Making Transformer-Based Models First-Class Citizens in the Lakehouse | by Tim Lortz | Mediumの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2022年の記事です。
本書では、Databricksのレイクハウスアーキテクチャに事前学習済みトランスフォーマーベースのNLPモデルを導入する実装パターンを説明します。特に、オープンソースのMLflowを用いてビジネス固有のタスクに事前学習済みトランスフォーマーモデルを導入し、後段でレイクハウスで使用するカスタムモデルをパッケージングするシンプルな方法を説明します。なぜこれらが重要なのでしょうか?
- ビジネスでNLPを活用する際、多くのモデルを取り扱うことになるでしょう。モデルのパッケージングやレジストリを含むMLOpsの管理において、MLflowより人気のあるオープンソースフレームワークは存在しません。MLOpsをシンプルにするための一つのフレームワーク上において、一箇所ですべてのモデルを管理します。
- モデルの推論は多くの形態を取り、最も一般的なものは: バッチ、ストリーミング、RESTエンドポイントです。MLflowはこれらの形態のそれぞれに簡単に同じモデルを適用することができます。そして、Databricks上でMLflowを活用することで、これらのデプロイメント形態のそれぞれにおける、計算リソース、ホスティングのインフラストラクチャ、セキュリティ、権限管理、モニタリングを管理することができます。
- ML実践者は、モデルのライフサイクル管理においてデータ中心のアプローチを取ることの重要性に気づき始めています。レイクハウスアーキテクチャは主要なデータユースケースに対応できる効率的かつ効果的な方法として認知されてきています: ETL/ELT、ストリーミング、SQLクエリー、BIなどMLなどです。そして、Databricksは業界最先端のレイクハウスオファリングを提供します。信頼するデータソースからデータをエクスポートしたり、MLやMLOpsを実現するために別のプラットフォームを購入する必要はありません。ですので、あなたのデータチームの皆さんで活用されるトランスフォーマーベースのモデルを、同じプラットフォームで開発、登録、デプロイすることで、皆様の企業を勝者にするのです。
トランスフォーマーの勃興
トランスフォーマーディープラーニングアーキテクチャや、学会や業界に対するインパクトの多くが説明されており、それは2017年の論文Attention is All You Needからスタートし、トランスフォーマーアーキテクチャで構築されたモデルによって席巻されている現在のSOTA NLPベンチマークにまで至っています。例えば、Question AnsweringやMachine Translationなどです。また、トランスフォーマーモデルは他のアプリケーション: computer vision、audio、time seriesなどでも活用されています。Courseraではこれらのモデルの活用に関する包括的なコースも提供されています。わかりましたか!
これらの普及は、トランスフォーマーベースのモデルをよりアクセスしやすく、利用しやすくすることをリードしているソフトウェア企業のHuggingfaceのModel Hubでも確認できます。彼らの努力とユーザーコミュニティの拡大によって、NLP、コンピュータービジョン、音声、表データ、マルチモーダル、強化学習をカバーするダウンロード可能なオープンソースモデルを見つけ出すことができます。
Huggingfaceで利用できるモデルの機械学習タスクタイプ
Huggingfaceの偉大な貢献には以下のようなものがあります:
- 最先端の学習済みモデルを容易にダウンロード、トレーニングするための標準APIセットを持つTokenizersとTransformersライブラリのリリース
- エンドツーエンドのトランスフォーマーベースのアーキテクチャをカプセル化し、テキスト生成、画像分類、音声分類のような様々なタスクにおける推論のためのモデルハブのすべてのモデルの活用をシンプルにするPipelineのコンセプトの創出
- 公開ハブにおけるオープンな事前学習済みトランスフォーマーのホスティング。これらの多くは、オープンソースのHuggingfaceライブラリのシンプルなAPIを用いて誰でも簡単にダウンロードできます。さらに、モデルハブは増加し続けるユーザーベースからの貢献を受け入れています。このため、主要なタスクの多くには、選択できる複数の学習済みモデルがあり、モデル利用者はモデルを選択する際に、モデルサイズ、ベンチマークの精度、モデルアウトプットの構造を考慮することができます。NLP、コンピュータービジョンなどから真のゲームチェンジャーがスタートしています!
