先日開催したJEDAI勉強会「とりあえず使えるBERT」のノートブックをDatabricksでウォークスルーします。
使っているノートブックはGoogle Colab向けのノートブックですがそのままでも動きます。ただ、以下ではDatabricks向けに若干修正しています。
Databricks対応板ノートブック
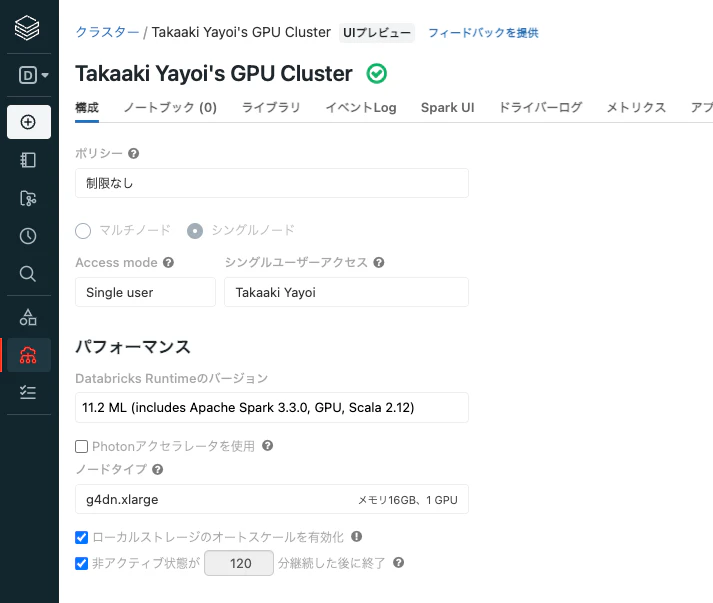
クラスターの準備
GPUクラスターがお勧めです。
ノートブックのウォークスルー
ライブラリのインストール
%pip install transformers==4.18.0 fugashi==1.1.0 ipadic==1.0.0 pytorch-lightning==1.6.1
Python
import random
import glob
from tqdm import tqdm
import torch
from torch.utils.data import DataLoader
from transformers import BertJapaneseTokenizer, BertModel, BertForSequenceClassification
import pytorch_lightning as pl
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print("利用するdevice :", device) #gpuが利用できるなら"cuda:0", そうでなければ"cpu"
model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking' #東北大が公開しているBertモデルを利用します
文章をBERTに投入できる形に変換する
Python
exp_string = 'モビルスーツの性能の違いが、戦力の決定的差ではないという事を教えてやる。'#このセリフをBERTに投入できる形に変換します。
#日本語をBERTに投入できるように変換する関数をインスタンス化します
#BertJapaneseTokenizer.from_pretrained()の引数に「東北大が公開しているBertモデル」を指定することで、
#「東北大が公開しているBertモデル」が利用できる形で、日本語をAI語に変換することができます。
tokenizer = BertJapaneseTokenizer.from_pretrained(model_name)
Python
#日本語をBERTに投入できるように変換する関数を用いて、日本語を変換します。
encoding = tokenizer(
text=exp_string,
max_length=32,#BERTに入力する最終的なinput_idsの長さ
padding='max_length',truncation=True, #input_idsの長さをmax_lengthに調整するための引数
return_tensors='pt',#出力データをpytorchの形式で返す(haggingfaceはtorchで実装されています。)
)
encoding #返り値は辞書型で"input_ids", "token_type_ids", "attention_mask"のkeyを持っています。

Python
#convert_ids_to_tokensメソッドを用いることで、input_idsは日本語に変換できます。(中身の確認に使えます)
print("input_ids")
print(encoding["input_ids"][0])
print("")
print("tokenに変換して文章を確認")
print(tokenizer.convert_ids_to_tokens(encoding["input_ids"][0]))

事前学習済みBERTを用いて、input_idsを行列に変換する
Python
bert = BertModel.from_pretrained(model_name)#BERTを東北大が公開している事前学習済みの重みを用いてインスタンス化します
bert.config#インスタンス化したBERTモデルの詳細を確認しましょう

Python
#早速encoding結果をbertモデルに投入してみましょう!
