Scaling Hyperopt to Tune Machine Learning Models in Pythonの翻訳です。
注意
- 本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
- 2019年の記事です。
以下で説明されているステップを再現するためにHyperoptのノートブックをトライしてみてください。詳細はオンデマンドのウェビナーをご覧ください。
Hyperoptは、Pythonにおける機械学習モデルのチューニングのための最も人気のあるオープンソースライブラリです。Hyperopt 0.2.1がApache Sparkを通じて分散チューニングをサポートしたことを発表できることを嬉しく思っています。新たなSparkTrialsクラスを用いることで、Sparkクラスターでハイパーパラメーターチューニングをスケールさせることができます。SparkTrialsはJoseph Bradley、Hanyu Cui、Lu Wang、Weichen Xu、Liang Zhang (Databricks)とMax Pumperla (Konduit)の貢献によるものです。
Hyperoptとは?
Pythonで記述された、オープンソースのハイパーパラメーターチューニングのライブラリです。2019年10月時点で月当たり44万5千のPyPIダウンロード、Githubには3800以上のスターが付いており、急激な導入と強力なコミュニティサポートを示しています。データサイエンティストに対して、Hyperoptはハイパーパラメーター、モデルタイプに対する検索を行う一般的なAPIを提供します。Hyperoptは2つのチューニングアルゴリズムを提供します。ランダムサーチとベイジアンメソッドであるTree of Parzen Estimatorsです。
開発者に対して、Hyperoptはアルゴリズムと計算バックエンドに対するプラグイン可能なAPIを提供します。我々は、Apache Sparkによって支援される新たな計算バックエンドを開発するために、このプラグイン可能性を活用しました。
SparkによるHyperoptのスケールアウト
新たなSparkTrialsクラスを用いることで、チューニングのジョブをSparkクラスターに分散させるようにHyperoptに指示することができます。当社はDatabricksで開発されましたが、このハイパーパラメーターチューニングのAPIは複雑なチューニングをジョブを計算的に分散させるために多くのDatabricksのお客様によって推進され、オープンソースのHyperoptプロジェクトへの貢献となり、最新リリースで利用できるようになりました。
