本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
患者の健康状態や病気の進行を理解する際の最大の課題の一つが、ヘルスケアにおける膨大な量の半構造化データ、非構造化データからの価値を開放しています。医療におけるデジタル画像とコミュニケーション(Digital Imaging and Communications in Medicine)の頭文字をとったDICOMは、医療画像情報のコミュニケーションと管理の標準となっています。CT、X線、PET、超音波、MRIのような形式を含む医療画像は、整形外科、腫瘍学、産科学に至る特定領域のヘルスケアにおいて、数多くの診断や治療プロセスで重要なものとなっています。
GPUを通じた計算能力の向上や、大量画像データセットへのアクセシビリティによって、医療画像に対するディープラーニングの活用は多くの場所で目撃されるようになっています。
ディープラーニングは、診断プロセスの一部を自動化し、画像品質を改善し、画像から情報をもつバイオマーカーを抽出するなどの目的で活用されるモデルのトレーニングに適用されます。これは治療のコストを劇的に削減する可能性を持っています。しかし、医療画像に対するディープラーニングのアプリケーションを成功させるには、患者から得られるその他の健康情報と組み合わされた膨大な数の画像と、規制による制約に準拠しながらも大規模なMLに対応できるインフラストラクチャが必要となります。
データウェアハウスのような従来型のデータ管理システムは、非構造化データタイプに対応できず、データレイクはデータの検索可能性とアクセシビリティにおいて重要となるメタデータのカタログ作成や格納に失敗します。ヘルスケア、ライフサイエンス向けDatabricksレイクハウスは、皆様がお持ちのすべてのデータタイプを取り込み、管理し、分析できるスケーラブルな環境を提供することで、これらの欠点に対応します。特にDICOMのサポートに関しては、Databricksは数百の画像フォーマットのインテグレーションを容易にする新たなソリューションアクセラレーターdatabricks.pixelsをリリースしました。
例えば、10,000のDCOM画像のライブラリからスタートし、インデックス作成、メタデータ抽出、サムネイル生成を実行します。そして、それらを高信頼かつ高速なDelta Lakeに保存します。オブジェクトカタログにクエリーを行うことで、以下のようにDICOMのイメージヘッダーメタデータ、サムネイル、パス、ファイルのメタデータを表示することができます。

ファイルパス、ファイルメタデータ、DICOMメタデータ、サムネイルの表示
Pythonパッケージdatabricks.pixelsが提供する7つのコマンドによって、ユーザーは容易に完全なカタログやメタデータを生成し、サムネイルを準備することができます。
# imports
from databricks.pixels import Catalog # 01
from databricks.pixels.dicom import * # 02
# catalog all your files
catalog = Catalog(spark) # 03
catalog_df = catalog.catalog(<path>) # 04
# extract the Dicom metadata
meta_df = DicomMetaExtractor(catalog).transform(catalog_df) # 05