output = bert(**encoding)#encodingした文章をBERTに投入し、文脈が練り込まれた行列に変換します。
#outputの中身を見てみましょう。
print(output["last_hidden_state"].shape) #torch.Size([1, 32, 768]):([文章数, tokenの長さ, 各tokenの次元数])に対応しています。
output["last_hidden_state"]#last_hidden_stateには入力したtokenに対応する行列が格納されています。

BERTのFineTuneを実施する
- 「商品レビュー」と「対応部署」のオープンデータセットは存在しないため、同様の問題設定として、「livedoor ニュースコーパス」を用いた分類問題に挑戦します。
- livedoor ニュースコーパス : https://www.rondhuit.com/download.html
データのダウンロードと前処理
shell
%sh
# データのダウンロード
wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
# ファイルの解凍
tar -zxf ldcc-20140209.tar.gz
shell
%sh
ls ./text #DLしたファイルを見ると、./text以下にそれぞれのメディアに対応するフォルダが作成されていることがわかります。

shell
%sh
cat ./text/it-life-hack/it-life-hack-6342280.txt #試しに一つのファイルを確認してみましょう。

Python
# カテゴリーのリスト
category_list = [
'dokujo-tsushin',
'it-life-hack',
'kaden-channel',
'livedoor-homme',
'movie-enter',
'peachy',
'smax',
'sports-watch',
'topic-news'
]
# トークナイザのインスタンス化
tokenizer = BertJapaneseTokenizer.from_pretrained(model_name)
# 各データの形式を整える
max_length = 128 #今回はBertに投入する文章の長さの最大を128とします。
dataset = []
for label, category in enumerate(category_list):
file_names_list = sorted(glob.glob(f'./text/{category}/{category}*'))#対象メディアの記事が保存されているファイルのlistを取得します。
print(f"{category}の記事を処理しています。 {category}に対応する番号は{label}で、データ個数は{len(file_names_list)}です。")
for file in file_names_list:#取得したlistに従って実際にFileからデータを取得します。
lines = open(file).read().splitlines()
text = '\n'.join(lines[3:]) # ファイルの4行目からを抜き出す。
