Plan capacity and control cost | Databricks on AWS (2021/3/17時点)の翻訳です。
本記事は、AWSクラウドインフラストラクチャにおけるDatabricksクラスターの利用、配置に関する様々なシナリオにおけるベストプラクティスを説明するものです。
クラスター利用に関する用語、Databricksのクラスター管理ツール
本章では、クラスター利用に関する用語と、クラスター管理に関係するDatabricksの機能を紹介します。
インスタンスアワー
多くのクラウドプロバイダーにおいては、1時間あたり1台のインスタンスが稼働することが1インスタンスアワーになります。Databricksにおいては、1時間当たりの処理単位である、Databricks Unit(DBU)に基づいて課金されます。1 DBUは、1台のr3.xlarge(メモリー最適化)インスタンス、あるいは1台のc3.2xlarge(計算処理最適化)インスタンスの1時間稼働に相当します。詳細はDatabricksプライシングを参照ください。
例えば、r3.xlargeの1台のドライバーノード、3台のワーカーノードから構成されるDatabricksクラスターを作成し、クラスターを2時間稼働させた場合には、DBUは以下のように計算されます:
- 合計インスタンスアワー = 合計ノード数(1 + 3) * 時間数 (2) = 8
- 合計金額 = AWSにおける8台のr3.xlargeインスタンスアワーの費用 + 8 DBU
Databricksは秒単位で課金を行います。
オンデマンド、スポットインスタンス
AWSには二つのインスタンスティアがあります:オンデマンドとスポットです。オンデマンドにおいては、長期のコミットメントなしに秒単位で計算資源を利用しただけの課金が発生します。スポットインスタンスにおいては、余剰のAmazon EC2インスタンスを利用することができ、あなた自身が最大支払額を指定することができます。現在のスポットマーケットプライスが、最大スポット支払額を上回った場合には、スポットインスタンスは停止されます。多くのケースでスポットインスタンスはオンデマンドインスタンスより安価であるため、同じ予算においても、アプリケーションを実行する際にコストを削減することができるため、より高価な計算資源を利用することでスループットを改善することができます。
Databricksにおいては、オンデマンドインスタンスと(カスタムスポットプライスを指定した)スポットインスタンスを組み合わせてクラスターを構成することができ、ユースケースに合わせてクラスターを構築することができます。
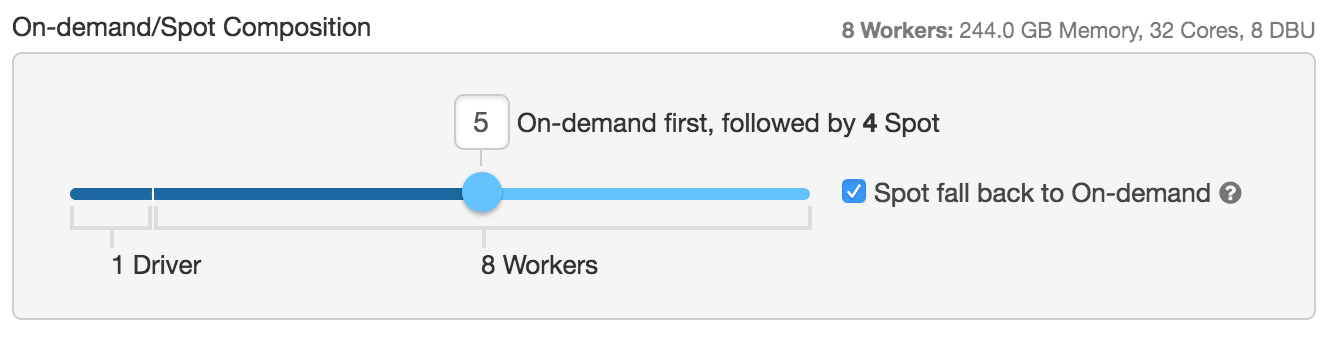