# extract thumbnails and display
thumbnail_df = DicomThumbnailExtractor().transform(meta_df) # 06
# save your work for SQL access
catalog.save(thumbnail_df)
このブログ記事では、以下を含む機能の提供開始とともに、画像ファイル処理を加速するフレームワークであるdatabricks.pixelsをご紹介します:
- ファイルのカタログ作成
- メタデータに基づくファイルの抽出
- DICOMファイルヘッダーからのメタデータ抽出
- 柔軟性のあるSQLクエリーを通じたメタデータパラメーターに基づくファイルの選択
- DICOMサムネイルの生成と可視化
databricks.pixelsアクセラレーターは、拡張可能なSpark MLのトランスフォーマーパラダイムを活用しているので、レイクハウスアーキテクチャがヘルスケアやライフサイエンスドメインのユーザーに提供するさまざまなパワーを活用するための能力の拡張やパイプラインの作成は容易なものとなります。
Databricksレイクハウスは、画像ファイル処理をユーザーが利用できるようにしますが、databricks.pixelによって、筋金入りのDICOMオープンソースライブラリのインテグレーションやSparkの並列処理や、Delta Lakeによってもたらされる堅牢なデータアーキテクチャとの統合を容易なものとします。データフローは以下のようになります:
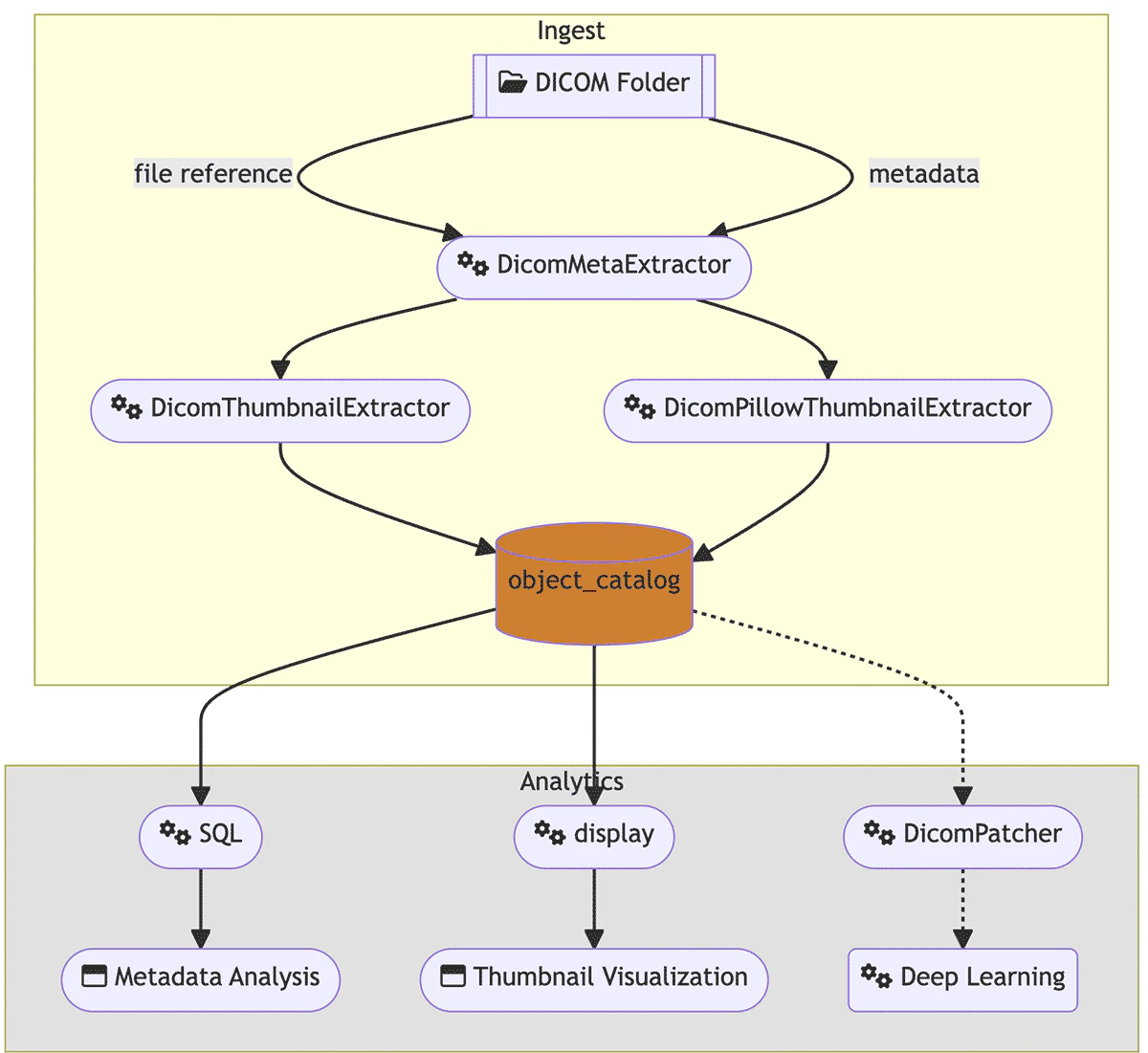
SQLを用いたDICOM属性のメタデータ分析
DICOM画像処理の標準モデルは、pydicom、python-gdcm、gdcm c++ライブラリです。しかし、これらのライブラリの標準的な使用法は、単一のCPUコアに限定されており、データのオーケストレーションは通常は手動であり、プロダクションレベルのエラーハンドリングに欠けています。このため、(メタ)データの抽出は、レイクハウスのより大規模なビジョンとのインテグレーションとかけ離れたものとなっています。
我々は、DICOMや他の「構造化されていない」フォーマットの処理をシンプルにし、スケールするためにdatabricks.pixelsを開発し、以下のメリットを提供しています:
-
使いやすさ -
databricks.pixelsは容易にデータファイルのカタログを作成し、トランスフォーマー技術がプロプライエタリなメタデータを抽出しつつも、ファイルとパスのメタデータをキャプチャします。databricks.pixelsは以下で示すように、メタデータ分析を民主化します。 -
スケール -
databricks.pixelsはSparkのパワーとDatabricksクラスター管理機能を活用することで、小規模の研究でのシングルインスタンス(1-8コア)から、履歴データ処理や大ボリュームのプロダクションパイプラインに対応するために必要に応じて10から1000個のCPUコアに容易にスケールすることができます。 - 統合 - 皆様の画像やカタログを現在格納し、インデックスを作成しているデータサイロを打ちこわし、より完全な全体像を得るために、電子健康記録(EHR)、主訴、リアルワールドエビデンス(RWE)、遺伝子データと統合し、カタログを作成します。小規模な研究やデータを整理するプロダクションパイプラインに取り組んでいるチーム間でのコラボレーションやデータガバナンスを実現します。