#tokenizerを用いて文章をBERTに投入できる形に変換します。
encoding = tokenizer(
text,
max_length=max_length,
padding='max_length',
truncation=True
)
encoding['labels'] = label # カテゴリーはテキストではなく、数字で付与します。
encoding = { k: torch.tensor(v) for k, v in encoding.items() }#labelも含めてpytorchで処理できるtensor形式に変換します。
dataset.append(encoding)#encoding結果をdataset_for_loaderのlistに追加します。
Python
#試しに一番初めのデータを確認してみましょう
#"input_ids", "token_type_ids", "attention_mask" に加えて、"labels"(正解情報)が付加された辞書を作れました。
#labelsが0なので、dokujo-tsushinになります。
print(dataset[0])
print(" ")
print("!!!データを確認するために、convert_ids_to_tokens関数を使って、日本語に戻してみましょう!!!")
print(" ")
print(tokenizer.convert_ids_to_tokens(dataset[0]["input_ids"]))

データローダーの作成
Python
#作成したデータセットをシャッフルした上で、訓練・評価・テストセットに分割します。
random.shuffle(dataset) # ランダムにシャッフル
n = len(dataset)
n_train = int(0.6*n)
n_val = int(0.2*n)
dataset_train = dataset[:n_train] # 学習データ
dataset_val = dataset[n_train:n_train+n_val] # 検証データ
dataset_test = dataset[n_train+n_val:] # テストデータ
# データセットからデータローダを作成
# 学習データはshuffle=Trueにする。
dataloader_train = DataLoader(dataset_train, batch_size=32, shuffle=True)
dataloader_val = DataLoader(dataset_val, batch_size=256, shuffle=False)
dataloader_test = DataLoader(dataset_test, batch_size=256, shuffle=False)
Python
#作成したデータセットの中身を確認してみましょう。
batch_sample = dataloader_train.__iter__().next()
print('batch_sample["input_ids"].shape :', batch_sample["input_ids"].shape)#input_idが(バッチサイズ, max_lengthとして指定した文章の長さの最大長さ)となっていることが確認できます。
