースのRegistered Models UIにおいて、ノートブックやクラスターと同じように、ユーザーとグループに対して登録されたモデルに対する適切なアクセス権を設定することができます。
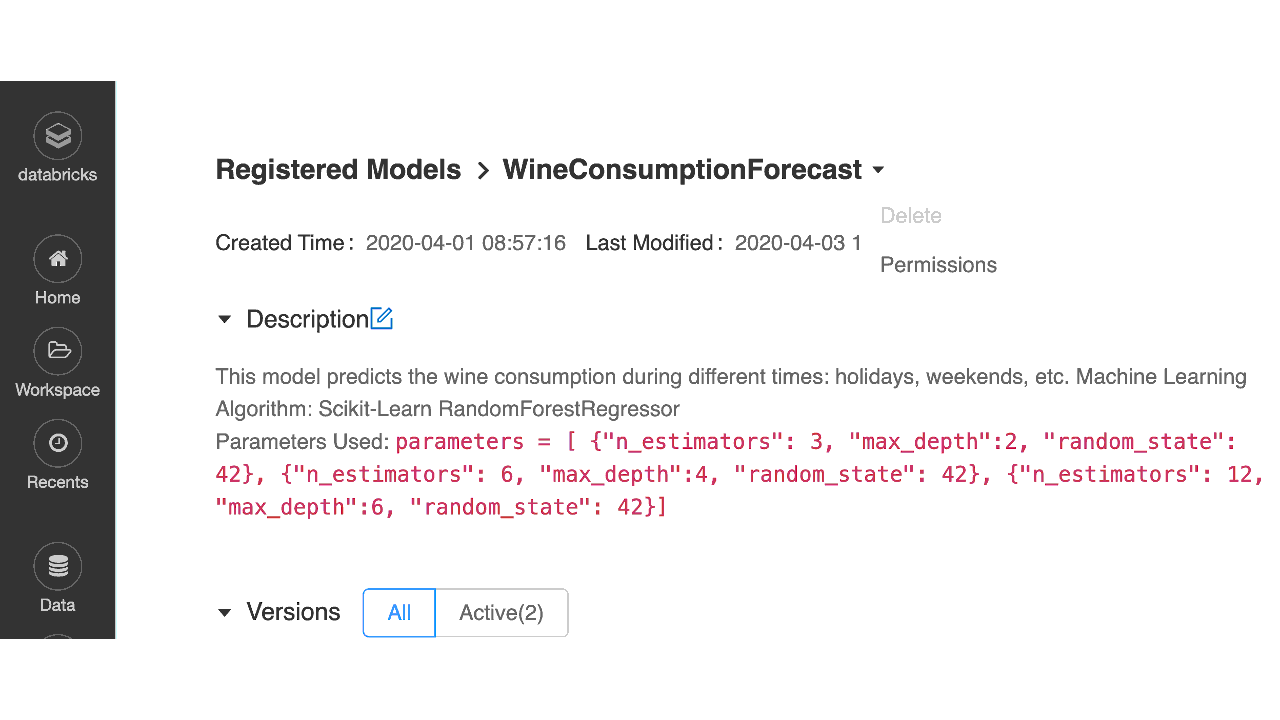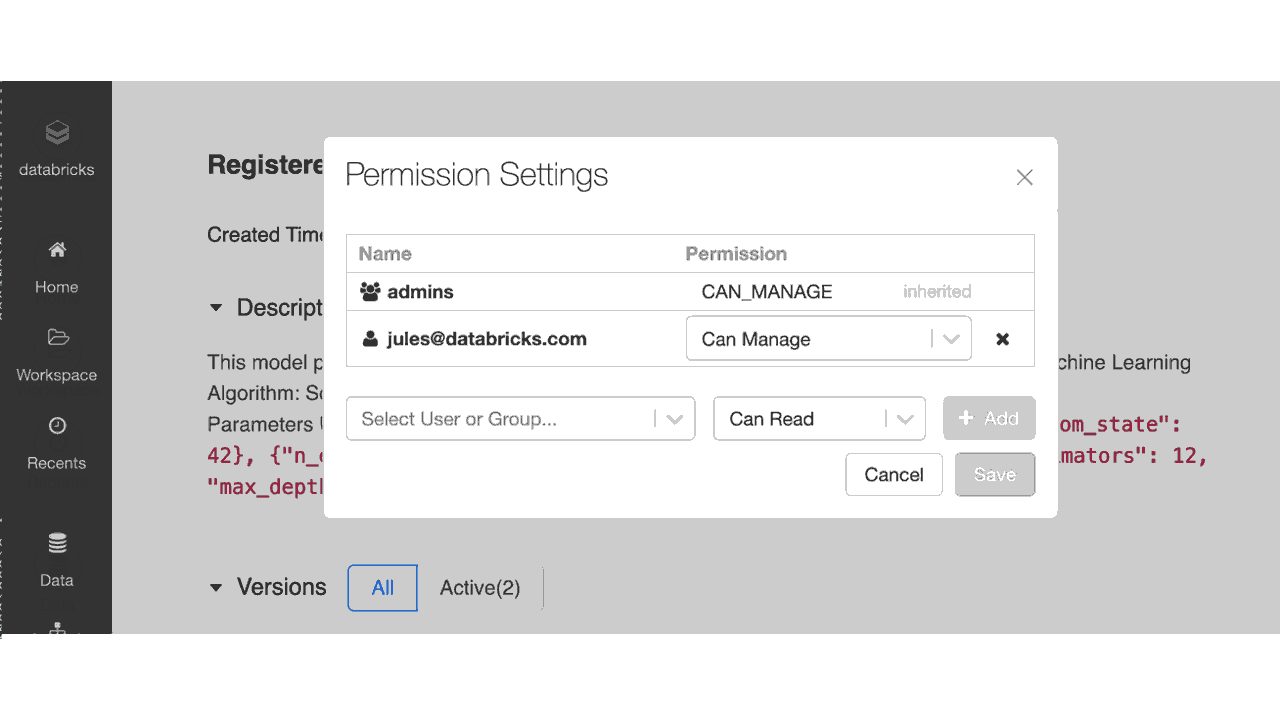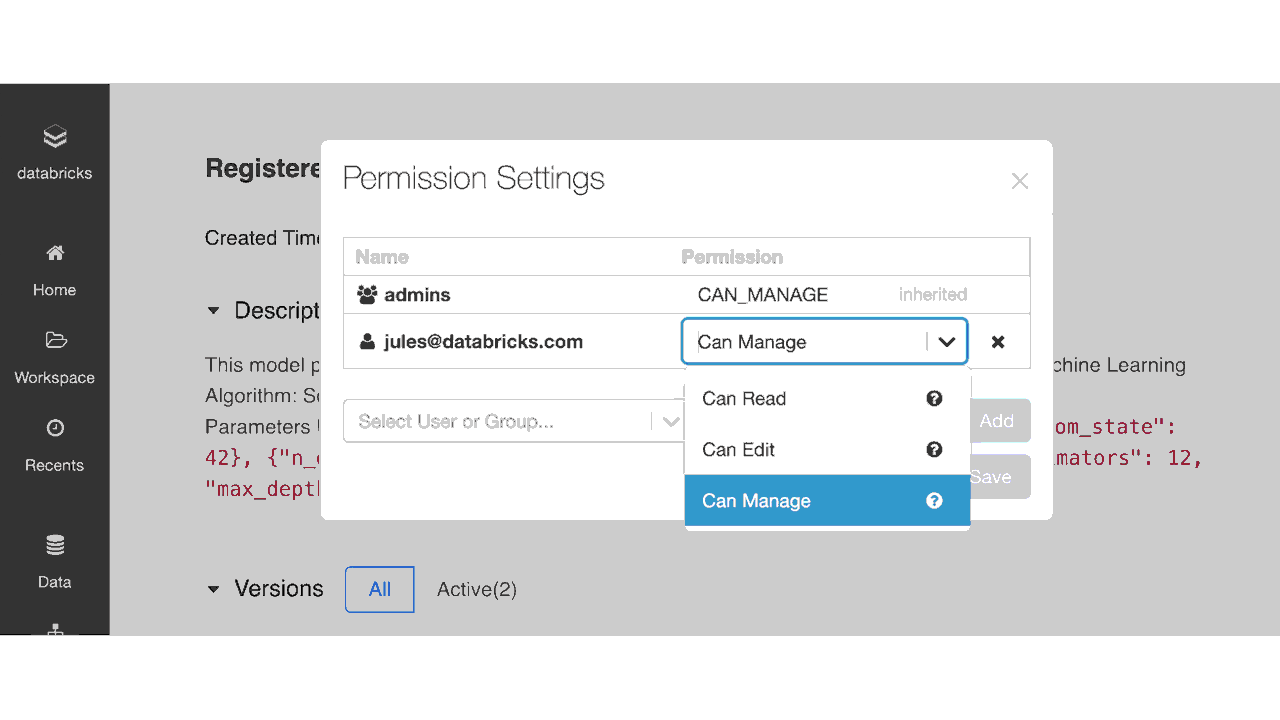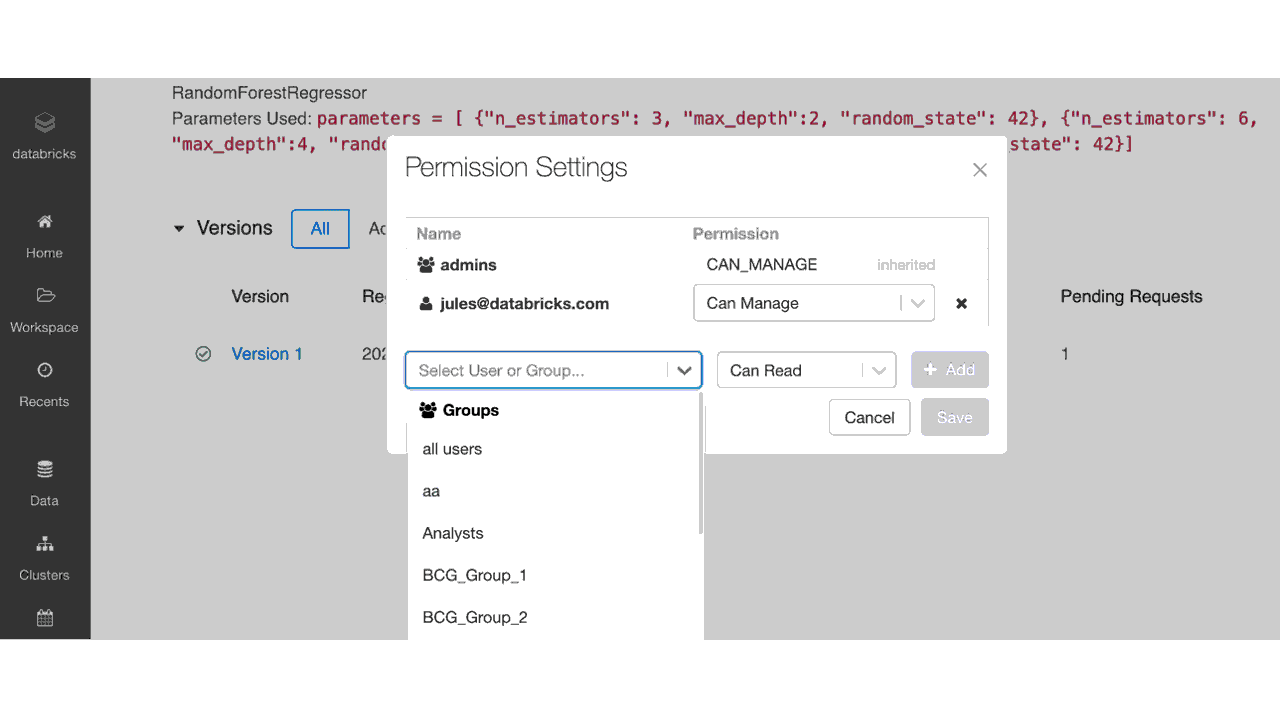
ACLを用いたモデルレジストリUIにおけるアクセス権の設定
以下の表に示すように、管理者はモデルレジストリに登録されたモデルに対して6つのレベルのアクセス権を設定できます:No Permissions(アクセス権なし)、Read(読み取り)、Edit(編集)、Manage Staging Versions(ステージングバージョンの管理)、Manage Production Versions(プロダクションバージョンの管理)、Manage(管理)です。以下のテーブルに権限ごとにできることを示します。
| できること| No Permissions | Read | Edit | Manage Staging Versions | Manage Production Versions | Manage |
|:--|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|モデルの作成 |x |x |x |x |x |x |
|モデル詳細、バージョン、ステージ変更リクエスト、アクティビティ、アーティファクトダウンロードURIの表示 | | x |x |x |x |x |
|モデルバージョンステージ変更依頼 | | x | x | x | x | x |
|新バージョンのモデルの追加 | | | x | x | x | x |
|モデルの記述更新 | | | x | x | x | x |
|モデルのステージング状態の変更 | | | | x(None/Archived/Stagingのみ) | x | x |
|モデルのステージング状態変更リクエストの承認・却下 | | | | x(None/Archived/Stagingのみ) | x| x |