これで、ある程度トランスフォーマーベースモデルの認識と使い始めることが簡単であるという理解を持つことができたので、これらをどのようにレイクハウスアーキテクチャのプロダクションデータパイプラインにフィットさせることができるのかに注意を払いましょう。
MLflowとトランスフォーマー
上述したように、MLflowはMLOpsにおいて世界で最も人気のあるオープンソースフレームワークとなっています。 MLflowは4つのコンポーネントから構成されます: トラッキング、プロジェクト、モデル、レジストリです。(5つ目のコンポーネントであるパイプラインが、MLflow 2.0の取り組みの一部としてData & AIサミット2022で発表されました)。これらのコンポーネントは、エンドツーエンドの機械学習ライフサイクルをサポートするために連携して動作します。完全なMLflowのワークフローは以下のようなものとなります:

MLflowによるモデルライフサイクル管理
MLflowには、scikit-learn, Keras, PyTorch and Apache Spark MLlibのような非常に一般的なフレームワーク付を含むモデルの「フレーバー」の大規模セットをネイティブサポートしています。Huggingfaceトランスフォーマーライブラリは、ネイティブのMLflowモデルフレーバーがありませんが、Python function、PyTorch、TensorFlowモデルフレーバーでHuggingfaceモデルを適応させることができます。私の経験では、トランスフォーマーモデルを用いたカスタムNLP推論パイプラインの作成では、Python関数が最もわかりやすく柔軟なフレーバーなので、ここではこれを説明します。
本書は、MLflowでトランスフォーマーベースのモデルのインテグレーションに取り組んだ最初の記事ではありません。これまでに知った一連の記事に言及しないのは怠慢とも言えるでしょう:
- このMediumの記事は、MLflowのPython関数モデルにHuggingfaceトランスフォーマーモデルを記録するエレガントな方法を説明しています。非常におすすめです!私のワークフローは、同様な方法でスタートしていますが、アーティファクトの取り扱いと、カスタム推論ロジックの組み込み方法が若干違います。また、RESTエンドポイントに加えてバッチ推論パイプラインでの登録モデルの活用方法も説明します。
- 私のDatabricksの同僚の一人が、お使いのDelta LakeのDeltaテーブルに対するテキスト分類タスクのために様々な事前学習済みトランスフォーマーを適用するすぐに利用可能なワークフローをGithubリポジトリにまとめています。このリポジトリは、テキスト分類タスクに事前学習済みモデルをファインチューニングし、同じプロジェクトからスケジュール推論ジョブをデプロイしたい際には非常に便利です。ここで示すのは、このリポジトリの補完的なものであり、多くはカスタム推論ロジックと様々な事前学習済みモデルを導入することにフォーカスしています。
MLflowにおけるカスタムトランスフォーマーモデルの作成
以下の実装の詳細の全ては、Databricksで実行されています。一般的に言って、これらは適切な環境(特にMLflowとApache Spark)であればいかなる開発環境でも動作します。しかし、Databricksはスケーラブルな機械学習環境を実現しており、信じられないほど管理が簡単なので、私はこれを活用します!我々のサンプルは、dslim/bert-base-NERモデルを用いた固有表現抽出(NER)です。
トランスフォーマーモデルのアーティファクトの取り扱い
トランスフォーマーモデルは非常に大きくなる傾向があります。本書で使用するBERTのようなエンコーダーのみのモデルの中で、PyTorchモデルのサイズには、270 MB (distilbert-base-uncased), 440 MB (bert-base-uncased)や1.4 GB (roberta-base-large)などがあります。生成型モデルは、さらに大きくなる傾向があり、gpt2-largeの重みは3.25 GBになります。そして、これらのモデルを活用するには、シリアライズされたモデルオブジェクトだけではなく、モデル設定ファイル、ボキャブラリー、トークナイザーのマッピング、そのほかの周辺ファイルも必要となります。これらすべては、一貫性があり信頼できるモデルでは連携して動作しなくてはなりません。いうまでもありませんが、アーティファクト管理を適切に行うことが重要となります!
