本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
ここで議論されているコードはこちらからアクセスできます。
この記事は、DatabricksノートブックとRepos APIを用いてどのようにエンドツーエンドのMLOpsソリューションを設定、構築するのかを説明するブログ記事シリーズのパート1です。この記事では、ノートブックをベースとしたDatabricksにおけるCI/CDフレームワークを説明します。継続的インテグレーション(CI)の部分に関しては、Microsoft Azure DevOpsのエコシステムとインテグレーションし、継続的デリバリー(CD)に関してはRepos APIと連携します。次の記事では、Databricks上で完全なCI/CDライフサイクルを実装し、完全なMLOpsソリューションに拡張するために、どのようにRepos APIを使用するのかを説明します。
Databricks ReposによるCI/CD
幸運なことに、DatabricksのReposとRepos APIによって、MLOpsアプローチの土台となるバージョン管理、テスト、パイプラインすべての主要な側面全てをカバーできる準備が整います。DatabricksのReposによって、gitリポジトリ全体をDatabricksにクローンすることができ、Repos APIを用いることで、最初にgitリポジトリをクローンし、必要なブランチをチェックアウトすることで、このプロセスを自動化することができます。ML実践者はモジュールを実装する際、ノートブックや.pyファイルを用いてプロジェクトを構造化(Reposにおける任意のファイルのサポートはロードマップで計画されています)するために、IDEから慣れ親しんだリポジトリの構造を利用することができます。これにより、お好きなツール(Github、Gitlab、Azure Reposなど)でプロジェクト全体のバージョン管理を行い、一般的なCI/CDパイプラインと連携することができます。Databricks Repos APIを用いることで、特定のgitブランチの最新バージョンにrepo(GitプロジェクトはDatabricksでrepoとしてチェックアウトされます)をアップデートすることができます。
チームは、開発において典型的なGitフロー、GitHubフローに従うことができます。Gitリポジトリ全体をDatabricks Reposでチェックアウトすることができます。任意ファイルのサポートにより、ユーザーはプレーンなPythonファイルやノートブックを編集、使用することができます。これによって、古典的なプロジェクトの構造を使用することができ、Pythonファイルからモジュールをインポートし、ノートブックと組み合わせることができます。
- フィーチャーブランチで個々の機能を開発し、ユニットテストによるテストを実施(例:実装したノートブック)。
- CI/CDパイプラインがインテグレーションテストを実行するフィーチャーブランチに変更をプッシュ。
- このテストプロジェクトを最新バージョンにアップデートされるように、Azure DevOpsのCI/CDパイプラインがDatabricks Repos APIをキック。
- CI/CDパイプラインがJobs APIを通じてインテグレーションテストのジョブをキック。最初にテストの設定を用いてテストを行うパイプラインを実行する、シンプルなノートブックとしてインテグレーションを実装することも可能。これは、対応するモジュールを実行する適切なノートブック、あるいはjobs APIを用いて本当のジョブをトリガーすることで実現が可能。
- 結果を検証し、テスト全体をグリーンあるいはレッドとしてマーク。

上で述べた内容をどの様に実装できるのかを見ていきましょう。サンプルワークフローとして、KaggleのLending Clubコンペティションから得られるデータにフォーカスします。多くの金融機関と同様に、例えば、申請者のクレジットスコアを評価するために、個々人の収入データを理解し予測したいとします。このためには、申請者の様々な特徴量、属性、例えば現在の職業、持ち家の有無、学歴、位置情報、結婚・未婚、年齢を分析します。これは銀行が収集する情報(例:過去のクレジット申請で)であり、回帰モデルをトレーニングするために、これを活用します。