|モデルのステージング状態変更リクエストのキャンセル(注意) | | | | | | x |
|アクセス権の変更 | | | | | | x |
|モデル名の変更 | | | | | | x |
|モデル及びバージョンの削除 | | | | | | x |
モデルレジストリにおけるアクセス権(訳者注:2021/8時点のものに更新しています)
モデルレジストリの使い方
一般的には、データサイエンティストは多くのエクスペリメントを実施し、メトリクスとパラメーターをトラッキングする数多くのランが生成されます。この開発サイクルの過程で、実施したエクスペリメントからベストなものを選択し、モデルをレジストリに登録します。その後、レジストリを用いることで、データサイエンティストは、それぞれのバージョンをモデルのライフサイクルステージに割り当てることで、複数のバージョンのモデルが今どのステージ(Staging、Production、Archived)にあるのか追跡できるようになります。
MLflowのモデルレジストリを操作する方法は2つあります[AWS][Azure]。Databricksワークスペースに統合されたモデルレジストリのUIによる方法と、MLflowトラッキングクライアントAPIを用いる方法です。後者を用いることで、テストやモデルのランやメタデータを検査するために、MLOpsエンジニアが登録されたモデルをCI/CDツールとインテグレーションできるようにします。
モデルレジストリUIのワークフロー
モデルレジストリのUIにはDatatbricksのワークスペースからアクセスできます。モデルレジストリUIでは、ワークフローの一部として以下のアクションを行うことができます。
- ランのページからモデルを登録
- 特定バージョンのモデルに対する説明文の編集
- 特定バージョンのモデルのステージ遷移
- 特定バージョンのモデルにおけるアクティビティ、アノテーションの参照
- 登録されたモデルの検索、表示
- 特定バージョンのモデルの削除
モデルレジストリAPIのワークフロー