動作原理
Databricksレイクハウスプラットフォームは、DICOM画像や他の画像ファイルタイプに関連するすべての処理要件のための統合プラットフォームです。Databricksは、DICOMファイルの読み込みを実行するために、検証されたオープンソースライブラリと容易なアクセスを提供します。DatabricksのSparkは、並列でpythonタスクを処理するためのスケーラブルなマイクロタスクデータの並列オーケストレーションフレームワークです。Databricksクラスターマネージャは、オートスケーリングと、必要な計算資源(CPU、GPU)への容易なアクセスを提供します。Delta LakeはDICOMファイルから抽出された(メタ)データを格納するための、高信頼、柔軟性のある手段を提供します。Databricksワークフローは、DICOMの処理と皆様のデータや分析ワークフローをインテグレーションし、モニタリングする手段を提供します。
使い始める
詳細とサンプルについては、https://github.com/databricks-industry-solutions/pixels のREADME.mdを確認ください。このアクセラレータを活用するには、DBR 10.4 LTSのDatabricksクラスターを作成してください。お持ちの画像のカタログ作成をすぐに始めるためには、01-dcm-demo.py notebookとジョブを活用することができます。
このアクセラレータを実行するには、このリポジトリをDatabricksワークスペースにクローンします。DBR 10.4 LTS以降のランタイムが稼働しているクラスターにRUNMEノートブックをアタッチし、Run-Allでノートブックを実行します。アクセラレータのパイプラインを表現するマルチステップのジョブが作成され、リンクが表示されます。どのようにパイプラインが実行されるのかを確認するために、マルチステップジョブを実行します。ジョブの設定は、jsonフォーマットでRUNMEノートブックに記載されています。このアクセラレータを実行する際のコストは皆様のものとなります。
取り込まれた画像はS3あるいはDBFS経由のマウントポイントに格納される必要があり、デモノートブックのインプットやジョブの最初のパラメータでこのパスを指定します。

DICOMジョブのパラメーター
object_catalogを格納するカタログ、スキーマ、テーブルを選択します。どのようにobject_catalogをアップデートするのかを指定するためにアップデートモード(overwriteかappend)を選択します。
デモのジョブは生のDICOMファイルのロードとパーシングをデモンストレーションします。分析においては、フィルタリング、SQLベースのクエリー、サムネイルの表示がデモンストレーションされます。
サマリー
databricks.pixelsソリューションアクセラレータは、レイクハウスにおけるDICOM画像の取り込みをキックスタートする容易な手段となります。
今後の取り組み
databricks.pixelsは容易にファイル処理をスケールさせるフレームワークとして設計されています。ユーザーの皆様は、PDF、ZIPファイル、動画などを処理できるようになることを期待しています。必要であればGitHubのイシューを作成いただき、トランスフォーマーに貢献いただくか、既存のGithubイシューを修正してください!