そして、我々はビジネスはダイナミックに変化することを知っており、日々新たな発見が大量に発生しています。新規データを定期的に取り込むことになるので、モデルの再学習が重要となります。このため、全体的な継続的開発パイプラインに加え、再トレーニングのジョブの完全自動化にもフォーカスします。高品質の成果および高い予測能力を保証するために、それぞれのトレーニングジョブのあとに評価ステップを追加します。ここでは、MLモデルは整理されたデータセットに対するスコアリングを行い、現状デプロイされているプロダクションのバージョンと比較を行います。結果として、新規モデルがより優れた予測能力を持っている場合にのみ、モデルの昇格が行われます。
プロジェクトにおいては、アクティブに開発が行われるので、新規コードの完全自動テスト、ライフサイクルにおける次ステージへのプロモーションでは、プッシュ/プルリクエスト時にユニット/インテグレーションの評価を行うために、Azure DevOpsフレームワークを活用します。テストはAzure DevOpsフレームワークを通じてオーケストレーションされ、Databrikcsプラットフォームで実行されます。これは、プロセスのCIパートをカバーし、コードベースに対する高いテスト網羅性を保証し、人手による監視を最小化します。
継続的デリバリーのパートではRepos APIのみを活用します。プログラミングインタフェースを通じて、Gitブランチ上の最新のバージョンをチェックアウトし、ワークロードを実行する際に最新のスクリプトをデプロイします。これにより、アーティファクトのデプロイプロセスをシンプルなものにし、テストしたコードバージョンを開発環境、ステージング環境、プロダクション環境へと容易にプロモーションすることができます。このようなアーキテクチャによって、様々な環境の完全に分離することができ、増加しているセキュアな環境においては特に好ましいものとなります。異なるステージ: バージョン管理システムのみを共有するdev、staging、prodによって、非常に重要なプロダクションワークロードとの潜在的な干渉を最小化することができます。同時に、探索的な作業やイノベーションの取り組みは、より緩和されたアクセス制御を持つdev環境として分離されます。
Azure DevOpsとDatabricksを用いたCI/CDパイプラインの実装
以下のコードリポジトリにおいては、Azure DevOpsによるCI/CDパイプラインを用いたMLプロジェクトを実装しました。このプロジェクトにおいては、データ準備とモデルトレーニングのノートブックを使用しています。
これらのノートブックをDatabricks上でどの様にテストするのかを見ていきましょう。Azure DevOpsは、Azureで利用できる完全なCI/CD向けの非常に人気のあるフレームワークです。詳細に関しては、提供機能の概要およびDatabricksにおける継続的インテグレーションを参照ください。
ここでは、Azure DevOpsパイプラインをYAMLファイルとして取り扱います。このパイプラインはDatabricksノートブックをシンプルなPythonファイルとして取り扱うので、これらをCI/CDパイプライン内で実行することができます。ここで使用するAzure CI/CDパイプラインのYAMLファイルを、azure-pipelines.ymlに含めています。このファイルで最も興味深い部分は、Databricks上のCI/CDプロジェクトの状態をアップデートするためにDatabricks Repos APIをコールする部分と、インテグレーションテストジョブを実行するためにDatabricks Jobs APIをコールする部分です。これら両方をdeploy.pyスクリプト/ノートブックで開発しています。Azure DevOpsパイプラインの中で以下の様にして呼び出すことができます。
- script: |