ハイパーパラメーターチューニングとモデル選択には、多くのケースで数百、数千のモデルが関わってきます。SparkTrialsはこれらのトレーニングタスクのバッチを並列で実行し、Sparkのエグゼキューターごとに一つのタスクを割り当てることで、チューニングを大幅にスケールアウトすることができます。HyperoptとSparkTrialsを活用するには、シンプルにHyperoptのfmin()関数にSparkTrialsオブジェクトを引き渡します。
from hyperopt import SparkTrials
best_hyperparameters = fmin(
fn = training_function,
space = search_space,
algo = hyperopt.tpe,
max_evals = 64,
trials = SparkTrials())
完全なサンプルコードは、Hyperopt documentation on SparkTrialsを確認してください。
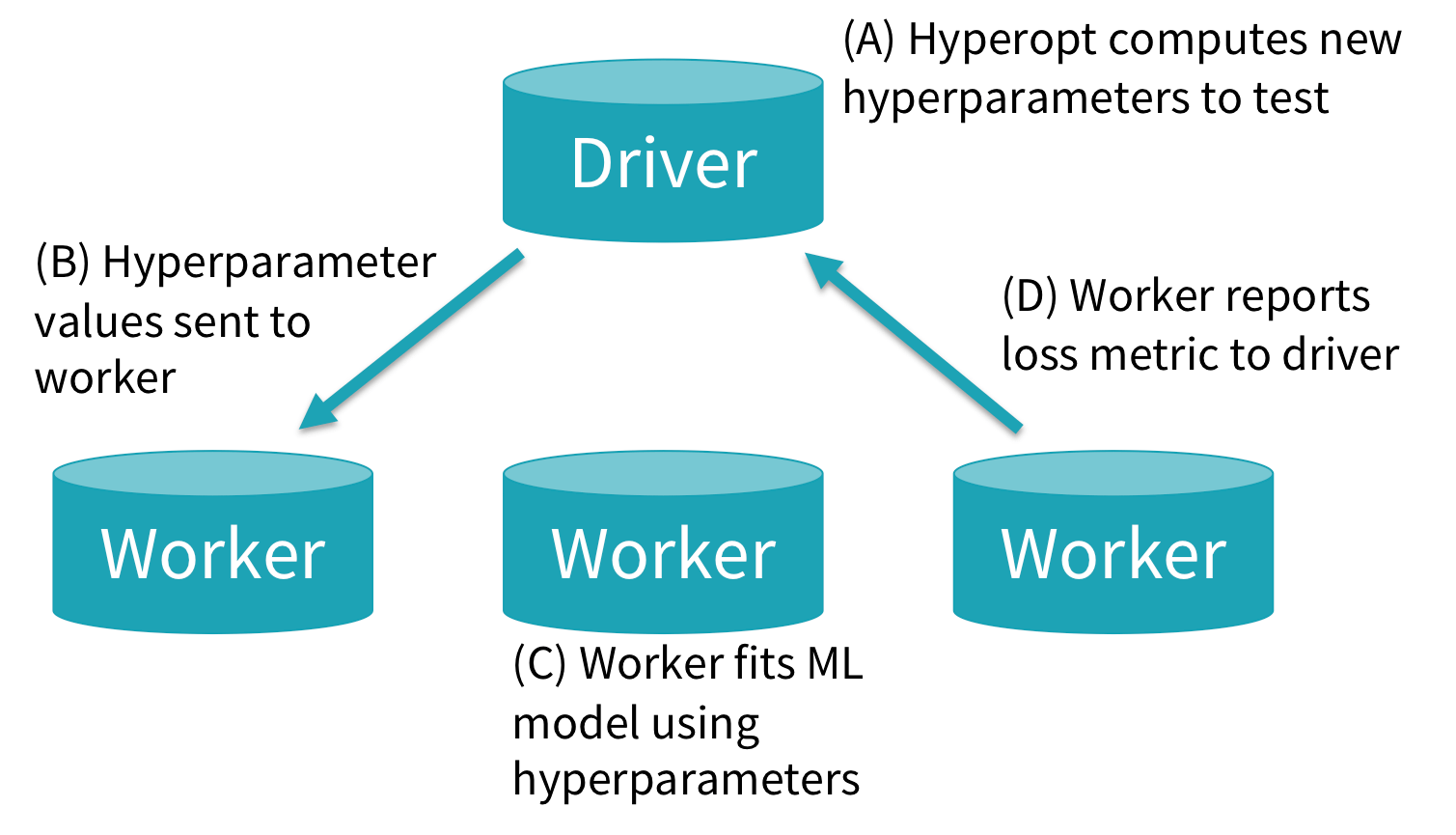
内部では、fmin()はテストすべき新規のハイパーパラメーターチューニングの設定を生成し、これらをSparkTrialsに引き渡します。以下の図では、どのようにSparkTrialsがこれらのタスクを、クラスター上で非同期に実行するのかを示しています。
(A) Hyperoptの主要なロジックはSparkドライバーで実行され、新規のハイパーパラメーター設定を計算します。
(B) ワーカーが新規タスクに対する準備ができたら、Hyperoptは当該ハイパーパラメーター設定に対するシングルタスクのSparkジョブをキックします。
(C) 単一のSparkエグゼキューターで実行されるタスク内では、新たなMLモデルをトレーニングし評価するために、ユーザーコードが実行されます。
(D) 処理が完了すると、Sparkタスクは損失を含む結果をドライバーに返却します。
これらの新たな結果は、将来的なタスクに対してより優れたハイパーパラメーター設定を計算するためにHyperoptで活用されます。