この記事と類似のアプローチを採用し、トランスフォーマーライブラリのネイティブの.save_pretrained()メソッドを活用します。
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
model_name = "dslim/bert-base-NER"
base_data_path = <path in cloud storage, accessible to Databricks, where you want to temporarily store the model artifacts>
tokenizer = AutoTokenizer.from_pretrained(model_name, padding=True)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer, device=device)
nlp.save_pretrained(base_data_path)
カスタムモデル推論ロジックの取り扱い
このNERタスクの例では、モデルに対して幾つかのカスタムの前処理、後処理を行いたいと考えています。これらのアクションのコアになるのは、上でロードしたNERパイプラインのインスタンスの呼び出しです。Transformers pipeline classは、受け取る入力タイプにおいて非常に柔軟であり、文字列、リスト、ジェネレーター、データセットを受け取ることができます。この柔軟性は、MLflowで完全にサポートされており、これらのいかなる入力タイプでも期待されるスケールとスピードをサポートするモデルをデプロイすることができます。
私が選択したデザインでは、単一レコード、小規模バッチ、大規模バッチデプロイメントをサポートするPandasデータフレームカラムで入力ドキュメントを受け取ります。上述したように、MLflow Python functionフレーバーを活用します。このカスタムモデルフレーバーは4つの基本的な引数を受け付けます:
- ローダーモジュール(必須)
- カスタムコード(オプション)
- カスタムモデルデータ(オプション)
- conda環境仕様(オプション)
MLflowクライアントに対する単一コールでモデルをパッケージする前に、これらをウォークスルーしましょう。。
ローダーモジュール
このコードは、MLflowトラッキングサーバーからモデルがロードされる際に呼び出されます。これは、NERパイプラインをロードするために上で見たコードとほぼ同じものになることに注意してください。また、GPUがサービング環境で利用できる際には活用するようにしています。大規模な入力バッチにおいては、GPUは非常に高速なものとなります。
def _load_pyfunc(data_path):
device = 0 if torch.cuda.is_available() else -1
tokenizer = AutoTokenizer.from_pretrained(data_path, padding=True)
model = AutoModelForTokenClassification.from_pretrained(data_path)
nlp = pipeline("ner", model=model, tokenizer=tokenizer, device=device)
return TransformerNERModel(nlp)
カスタムの前処理、後処理コード
このコードをMLflowモデルに追加する価値は、任意の推論ロジックを持てるようになるということです。メインの要件は、クエリーの評価に使用されるpredict()メソッドです。predict()メソッドは、Inference APIに準拠しなくてはなりません。
class TransformerNERModel(mlflow.pyfunc.PythonModel):
def __init__(self, model):
self._model = model
def _extract_entities(self, ner_list):
if len(ner_list) > 0:
return [(e["entity"], e["word"]) for e in ner_list]
else:
return []
def predict(self, df):
texts = df.content.values.tolist()
ids = df.id.values.tolist()
text_ner = self._model(texts, batch_size=2)
ner_extracted = list(map(self._extract_entities, text_ner))
df_with_ents = pd.DataFrame({"id": ids, "content": texts, "ner_extracted": ner_extracted})
return df_with_ents
カスタムモデルデータ
ローカル(あるいはクラウド)ストレージにモデルアーティファクトを永続化するために、上でnlp.save_pretrained(base_data_path)を呼び出しました。
conda環境
これは、モデルの再現性、特にモデルをコンテナにデプロイする際には重要となります。
{
"name": "transformers_ner_env",
"channels": ["defaults"],
"dependencies": [
"python=3.8.10",
"pip",
{
"pip": ["mlflow",
"pandas",
"torch",
"transformers"
]
}
]
}
実際は、カスタムモデルコードは、GitHubのリポジトリで行なっているように、ローダーモジュールファイルにカスタムモデルコードを含めることができます。
MLflowでのモデルのパッケージング
すべての材料が揃いましたので料理しましょう!すべてを単一のモデルにパッケージするために、MLflow Python APIコールのmlflow.pyfunc.log_model()を活用します。この例では、上述したGitHubリポジトリをDatabricksワークスペース(ここでのパスプレフィクスは/Workspace/Repos/tim.lortz@databricks.com/transformers-mlflow-templates/です)にクローンするために、Databricks Reposの機能を使いました。これは、レイクハウスプラットフォームの価値を強調するものです。NLPアプリケーションを開発するために好きなIDEを活用し、GitHubに同期し、Databricksクラスターで実行し、ホストされているMLflowサービスで実験やモデルを追跡します。すべてがオープンソース標準です!