例えば、上の設定においては、ドライバーノードと4台のワーカーノードはオンデマンドインスタンス、残りの4台のワーカーノードはスポットインスタンス(最大のスポットインスタンスプライスはオンデマンドの100%)として起動すべきと設定しています。
スポットインスタンスの停止が起きたとしてもクラスターの状態保持できるように、Sparkのドライバーノードはオンデマンドインスタンスとして起動することをお勧めします。(ドライバーノードを含む)全てをスポットインスタンスとして起動すると、スポットマーケットの価格変動でドライバーインスタンスが失われると、キャッシュされたデータ、テーブルは削除されてしまいます。
もう一つ注意しなくてはいけない設定項目は、Spot fall back to On-demandです。オンデマンドとスポットから構成されるハイブリッドクラスターを稼働させている際に、スポットインスタンスの獲得に失敗、あるいはスポットインスタンスを失ったとしても、Databrikcsはオンデマンドインスタンスを利用し、期待する性能を実現します。この設定が無いと、クラスターに処理の遅延あるいは処理の失敗が発生し、期待する性能が得られません。ユースケースに対するコスト感度、重要度に応じてオンデマンドとスポットの比率を決定することをお勧めします。
ティップ
適切なインスタンスタイプとリージョンを決定する際には、Amazon Spot Instance Advisorを活用できます。
オートスケーリング
オートスケーリングを活用することで、リソース利用量を最適化するためにワークロードに応じて、ワーカーノードの数を自動で増減することができます。オートスケーリングを有効化することで、DatabricksはSparkジョブを実行するのに最適なワーカーの数を自動的に決定します。オートスケーリングを用いることで、ワークロードに適した数のクラスターを気にすることなしに、クラスターの高い利用率を実現できます。これにより二つのメリットを享受することができます:
- 固定サイズ、あるいは性能不足のクラスターで処理を行うより高速
- 固定サイズのクラスターに比べて全体のコストを削減できる
オートスケーリングを有効化する際には、ノードの最小数、最大数を指定することができます。

上の設定では、8台から20台のノードでオートスケーリングを有効に指定しており、ドライバーノードを含む5台をオンデマンド、残りをスポットインスタンスにしています。
クラスターの起動
クラスター起動により、過去に停止されたクラスターの設定情報(クラスターID、インスタンス数、インスタンスタイプ、スポット・オンデマンドの比率、インスタンスプロファイル、インストールすべきライブラリなど)を維持したまま再起動することができます。以下の画面からクラスターを起動できます:
-
停止クラスターの一覧

-
クラスター詳細ページ

オートターミネーション、オートストップ
コスト削減のために、クラスターを自動停止する条件(例えば、3時間アイドル)を設定できるオートターミネーションを活用できます。SQLエンドポイントにおいては、この機能はオートストップと呼ばれます。
重要
アイドル状態のクラスター、SQLエンドポイントに対してDBUのチャージは発生します。また、停止前の期間においてはクラウドインスタンスに対してもチャージが発生します。
クラスターAWSタグ
組織内の異なるグループがクラウドリソースを使う際にクラスタータグを利用することで、容易にコストをモニタリングできます。クラスターを作成する際に、キーバリューの形式でタグを指定することで、DatabricksはインスタンスのEBSなどのクラウドリソースにタグを付与します。

シナリオ
本章では特定のシナリオを深堀りすることで、コストと使いやすさのバランスを取るベストなアプローチを確立します。
一般的なクラスター設定
以下の表にDatabricksにおける一般的なクラスター設定シナリオを列挙しています。Databricksのユーザー及びユースケースに応じて、あなたの設定は若干変化するかもしれません。一般的には、データサイエンティストはデータアナリストよりも自身のクラスターを管理することを好みます。もし、管理者がクラスターのサイズに対してより厳密な制限を課したいのであれば、データサイエンティスト向けのクラスターを配置するという選択をすることができます。さらに、データエンジニアはREST APIあるいはUIからジョブを起動することになるでしょう。もし、UIからジョブを起動するのであれば、特にプロダクションでのジョブにおいてはNew Clusterオプションを指定することをお勧めします。
| シナリオ | ユースケース | 推奨クラスター | クラスターの管理者 | 想定ユーザー |
|---|---|---|---|---|
| シナリオ1 | 組織横断での一般的な利用 | シェアードオートスケーリングクラスター | 管理者 | データアナリスト |
| シナリオ2 | 特定ユースケースにおけるアドホックな利用 | 個別のクラスター | 管理者/ユーザー | データサイエンティスト |
| シナリオ3 | スケジュールされたバッチ処理 | ジョブ経由での新規クラスターの起動 | ユーザー | データエンジニア |
| シナリオ4 | クラスターのクローン | ジョブ経由での新規クラスター起動 | 管理者 | 管理者 |
シナリオ1
組織あるいは大規模グループにおける一般的な利用(データアナリストによるダッシュボード作成)
あなたは、大規模なユーザーグループに対して、アドホックなクエリを行うためのデータへのアクセス手段(主にSQL)を提供しなくてはならないと仮定します。日によって使用量は変動し、負荷の高い処理はごく一部です。多くのユーザーはデータに対する読み取りアクセスを必要とし、異なるデータソースから、シンプルかつ直感的なノートブックを使用してダッシュボードを作ります。
このような状況においてクラスターを提供するベストなのは、オートスケーリングが有効化されたクラスターを提供するハイブリッドなアプローチです。ハイブリッドアプローチには、インスタンスの最小数、最大数が定義されたオートスケーリング機能とオンデマンド・スポットインスタンスが含まれます。このクラスターは常時稼働(24/7)であり、グループのユーザーが利用することができ、負荷に応じてスケールアップ・ダウンします。ユーザーにはクラスターを開始・停止する権限はありません。
初期状態で設定されているオンデマンドインスタンスは、より良い使いやすさを提供するためにユーザーからのクエリに即座に反応します。ユーザーのクエリがより多くのキャパシティを必要とした際には、負荷に対応できるようにオートスケーリングがより多くのノード(多くはスポットインスタンス)を配置します。