python deploy/deploy.py
env:
DATABRICKS_HOST: $(DATABRICKS_HOST)
DATABRICKS_TOKEN: $(DATABRICKS_TOKEN)
displayName: 'Run integration test on Databricks'
DATABRICKS_HOSTとDATABRICKS_TOKEN環境変数は、databricks_cliパッケージが対象のDatabricksワークスペースに対して認証されるために必要となります。これらの変数をAzure DevOps変数グループで管理することもできます。
deploy.pyスクリプトの中を見ていきましょう。スクリプトでは、Databricks Jobs APIを操作するためにdatabricks_cli APIを使用していいます。最初に、APIクライアントを作成する必要があります。
config = EnvironmentVariableConfigProvider().get_config()
api_client = _get_api_client(config, command_name="cicdtemplates-")
次に、プロジェクトのためのテンポラリーのRepoをDatabricks上にさうk製紙、新規作成したRepoに最新バージョンをプルします。
# Let's create Repos Service
repos_service = ReposService(api_client)
# Let's store the path for our new Repo
repo_path = f'{repos_path_prefix}_{branch}_{str(datetime.now().microsecond)}'
# Let's clone our GitHub Repo in Databricks using Repos API
repo = repos_service.create_repo(url=git_url, provider=provider, path=repo_path)
# Let's checkout the needed branch
repos_service.update_repo(id=repo['id'], branch=branch)
そして、Databricks上でインテグレーションテストのジョブの実行をキックします。
res = jobs_service.submit_run(run_name="our run name", existing_cluster_id=existing_cluster_id, notebook_task=repo_path + notebook_path )
run_id = res['run_id']
最後に、ジョブの完了を待って結果を検証します。
while True:
status = jobs_service.get_run(run_id)
print(status)
result_state = status["state"].get("result_state", None)
if result_state:
print(result_state)
assert result_state == "SUCCESS"
break
else:
time.sleep(5)
複数のワークスペースでの作業
CDにDatabricks Repos APIを使用することは、特にdev/staging/production環境を改善に分類したいと願うチームにとって有用なものとなります。この新機能によって、データチームは、Databricks上のソースコードを用い、シンプルなコマンドインタフェースを通じて複数環境に対して、ワークロードに対する最新のコードベースとアーティファクトをデプロイすることができる様になります。バージョン管理システムにおける最新コードベースをプログラムからチェックアウトできることで、即時かつシンプルなリリースプロセスを保証します。