import os
code_root_path = "/Workspace/Repos/tim.lortz@databricks.com/transformers-mlflow-templates/"
f = open(os.path.join(code_root_path ,"conda_envs/conda_ner.json"))
conda_env = json.load(f)
f.close()
with mlflow.start_run(run_name="NER") as run:
mlflow.pyfunc.log_model(artifact_path="ner", loader_module="ner_transformers", \
conda_env=conda_env, \
code_path=[os.path.join(code_root_path,"pyfunc_modules/ner_transformers.py")],\
data_path=base_data_path,
registered_model_name="ner_transformers")
こちらが、この呼び出しによってMLflowトラッキングサーバーに記録された結果となります。すべてのモデルアーティファクトとカスタムコードが一ヶ所に収まっています。

上で実行した実験に対するMLflowトラッキングサーバーのコンテンツ
log_model()の呼び出しに一つの引数registered_model_nameを追加していることに気づいたかもしれません。これを行うことで、モデルをどこに保存したのかに関して気にする必要がなくなり、MLflowモデルレジストリから名前でモデルを参照できるようになります!このモデルレジストリは、バージョン管理、ステージ昇格、メタデータのタグ付け、アクセスコントロールのようなキーとなるライフサイクル管理の機能を追加するので、モデルはレイクハウスの一級市民となります。これで、推論パイプラインの名前やバージョン、ステージでモデルを参照することができます。
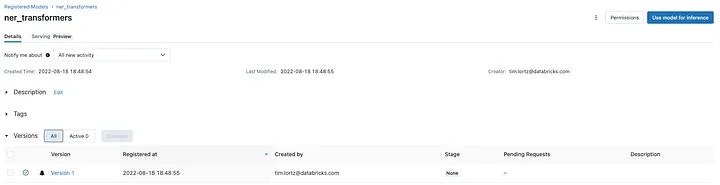
本書で記録されたNERモデルのMLflowモデルレジストリのエントリー
カスタムMLflowトランスフォーマーモデルの推論パイプラインへの組み込み
小規模データ、リアルタイム(REST API)
RESTエンドポイントとしてモデルをサービングすることは、人気のあるデプロイメント方法です。MLflowは、いくつかのメカニズムを通じて適切にパッケージされたモデルのサービングを容易にします:
-
mlflow models serveによるローカルのウェブサーバー(docs) -
mlflow models build-dockerによるDockerコンテナの構築(docs) -
mlflow sagemaker配下の一連のコマンドによるAWS Sagemakerで管理されるエンドポイント(docs) - Microsoftマネージドの
azureml-mlflowプラグインを通じたAzureMLマネージドのエンドポイント(docs)
これらの選択肢のどれもが素晴らしいものです。しかし、Databricksでマネージドかつセキュアなエンドポイントへのモデルのデプロイメントは1クリックの操作です。2つの基本的な選択肢があります:
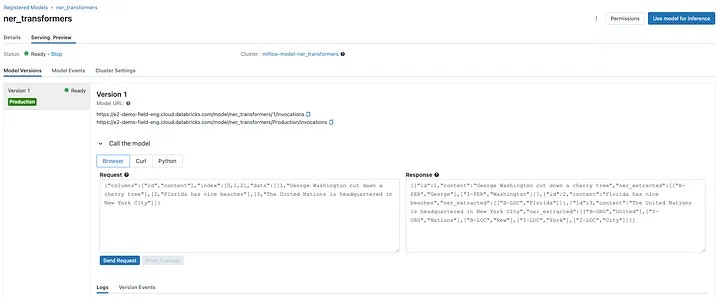
この記事で作成したモデルのDatabricks MLflowクラシックモデルサービング推論
任意のデータサイズ、バッチあるいはストリーミング
RESTエンドポイントとしてのMLモデルのデプロイは人気で魅力的ですが、これが唯一のデプロイ方法ではありません。データインプットサイズや速度が増加すると、RESTエンドポイントの便利さはすぐに損なわれ、パフォーマンスは劣化し、コストが増加します。バッチ推論のユースぇーすは多数存在します。それでは、バッチ推論パイプラインの環境でのサンプルを完成させましょう。
MLflowトラッキングサーバーのスクリーンショットで、記録されたNERモデルを推論に活用するためのいくつかのコードスニペットに気づかれたかもしれません。特に、MLflowは、(Spark UDF経由での)Sparkや(MLflow Python関数経由での)Pandasデータフレームでの予測生成のテンプレートを提供しています。

記録されたMLflow Python関数モデルの予測に対する自動生成パターン
これらの選択肢の両方でも構いません。我々の例では、2つ目の選択肢も動作するでしょう:
import mlflow
import pandas as pd
model_name = "ner_transformers"
test_df = pd.DataFrame({"id":[1,2,3], "content": ["George Washington cut down a cherry tree",\
"Florida has nice beaches",\
"The United Nations is headquartered in New York City"]
}
)
ner_loaded = mlflow.pyfunc.load_model(f"models:/{model_name}/Production")
results = ner_loaded.predict(test_df)
pd.set_option('display.max_colwidth', None)
results.head()

Pandasのテスト入力に対するNERモデルの結果
しかし、大規模な入力セットに対してモデルを実行したいと考えているので、ここでは2つの組み合わせである3番目の選択肢を採用します。標準的なSpark UDFではなく、MLflow Python関数をPandas UDFとしてパッケージします。なぜなのでしょう?これは、標準的なPySpark UDFは一度に一行しか操作せず、苦痛になる程遅いためです。Pandas UDFは、Sparkデータフレームのパーティション全体をPandasデータフレームとしてシリアライズし、UDFに含まれるネイティブなPythonの変換ロジックをPandasデータフレームに対して適用し、PandasデータフレームをSparkデータフレームとしてデシリアライズすることで、このボトルネックを解消します。結果として得られるパフォーマンスのブーストは正当なものであり、Databricks docsは、最大100倍と言っており、実際にお客様においても同様の結果を目撃しています。Apache Sparkを取り扱っているすべてのデータサイエンティストにとって、Pandas UDFは道具箱に入れておくべき標準ツールです!