モデルレジストリを操作する別の方法は、MLflowモデルフレーバーやMLflowクライアントトラッキングAPIインタフェースを使用する方法です。上のUIのワークフローで述べたように、APIを介して登録されたモデルに対して同じオペレーションを行うことができます。モデルの夜間テストを行うために、外部ツールと連携したり検証を行う際にAPIは有用です。
モデルレジストリからモデルをロード
モデルレジストリAPIを用いることで、モデルをテストするために、Jenkinsのようなお使いの継続的インテグレーション/継続的デリバリー(CI/CD)ツールとインテグレーションすることができます。例えば、ユニットテストにおいて、上述の通り適切にアクセス権が設定されていれば、テストのために、あるバージョンのモデルをロードすることができます。
以下のコードスニペットにおいては、同じモデルの二つのバージョン:ステージングにあるバージョン3とプロダクションにある最新バージョンをロードしています。
import mlflow.sklearn
# Load version 3 with model://URI as argument
model_version_uri = "models:/{model_name}/3".format(model_name="scikit-learn-power-forecasting-model")
model_version_3 = mlflow.sklearn.load_model(model_version_uri)
これで、テストのためにJenkinsがステージングにあるバージョン3のモデルにアクセスできます。プロダクションの最新バージョンをロードしたい場合には、単にモデルのURIでプロダクションモデルを指定すれば良いのです。
# Load the model in production stage
model_production_uri = "models:/{model_name}/production".format(model_name="scikit-learn-power-forecasting-model")
model_production = mlflow.sklearn.load_model(model_production_uri)
Apache Sparkジョブとの連携