SparkTrialsは、一台のSparkワーカーで個々のモデルをフィッティングし評価するので、scikit-learnやシングルマシンのTensorflowのような、シングルマシンのMLモデルとワークフローに限定されます。Apache Spark MLlibやHorovodのような分散MLアルゴリズムに対しては、HyperoptのデフォルトのTrials classを活用することができます。
SparkTrials活用の実践
SparkTrialsにはキーとなる2つのパラメーターがあります。parallelism(実行する並列トライアルの最大数、デフォルトはSparkエグゼキューターの数となります)とtimeout(fminに許可される最大処理時間(秒)であり、デフォルトはNone)です。
parallelismパラメーターは、以下の図で説明されているガイドラインを用いて、fmin()に対するmax_evalsと組み合わせて設定することができます。Hyperoptはparallelismサイズのバッチでmax_evals回、ハイパーパラメーターに対する全体の設定をテストします。parallelism = max_evalsの場合、Hyperoptはランダムサーチを行います。テストするために全てのハイパーパラメーターの設定を独立で選択し、並列で評価します。parallelism = 1の場合、Hyperoptは繰り返しハイパーパラメーター空間を探索するTree of Parzen Estimatorsのような適合アルゴリズムを完全に活用します。テストされたそれぞれの新規のハイパーパラメーターの設定は、前回の結果に基づいて選択されます。parallelismを1とmax_evalsの間に設定することで、スケーラビリティ(迅速に結果を得る)と適合性(時に優れた結果を得る)のトレードオフを選択することができます。望ましい選択はsqrt(max_evals)のように中間を取るというものです。

チューニングのメリットを説明するために、最近のウェビナーで説明したPyTorchのワークフローを用いて、MNISTデータセットに対してSparkTrialsとHyperoptを実行します。我々のワークフローでは、手書き数字を予測するための基本的なディープラーニングモデルをトレーニングし、3つのパラメーター:バッチサイズ、学習率、モーメンタムをチューニングしました。これは、p2.xlargeのワーカーとDatabricksランタイム5.5MLを用いたAWSのDatabricksクラスターで実行されました。
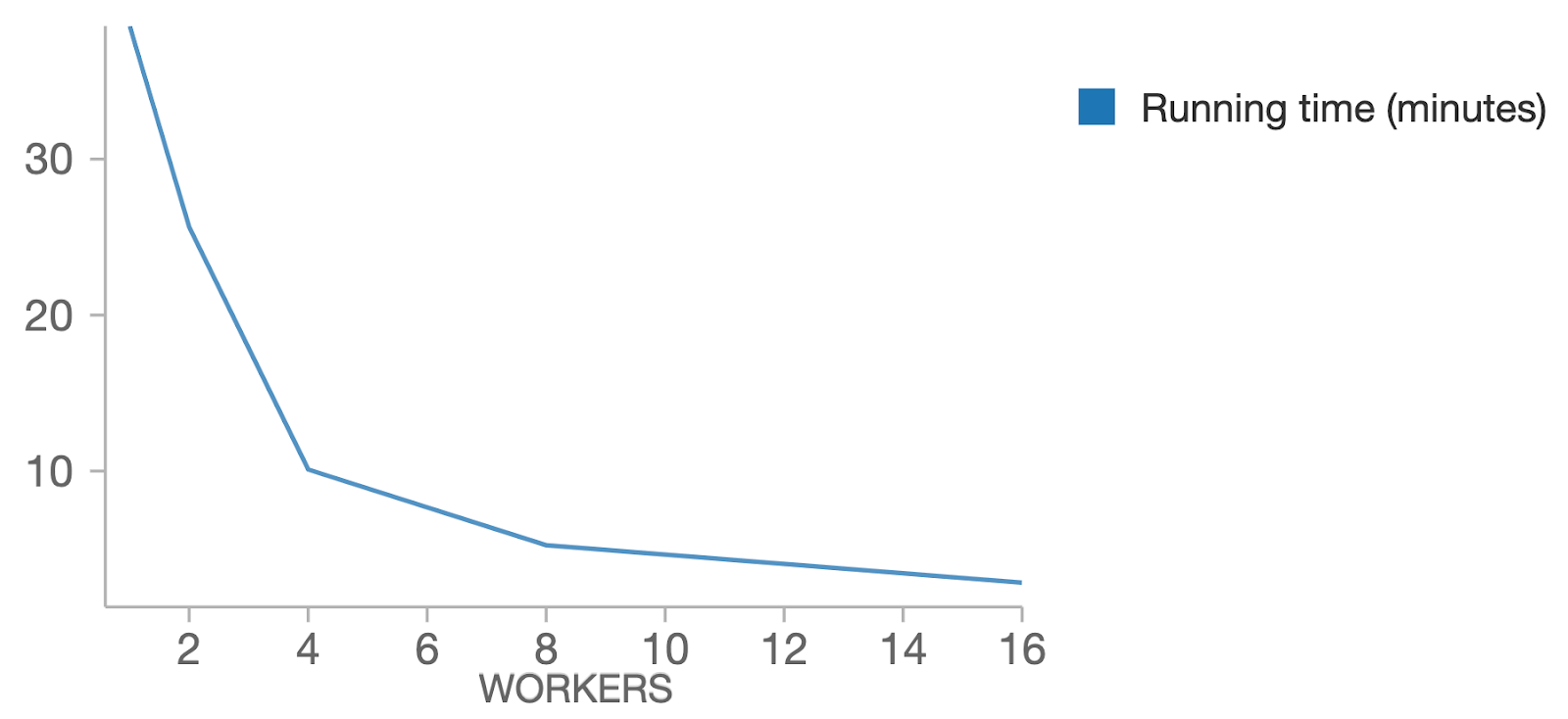