MLOpsのプラクティスに関しては、様々な環境における適切なアーキテクチャ上の設定に対する深刻かつ多数の検討が必要となります。この研究では、完全分離のパラダイムのみにフォーカスしていますが、これはdev/staging/prodに関連づけられたMLflowインスタンスにも適用できます。この場合、dev環境でトレーニングされたモデルは、単体の共通モデルレジストリを通じてシリアライズされたオブジェクトとして次のステージにはプッシュされません。デプロイされるアーティファクトは、STAGING環境でリリース、実行された新規トレーニングパイプラインのコードベースのみとなり、新たにトレーニングされたモデルがMLflowに登録されることになります。
このシェアードナッシング原則とprod/stagin環境における厳密なアクセス権管理(dev環境においては緩和されたアクセスパターンを実装)を組み合わせることで、堅牢かつ高品質なソフトウェア開発を実現します。同時に、devインスタンスにおいては高い自由度を提供し、データチームにおけるイノベーションと実験を加速します。
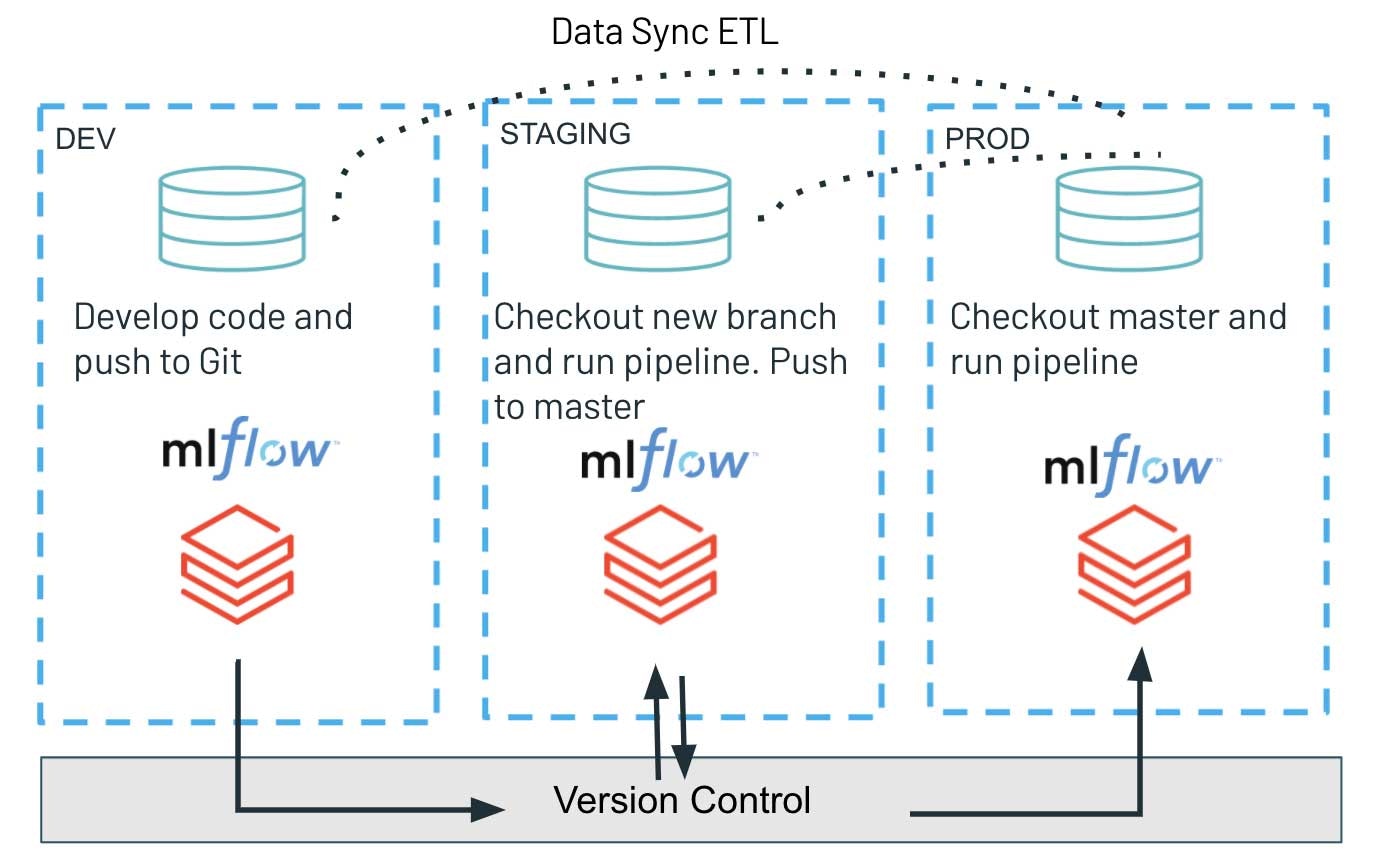
共有バージョン管理システム、およびPRODから他の環境にデータを同期することによるdev/staging/prod環境の設定
まとめ
この記事では、ノートブックベースのプロジェクトを用いたDatabricksにおけるCI/CDパイプラインに対するエンドツーエンドのアプローチを説明しました。このワークフローはRepos APIの機能をベースとしおり、データチームが自身のプロジェクトをより実践的な方法で構造化、バージョン管理できる様にするだけでなく、CI/CDツールの実装、実行を劇的にシンプルなものにします。すべての運用環境が完全に分離され、MLを用いたプロダクションワークロードの高レベルなセキュリティを実現するアーキテクチャを説明しました。
お使いのフレームワークを用いてCI/CDパイプラインを構築し、Databricksのレイクハウスプラットフォームとシームレスに統合し、コードとエンドツーエンドを提供するインフラストラクチャの実行をトリガーすることができます。Repos APIはバージョン管理、コードの構造化、プロジェクトライフサイクルの開発パートを抜本的にシンプルなものにするだけでなく、継続的デリバリーもシンプルなものにし、環境にまたがってプロダクションアーティファクト、コードをデプロイすることができる様になります。これはDatabricksに全体的な効率性、スケーラビリティを追加する重要な改善であり、ソフトウェア開発体験を劇的に改善します。
ここで議論されているコードはこちらからアクセスできます。
リファレンス
- https://databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- Continuous Delivery for Machine Learning, Martin Fowler, https://martinfowler.com/articles/cd4ml.html,
- Overview of MLOps, https://www.kdnuggets.com/2021/03/overview-mlops.htm Introducing Azure DevOps, https://azure.microsoft.com/en-us/blog/introducing-azure-devops/
- Continuous integration and delivery on Azure Databricks using Azure DevOps, https://docs.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops
- Lending club Kaggle data set https://www.kaggle.com/wordsforthewise/lending-club
- Databricks ReposによるGit連携 - Qiita https://qiita.com/taka_yayoi/items/b89f199ff0d3a4c16140
パート2はこちら。