Introducing MLflow Pipelines with MLflow 2.0 - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
MLOpsプロセスを自動化し、スケールさせるためにプロダクションレベルのMLワークフローを作成
2018年にMLflowを立ち上げて以来、MLflowは月間1100万以上のダウンロードがされる最も人気のあるMLOpsフレームワークとなりました!今では、あらゆる規模のチームが、モデルをトラッキング、パッケージング、デプロイするためにMLflowを活用しています。しかし、MLアプリケーションに対する要求が高まるにつれて、チームは大規模にモデルを開発、デプロイする必要が出てきました。我々は間も無くMLflow 2.0が公開されること、そして、プロダクションレベルのMLパイプラインを構築することで、チームがML開発をシンプルに自動化、スケールできるようにするMLflow Pipelinesが含まれることを発表できることを嬉しく思っています。
MLのオペレーション化における課題
モデルをデプロイする際、モデルをトレーニングする以上の多くのことを行わなくてはなりません。データを取り込んで検証し、実験を実施して証跡を追跡し、パッケージを作成し、モデルを検証してデプロイしなくてはなりません。また、ライブのプロダクションデータでモデルをテストし、デプロイされたモデルを監視しなくてはなりません。最後に、新たなデータが到着したり、状況が変化した際には、プロダクションにあるモデルを管理、アップデートしなくてはなりません。
単一のモデルを管理している際には、手動のプロセスでどうにかなるかもしれません。しかし、プロダクションで複数のモデルを管理したり、頻繁にアップデートする必要がある単一のモデルをサポートしている場合でさえも、プロダクションに移行するためにはプロセスを成文化し、ワークフローを活用しなくてはなりません。このことは、1) 上述したMLプロセスの全てを含むワークフローを作成し、2) モジュール性、スケーラビリティ、テスト可能性のように全てのプロダクションコードで共通した要件を満たさなくてはならないことを意味します。探索段階からプロダクションに移行するために必要となるこれら全ての作業のため、チームは信頼性を保ちつつクイックにMLシステムをプロダクションで実装することが困難であることを知っています。
MLflow Pipelines
MLflow Pipelinesは、モデルのデプロイメントを高速かつスケーラブルにするためのソフトウェアエンジニアリングのベストプラクティスを用いて、モジュール化されたMLコードを組み合わせる、プロダクションレベルのMLパイプラインを作成するために標準化されたフレームワークを提供します。MLflow Pipelinesを用いることでDevOpsのベストプラクティスに従いつつも、MLプロジェクトをブートストラップし、容易に迅速なイテレーションを行い、パイプラインをプロダクションに移行することができるようになります。
MLflow PipelinesはMLflowに以下のコアコンポーネントを導入します。
- Pipeline: それぞれのパイプラインは、ステップとモデルのトレーニングやバッチ推論の適用のようなエンドツーエンドの機械学習オペレーションを実行するためにどのようにこれらのステップを接続するのかに関する設計図から構成されます。パイプラインは、複雑なMLOpsプロセスをそれぞれのチームが独立して取り組むことができる複数のステップにブレークダウンします。
- Steps: ステップは、データ取り込みや特徴量の変換のような単一のタスクを実行する管理可能なコンポーネントです。これらのタスクは多くの場合、モデル開発を通じて異なる周期で実行されます。ステップはパイプラインを構成するために、適切に定義されたインタフェースを通じて接続され、複数のパイプラインで再利用することができます。ステップは、YAML設定、あるいはPythonコードを通じてカスタマイズすることができます。
- Pipeline templates: パイプラインテンプレートは、回帰、分類、バッチ推論のように異なるML問題やオペレーションを解決するために、信念を持ったアプローチを提供します。それぞれのテンプレートには、標準的なステップを含む事前定義済みパイプラインが含まれています。MLflowは一般的なML問題に対するビルトインのテンプレートを提供し、チームは自身の要件に合わせて新たなパイプラインテンプレートを作成することができます。
ご自身のMLOpsプロセスを成文化し、組織内で自動化、共有するために、上述のパイプラインコンポーネントを活用することができます。あなたのMLOpsプロセスを標準化することで、モデルのデプロイメントを加速し、より多くのユースケースにMLをスケールさせることができます。