以下のプロットでは、max_evalsを128に固定し、ワーカーの数を変化させました。期待した通り、ワーカーを増やす(より大きいparallelism)ことで処理時間を削減できており、線形にスケールアウトできています。
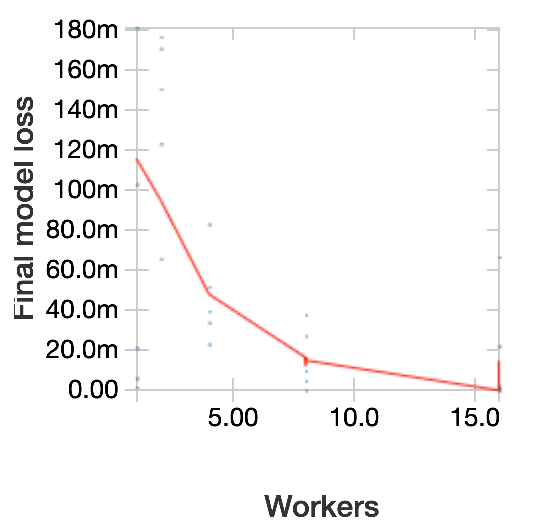
次に、timeoutを4分に固定してワーカーの数を変化させ、いくつかのトライアルでこの実験を繰り返しました。以下のプロットでは、損失(loss:負の対数尤度、"180m"="0.180")対ワーカー数を示しています。青い点は個々のトライアルであり、赤い線はトレンドを示しているLOESS曲線です。一般的に、parallelismを大きくすると、より多くのハイパーパラメーター設定をテストできるので、モデルのパフォーマンスは改善します。Hyperoptは検索に乱数化を用いるので、トライアルごとに挙動が変わることに注意してください。
Hyperopt 0.2.1を使ってみる
SparkTrialsはHyperopt 0.2.1(PyPi project pageから取得できます)で利用でき、HyperoptはDatabricks機械学習ランタイム (5.4以降)に含まれています。
Hyperoptに関してさらに学びたい、デモやサンプルを見たいのであれば、以下をチェックしてみてください。
- 完全なコードサンプルを含むプロジェクトの Github.io ページのドキュメント
- Databricksドキュメントにあるサンプルノートブック(AWS|Azure)
Hyperoptはエクスペリメントやモデルの追跡のためにMLflowと組み合わせることができます。このインテグレーションの詳細については、open-source MLflow exampleやハイパーパラメーターに関するブログ記事、ウェビナーをご覧ください。
Githubプロジェクトページを通じて貢献することが可能です。
- Github Issues pageでオープンソースの問題をレポートします。
- GithubのHyperoptに貢献します。
関連リソース
- hyperopt · PyPI
- Spark - Hyperopt Documentation
- マネージド MLflow
- Hyperparameter Tuning with MLflow, Apache Spark MLlib and Hyperopt - The Databricks Blog