What’s new with Unity Catalog at Data and AI Summit 2023 | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
プレビュー
本機能はパブリックプレビューです。
リアルタイムアプリケーションにおける機械学習モデルは、多くの場合において最も最新の特徴量の値を必要とします。例えば、レコメンデーションモデルは、店舗やレストランからの距離や、カート内のアイテムの総額のように、ユーザーの現在のシチュエーションに関する情報を必要とする場合があります。これらの特徴量の値は、推論時に計算される必要があります。
オンデマンド特徴量を活用するには、お使いのワークスペースでUnity Catalogを有効化し、Databricksランタイム13.3 LTS MLを使用する必要があります。
オンデマンド特徴量とは?
「オンデマンド」とは、事前には値が分かりませんが、推論時に計算される特徴量のことを指します。Databricksでは、どのようにオンデマンド特徴量を計算するのかを指定するために、Pythonユーザー定義関数(UDF)を使用します。これらの関数はUnity Catalogによって管理され、カタログエクスプローラでアクセスすることができます。
ワークフロー
オンデマンドで特徴量を計算するには、どのように特徴量を計算するのかを記述したPythonのユーザー定義関数(UDF)を指定します。
- トレーニングの際に、
create_training_setAPIのfeature_lookupsパラメータにこの関数と入力のバインディングを指定します。 - Feature Storeのメソッド
log_modelを用いてトレーニングしたモデルを記録する必要があります。これによって、モデルを推論で使用する際にモデルが自動でオンデマンドの特徴量を評価するようになります。 - バッチスコアリングでは、
score_batchAPIが自動で特徴量の値を計算し、オンデマンドの特徴量を含むすべての特徴量の値を返却します。 - Databricksのモデルサービングを用いてモデルをサービングする際には、それぞれのスコアリングのリクエストに対して、モデルはオンデマンドの特徴量を計算するために、自動でPython UDFを使用します。
Python UDFの作成
ノートブックあるいはDatabricks SQLでPython UDFを作成することができます。
例えば、ノートブックで以下のコードを実行すると、カタログmain、スキーマdefaultにPython UDF example_featureを作成します。
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int
return n1 + n2
return add_numbers(x, y)
$$
コードの実行後に、関数の定義を参照するためにカタログエクスプローラで3レベルの名前空間を通じてアクセスすることができます。
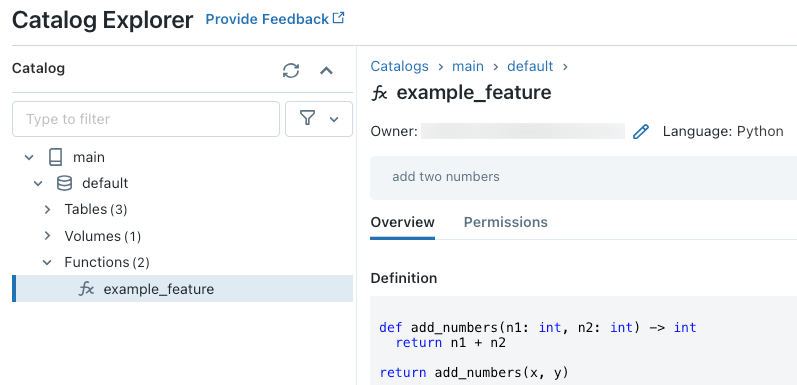
Python UDF作成の詳細については、Unity CatalogへのPython UDFの登録やSQL言語マニュアルをご覧ください。
オンデマンド特徴量を用いたモデルのトレーニング
モデルをトレーニングするには、create_training_set APIのfeature_lookupsパラメータに引き渡されるFeatureFunctionを使用します。
以下のサンプルコードでは、以前のセクションで定義したPython UDF main.default.example_featureを使用します。
from databricks.feature_store import FeatureFunction, FeatureLookup
from databricks.feature_store.client import FeatureStoreClient
from sklearn import linear_model
fs = FeatureStoreClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureStoreClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fs.create_training_set(
base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
モデルの記録およびUnity Catalogへの登録
特徴量のメタデータがパッケージングされたモデルは、Unity Catalogに登録することができます。モデルを作成するための特徴量テーブルは、Unity Catalogに格納する必要があります。
オンデマンド特徴量が推論で使用される際に、モデルが自動でオンデマンドの特徴量を評価するようにするには、以下のようにレジストリのURIを設定し、モデルを記録する必要があります。
import mlflow
mlflow.set_registry_uri("databricks-uc")
fs.log_model(
model,
"main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
オンデマンド特徴量定義するPython UDFがPythonパッケージをインポートする場合には、以下のように引数extra_pip_requirementsを用いてそれらのパッケージを指定する必要があります。
import mlflow
mlflow.set_registry_uri("databricks-uc")
fs.log_model(
model,
"model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
制限
オンデマンド特徴量は、MapTypeとArrayTypeを除くFeature Storeでサポートされている全てのデータタイプを出力することができます。