print('batch_sample["labels"].shape :', batch_sample["labels"].shape)#labelsは(バッチサイズ)となっており、各記事に対応する正解ラベルの個数が入っています。

pytorch-lightningを用いた学習の実行
Python
class BertForSequenceClassification_pl(pl.LightningModule):
def __init__(self, model_name, num_labels, lr):
# model_name: 事前学習モデルの名前
# num_labels: メディアの種類数
# lr: TineTuningにおけるBERTモデルの学習率
super().__init__()
self.save_hyperparameters()
# BERT用いたを文章分類が簡単に実施できるモジュールです。
self.bert_sc = BertForSequenceClassification.from_pretrained(
model_name,
num_labels=num_labels
)
# 学習データのミニバッチ(`batch`)が与えられた時に損失を出力する関数を書く。
# batch_idxはミニバッチの番号であるが今回は使わない。
def training_step(self, batch, batch_idx):
labels = batch["labels"]
output = self.bert_sc(**batch)
accuracy = self.calc_acc(labels, output)
loss = output["loss"] #損失はoutputの中にlossとして格納されます。
self.log('train_acc', accuracy) # 精度を'train_acc'の名前でログをとる。
self.log('train_loss', loss) # 損失を'train_loss'の名前でログをとる。
return loss
# 検証データのミニバッチが与えられた時に、
# 検証データを評価する指標を計算する関数を書く。
def validation_step(self, batch, batch_idx):
labels = batch["labels"]
output = self.bert_sc(**batch)
accuracy = self.calc_acc(labels, output)
val_loss = output["loss"] #損失はoutputの中にlossとして格納されます。
self.log('val_acc', accuracy) # 精度を'val_acc'の名前でログをとる。
self.log('val_loss', val_loss) # 損失を'val_loss'の名前でログをとる。
# テストデータのミニバッチが与えられた時に、
# テストデータを評価する指標を計算する関数を書く。
def test_step(self, batch, batch_idx):
labels = batch.pop('labels') # バッチからラベルを取得
output = self.bert_sc(**batch)
