Apache Spark and Hadoop HDFS: Working Togetherの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2014年の記事です。
我々はよく、Apache SparkがどのようにHadoopのエコシステムに収まるのか、既存のHadoopクラスターでどのようにSparkを実行できるのかという質問をいただきます。この記事では、これらの質問に回答します。
最初に、SparkはHadoopスタックの置き換えでなく、エンハンスすることを目的としています。当初から、SparkはHDFSや、HBaseやAmazonのS3など他のストレージシステムとデータを読み書きできるように設計されていました。Hadoopのユーザーは、SparkとHadoopのMapReduce、HBaseや他のビッグデータプラットフォームを組み合わせることで、自身の処理能力を向上させることができます。
次に、我々は全てのHadoopユーザーが、Sparkの能力を可能な限り簡単に活用できるようにすることにフォーカスし続けています。Hadoop 1.xあるいはHadoop 2.0 (YARN)を実行していようが、Hadoopクラスターを設定できる管理権限を持っていようが持っていまいが、Sparkを実行する方法が存在します!特に、HadoopクラスターにSparkをデプロイする方法は3つ存在します。スタンドアローン、YARN、そしてSIMRです。
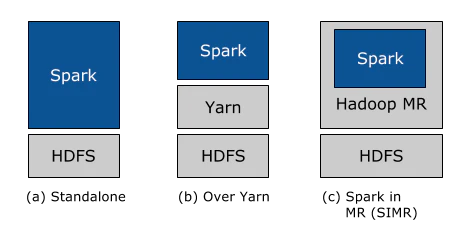
スタンドアローンデプロイメント: スタンドアローンデプロイメントでは、Hadoopクラスターのマシンの一部あるいは全部のリソースを静的に割り当てることができ、SparkとHadoop MRを同居させて実行することができます。ユーザーはHDFSデータに対して任意のSparkジョブを実行することができます。このシンプルさは、多くのHadoop 1.xユーザーに対するデプロイメントの選択肢となります。
Hadoop Yarnデプロイメント: Hadoop Yarnをデプロイしている、あるいはこれからデプロイしようとしているHadoopユーザーは、事前インストールや管理者アクセスなしにシンプルにYARN上でSparkを実行することができます。これによって、ユーザーは容易にSparkを自身のHadoopスタックにインテグレーションし、Sparkのフルパワー、その他のSparkで動作するコンポーネントを活用することができます。
Spark In MapReduce(SIMR): まだYARNを実行していないHadoopユーザーに対して、スタンドアローンのデプロイメントに加えて、MapReduce内でSparkジョブを起動するSIMRを使うという別のオプションを提供します。SIMRを用いることで、ユーザーはSparkを用いた実験を開始することができ、ダウンロードした後の数分でシェルを使用することができます!これは、デプロイメントの障壁を劇的に引き下げ、誰でもSparkで遊ぶことができるようになります。
他のシステムとの相互運用性
SparkはHadoopとだけではなく、他の人気のあるビッグデータテクノロジーと相互運用することができます。
- Apache Hive: Sharkを通じて、SparkはApache Hiveのユーザーがクエリーを変更することなしに、より高速にクエリーを実行することが可能となります。HiveはHadoop上で動作する人気のあるデータウェアハウスソリューションですが、SharkはHadoopではなくSpark上でHiveフレームワークをどうさせるためのシステムです。結果として、Sharkは入力データがメモリーに収まる際はHiveのクエリーを100倍高速にし、入力データがディスクに格納されている場合も10倍高速にします。
- AWS EC2: ユーザーは、Sparkに同梱されているスクリプトあるいはAmazonのElastic MapReduce上にホストされているSpark、Sharkを用いて、容易にAmazon EC2の上でSpark(とShark)を実行することができます。
- Apache Mesos: Sparkは、MPIとHadoopを含む分散アプリケーション間での効率的なリソース分類を提供するクラスターマネージャシステムであるMesos上で動作します。Mesosは、Sparkジョブの実行時におけるクラスターのアイドルリソースを同的に活用するために、きめ細かい共有を実現します。これによって、特に長時間実行するSparkジョブにおいては劇的な性能改善につながります。