MLflow PipelinesによるMLOpsの自動化およびスケーリング
MLflow PipelinesによるMLOpsの自動化とスケーリング
プロダクションMLへの道のりの標準化と加速
MLflow Pipelinesを用いることで、データサイエンスチームは、少々のリファクタリングあるいはリファクタリングなしに、デプロイ可能なプロダクションレベルのMLコードを作成することができます。これは、データサイエンスチームがコードにアクセス可能でありつつも、モジュール性、テスト可能、再現可能性のようなソフトウェアエンジニアリングの原則を機械学習にもたらします。また、パイプラインは環境横断での再現性を保証し、お使いのラップトップ、Databricks、その他のクラウド環境でも一貫性の結果を提供します。重要なことですが、統合されたプロジェクト構成、モジュール化されたコード、標準化されたインタフェースによって、プロダクションチームは容易にコードのデプロイメント向けのエンタープライズの機構とMLワークフローとのインテグレーションを行うことができます。これによって、企業はデータサイエンスチームがプロダクションコードのデプロイメントに対するエンタープライズのプラクティスに従いつつ、MLパイプラインをデプロイすることができます。
機械学習にフォーカスし、定型コードをスキップする
MLflow Pipelinesは、一般的なML問題に対するMLパイプラインをブートストラップし構築するのを容易にするテンプレートを提供します。テンプレートは事前定義済みのグラフや定型コードを用いてパイプラインの足場を構築します。そして、YAML設定を用いるか、Pythonコードを提供することで、個々のステップをカスタマイズすることができます。また、それぞれのステップでは、特徴量の重要度のプロットや大きな予測誤差があることをハイライトすることで、デバッグやトラブルシュートを容易にするアウトオブボックスの可視化を提供する自動生成カードを提供します。また、カスタムテンプレートを作成し、組織内で共有することもできます。
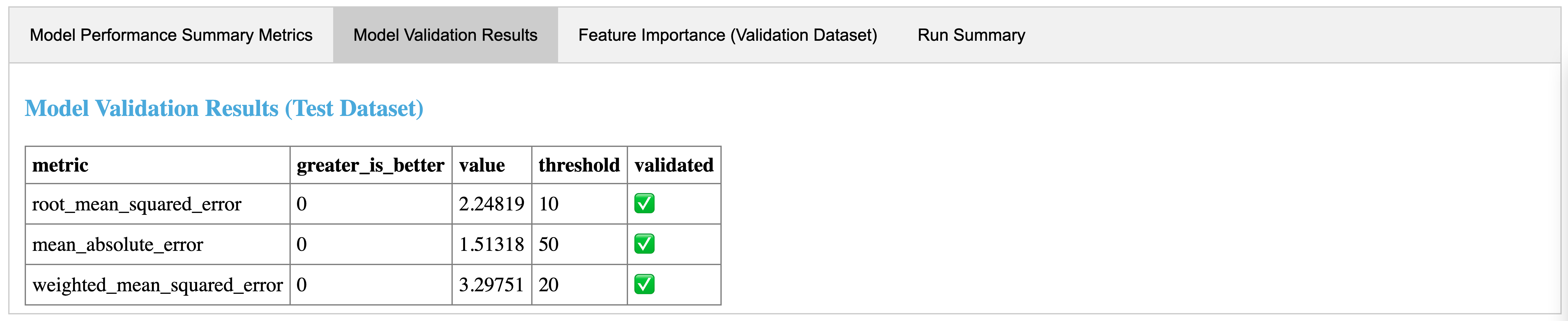
高速かつ効率的なイテレーティブ開発
MLflow Pipelinesはステップを記憶し、本当に必要なパイプラインの箇所のみを再実行することで、モデルの開発を加速します。モデルをトレーニングする際、それぞれが少しずつ異なる複数のエクスペリメントを用いて、異なるタイプのモデルやハイパーパラメーターをテストするために複数のエクスペリメントを実行しなくてはなりません。それぞれのエクスペリメントのすべてのパイプラインを毎回際実行することは、時間と計算リソースの無駄です。MLflow Pipelinesは自動で変更のないステップを検知し、前回の実行結果を再利用するので、実験がより高速かつ効率的になります。
素晴らしいMLflowトラッキングがワークフローレベルに
MLflowは、MLflowのラン、モデル、ステップの出力、コード、設定のスナップショットを含むそれぞれのパイプラインの実行に関するメタデータを自動で追跡します。また、MLflowはパイプラインが実行される際にテンプレートリポジトリのgitコミットを追跡します。クイックに以前の実行結果を確認し、結果を比較し、必要に応じて過去の結果を再現することができます。

MLflow Pipelinesファーストリリースの発表
本日、高品質な回帰モデルを開発するためのプロダクションレベルのテンプレートを提供する最初のMLflow Pipelinesのイテレーションを発表できることを嬉しく思っています。このテンプレートを用いることで、事前定義済みのステップと定型コードを用いて回帰パイプラインの足場を構築することができます。そして、データ変換やモデルトレーニングのような個々のステップをカスタマイズし、ローカルあるいはクラウド上でクイックにパイプラインを実行することができます。
MLflow Pipelinesを使い始める
ご自身で試してみる準備はできていますか?MLflow repoでMLflow Pipelinesの詳細や使い方を調べることができます。あるいは、Data+AI Summit 2022 talks on MLflow Pipelinesを聴いてみてください。我々は、MLflow PipelinesをオープンソースMLflowプロジェクトのコアコンポーネントとして開発していますので、改善のために是非皆さまからフィードバックをいただければと考えています。
Data + AI Summit 2022での発表やアップデートに関して、データに熱中している人たちが会話しているDatabricks Communityに参加してみてください。学び、ネットワークを作り、祝いましょう。