accuracy = self.calc_acc(labels, output)
self.log('test_acc', accuracy) # 精度を'test_acc'の名前でログをとる。
#正解ラベルとモデルの出力を引数として、正解率を返す関数
def calc_acc(self, labels, output):
labels_predicted = output.logits.argmax(-1)
num_correct = ( labels_predicted == labels ).sum().item()
accuracy = num_correct/labels.size(0) #精度
return accuracy
# 学習に用いるオプティマイザを返す関数を書く。
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=self.hparams.lr)
TensorBoardの起動
%load_ext tensorboard
%tensorboard --logdir ./
Python
model = BertForSequenceClassification_pl(
model_name=model_name, #東北大BERTを事前学習モデルとして利用
num_labels=9, #メディアの種類数
lr=1e-5 #学習率
)
#callback関数の設定(advance)
#val_lossが最小のモデルの重みを保存する設定
checkpoint = pl.callbacks.ModelCheckpoint(
monitor='val_loss',
mode='min',
save_top_k=1,
save_weights_only=True,
dirpath = "model/")
#学習のパラメータを指定
trainer = pl.Trainer(
gpus=1 if torch.cuda.is_available() else 0,#GPUが利用可能であれば使う
max_epochs=5,#学習を早く完了させるため、エポック数は敢えて少なくしています
callbacks = [checkpoint] #指定したcallback関数の設定
)
#学習の実施
trainer.fit(model, dataloader_train, dataloader_val)
#最良の重みを読み込む
model = model.load_from_checkpoint(checkpoint_path=checkpoint.best_model_path)
#テストデータで精度を最終テスト
test = trainer.test(dataloaders=dataloader_test)
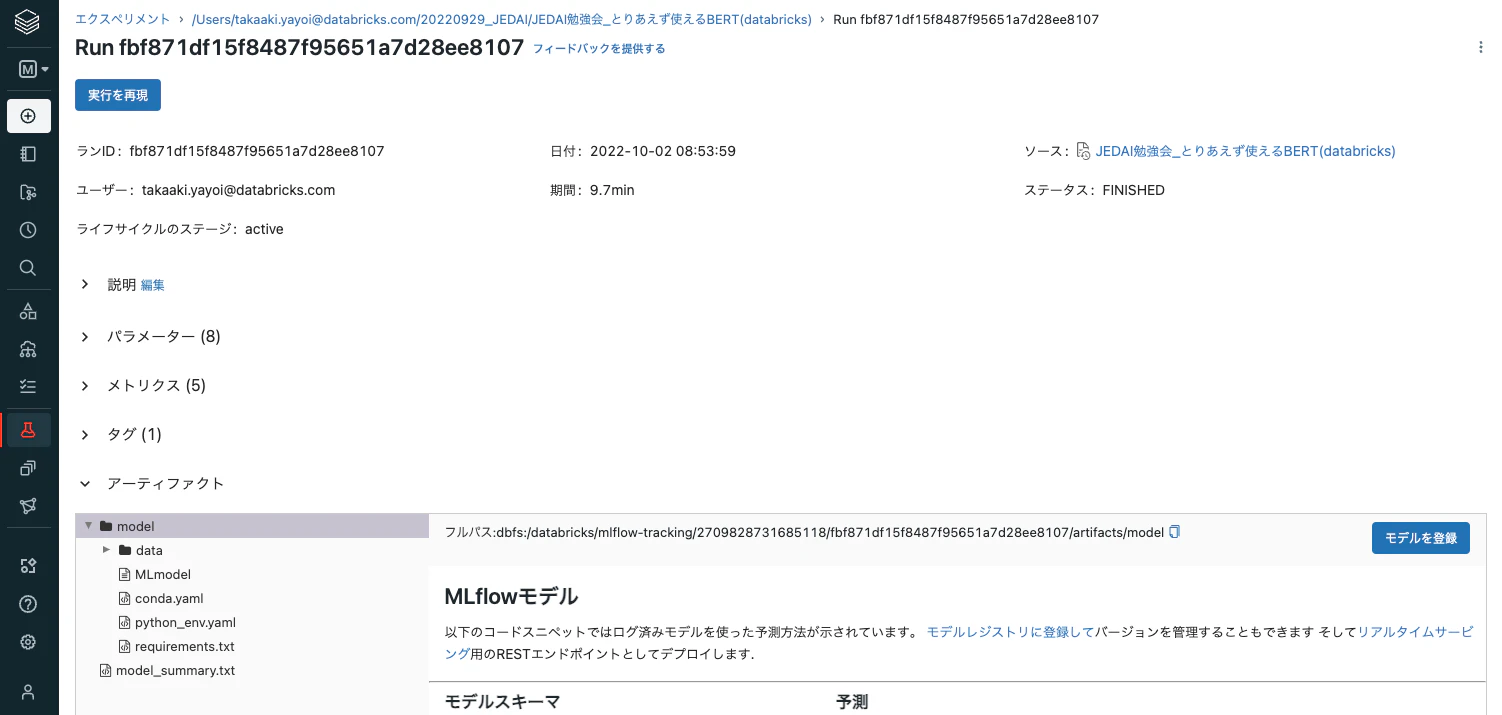
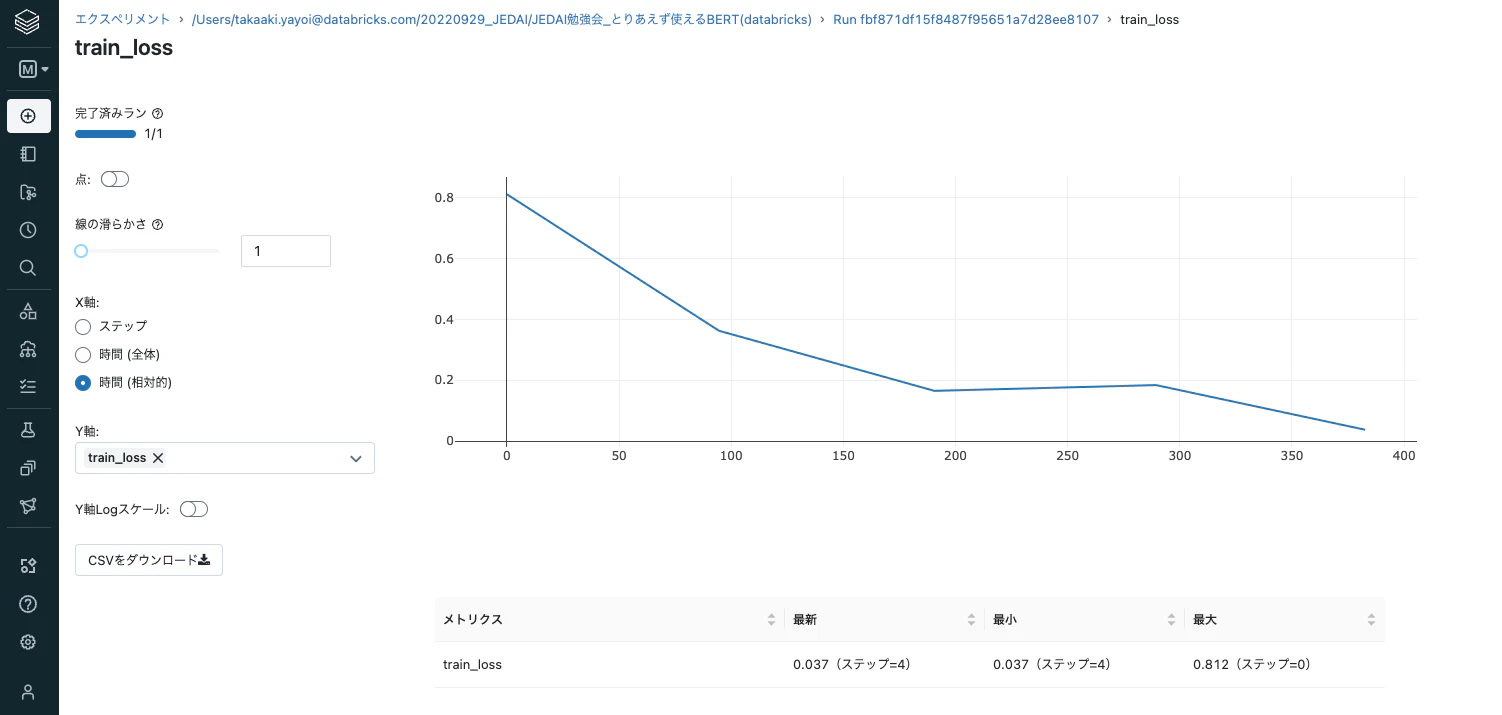
なお、上のセルを実行すると、MLflowの自動ロギングでモデルが記録されます。
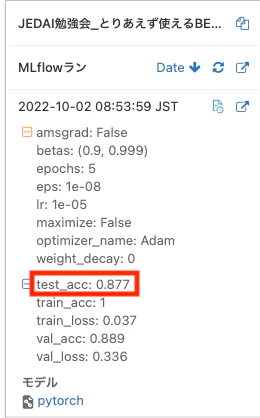
また、上で起動したTensorBoardで学習の進捗を確認することができます。
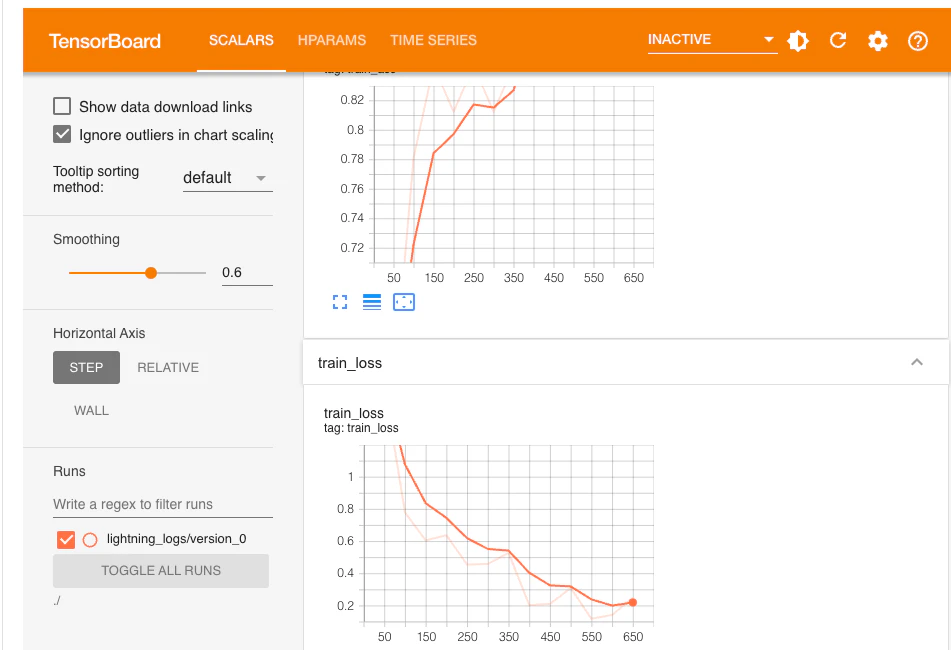
8割以上の正解率をもつモデルが作成できました!!!