Databricksは、マルチテナントのユースケースをより良いものにするための機能を提供しています:
- インタラクティブワークフローにおける高負荷クエリの取り扱い - 終了しないクエリを自動的に管理
- タスクのプリエンプション - 長期実行クエリと短期実行クエリの共存
- ローカルストレージのオートスケーリング - マルチテナントにおけるストレージ枯渇(シャッフル)の回避
このアプローチにより、以下の理由から全体的なコストを削減できます:
- 共有クラスターモデルの活用
- オンデマンド・スポットインスタンスの活用
- 固定サイズのクラスターではなくオートスケーリングを活用することで余計なクラスター時間の支払いを回避
シナリオ2
組織内における特定のユースケース、グループ(データサイエンティストによる探索)
このシナリオは、組織内の特定のユースケース、グループのためのものです。例えば、データサイエンティストが集中的にデータ探索や、クラスターへの特殊なライブラリのインストールを必要とする機械学習アルゴリズムを実行するなどです。
典型的なユーザーは短期間に集中してデータ処理を行い、その後にクラスターを削除するでしょう。
この種の作業におけるベストなアプローチは、管理者が事前に定義された設定(インスタンス数、インスタンスタイプ、スポット・オンデマンドの比率、インスタンスプロファイル、インストールすべきライブラリなど)に基づいてクラスターを作成し、ユーザーにはクラスター開始による開始・停止の権限を与えるというものです。さらなるコスト削減として、ある条件に合致(例えば、アイドル状態が1時間以上継続したら停止する)した場合にはクラスターを停止するオートターミネーションを活用します。

このアプローチは、ユーザーに対してクラスターを起動することのできるより強い権限を与えるものですが、依然として事前に定義した設定の制限をかけることでコストをコントロールすることが可能です。例えば、管理者はデータ探索のユースケースにおいては、オートターミネーションが有効化された100%スポットインスタンスのクラスターのみを許可するということが可能です。また、このアプローチにおいては、インスタンスプロファイルとAWSのキーを活用することで、異なるグループのユーザーに対して、異なるデータへのアクセスが許された異なるクラスターを割り当てることも可能です。
このアプローチにおける欠点は、クラスターにおけるあらゆる変更、設定、ライブラリなど全てにおいて管理者の関与が必要となることです。
シナリオ3
スケジュールされたバッチ処理(データエンジニアによるETLジョブ)
このシナリオには、DatabricksプラットフォームにおけるJARやノートブックの定期実行が含まれます。
ベストプラクティスは、重要なジョブの実行の際には新規クラスターを起動するというものです。これにより、共有クラスターにおける既存ワークロード(うるさい隣人)の問題(失敗、SLA未達など)を回避することができます。ジョブの重要度、コストに応じてオンデマンドとスポットのバランス(最重要であれば全てをオンデマンド、コストを優先するのであればスポット + Spot fall back to On-demand)を決定します。


クリティカルではないダッシュボード関係のジョブであれば、新規クラスターを作成せずに共有クラスターを使用しても構いません。
シナリオ4
クラスターのクローン(管理者向け)
クラスターのクローンによって、管理者は設定やライブラリなどを保持したまま既存のクラスターを複製することができます。これにより、同じようなクラスター要件を持つ複数のユーザーグループにクラスターを提供することが可能になります。この機能は擬似的なテンプレート機能を提供し、異なるユーザーグループに対する設定のメンテナンスを容易にします。
参考情報
- Amazon EC2 On-Demand Pricing
- Databricks Serverless: Next Generation Resource Management for Apache Spark
- Query Watchdog: Handling Disruptive Queries in Spark SQL
- Running Apache Spark Clusters with Spot Instances in Databricks
- Persistent Clusters: Simplifying Cluster Management for Analytics
- Best Practices for Coarse Grained Data Security in Databricks