注意
本書のHuggingfaceモデルと関連するようなアーティファクトを必要とするMLライブラリとApache Sparkを使用する際、これらのアーティファクトは推論ジョブを実行するSparkエグゼキューターのそれぞれにロードされる必要があります。このため、以下のPandas UDFのコードはモデルロードのステップからスタートしています。非常に大きなモデルを取り扱う際、これはSparkクラスターのアウトオブメモリー問題(特にGPUメモリー)に直面することがあり、Sparkクラスターのインスタンスタイプや並列度を選択する際にはモデルサイズに注意してください。Sparkの性能を最大化するためには少数かつ大規模なインスタンスタイプを選択することが一般的にはベストプラクティスですが、このケースでは多量かつ小規模インスタンスを使った方が良い場合もあります。
import mlflow
import pandas as pd
from pyspark.sql import functions as F
from pyspark.sql.types import *
from sklearn.datasets import fetch_20newsgroups
# identify the model we'll pull from the model registry
model_name = "ner_transformers"
# great open-source dataset with lots of named entities in it
newsgroups_train = fetch_20newsgroups(subset='train')
df_news = pd.DataFrame({'id':[_ for _ in range(len(newsgroups_train.data))], 'content':newsgroups_train.data})
# convert pandas dataframe to Spark dataframe, and force Spark to partition the dataframe across all available executors
df_news_spark = spark.createDataFrame(df_news).repartition(spark.sparkContext.defaultParallelism).cache()
# inferencing function we'll distribute as a Pandas UDF
def ner_predictions_function(df):
ner_loaded = mlflow.pyfunc.load_model(f"models:/{model_name}/Production")
return ner_loaded.predict(df)
# the Spark Pandas function API requires a return value schema
schema = StructType(
[
StructField("id", LongType(), True),
StructField("content", StringType(), True),
StructField("ner_extracted", ArrayType(ArrayType(StringType())), True)
]
)
# actual NER inference on the Spark dataframe
df_news_ner = (
df_news_spark\
.groupBy(F.spark_partition_id().alias("_pid"))\
.applyInPandas(ner_predictions_function, schema)
).cache()
# viewing the results dataframe in a Databricks notebook
display(df_news_ner)
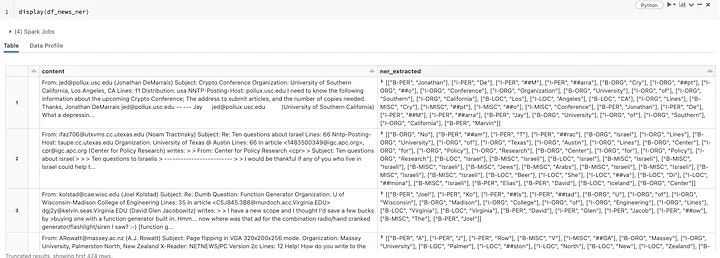
Transformers、MLflow、Sparkによる20のニュースグループデータセットに対するNER抽出
8台のg4dn.xlargeワーカーインスタンス(16 GB memory, 4 vCPUs, 1 GPU)と、8パーティションのSparkデータフレーム(ワーカーあたり1パーティション)を用いると、この処理は11k+以上のニュースグループの投稿に対して2.3分要しました。Sparkなしでpandasデータフレームに対してトランスフォーマーモデルを実行した際には6.7分要したことと比較すると、SparkとPandas UDFの活用のメリットを感じることができます。真の企業規模の出tー他セットにおいては、このインパクトはさらに顕著なものとなります。1分ほどの推論時間はモデルのロードによるものであるため、データサイズが増えるほど、並列度によるスピードアップ、この場合は8倍、が効果的となるでしょう。
まとめ
MLflowやApache Sparkのようなオープンソースの美点を活用することで、レイクハウスアーキテクチャにおいてトランスフォーマーベースのモデルがふどのように一級市民になるのかをデモンストレーションしました。以下のことを説明しました。
- どのように事前学習済みトランスフォーマーベースモデルを取得し、カスタムの推論ロジック、データ取り扱いロジックを追加し、MLflowモデルフレーバーにパッケージするのか。
- どのようにMLflowに登録されたカスタムモデルを取得し、最も一般的なデプロイメントモードのいずれかにデプロイするのか: RESTエンドポイントあるいはバッチ。
- 大規模入力セットのバッチ推論をスケールアップするために、どのようにApache Sparkを活用するのか。
- これらすべては単一のプラットフォーム(Databricks)で実現することができ、MLエンジニアは、自分でクラウドインフラストラクチャを管理したり、真のソースからデータを移動する必要がありません。
楽しんでいただけたら何よりです。レイクハウスにおける機械学習に関する追加の記事を楽しみにしていてください!