開発(CI/CD)ツールとの連携に加え、レジストリからモデルをロードし、Sparkのバッチジョブで使用することもできます。一般的なシナリオは、登録されたモデルをSparkのUDF(ユーザー定義関数)としてロードするというものです。
# Load the model as a Spark udf
import mlflow.pyfunc
batch_df = spark.read.parquet()
features = ['temperature', 'wind-speed', 'humidity']
pyfunc_forecast_udf = mlflow.pyfunc.spark_udf(spark, model_production_uri)
prediction_batch_df = batch_df.withColumn("prediction",
pyfunc_forecast_udf(*features))
登録されたモデルの情報を調査、一覧、検索
時には、モデルに関するMLflowエンティティ情報を調査するために、登録されたモデルの情報をプログラミングインタフェース経由で調査したいケースがあるかもしれません。例えば、シンプルなメソッドととバージョン情報に対するイテレーションで、レジストリに登録されている全てのモデルのリストを取得することができます。
client = MlflowClient()
for rm in client.list_registered_models():
print(f"name={rm.name}")
[(print(f"run_id={mv.run_id}"), print(f"status={mv.current_stage}"),
print(f"version={mv.version}")) for mv in rm.latest_versions]
アウトプットは以下のようになります。
name=sk-learn-random-forest-reg-model
run_id=dfe7227d2cae4c33890fe2e61aa8f54b
current_stage=Production
version=1
...
...
数百のモデルにおいては、この呼び出しの結果の精査、あるいは出力に手間がかかるかもしれません。より効率的なアプローチは、search_model_versions()メソッドに"name='sk-learn-random-forest-reg-model'"のような検索条件を指定し、特定のモデル名とバージョン情報で検索を行うことでしょう。
client = MlflowClient()
for mv in client.search_model_versions("name='sk-learn-random-forest-reg-model'"):
pprint(dict(mv), indent=4)
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees'
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': jane@doe.ml,
'version': 1}
...
要約すれば、すべてのDatabricks利用者に対して、MLflowモデルレジストリがデフォルトで利用可能になったということです。MLモデルの集中管理ハブとして、コラボレーション、モデル共有、ステージの管理、リネージュの注釈、検査の機能を、大企業のデータチームに提供します。制御されたコラボレーションのために、管理者は登録されたモデルに対して、ACLを用いてアクセス権を設定することができます。
そして最後に、モデルライフサイクルワークフローにおいては、DatabricksワークスペースのMLflow UIあるいは、MLflow APIを用いてレジストリを操作することができます。
モデルレジストリを使い始めてみる
試す準備はできましたか?MLflowのモデルレジストリをどのように使うかに関しては、ドキュメント[AWS][Azure]を参照ください。あるいは、サンプルノートブック[AWS][Azure]を使用することもできます。
MLflowを使ったことがない場合には、オープンソースMLflowのクイックスタートをご覧ください。プロダクションのユースケースにおいては、DatabricksマネージドのMLflowをご一読いただき、MLflowモデルレジストリを使ってみてください。
そして、DatabricksでMLflowを用いて、完全なMLライフサイクルの管理における最新の開発とベストプラクティスを学びたい方は、MLOpsバーチャルイベントにご参加ください。