How to Build a QoS Solution for OTT Services - The Databricks Blogの翻訳です。
ビデオストリーミングサービスにおける品質の重要性
従来の有料TVは活気を失い続けており、コンテンツ所有者は自身のコンテンツライブラリをマネタイズするために、ダイレクトツーコンシューマー(D2C)のサブスクリプションや、広告付きのストリーミングに軸足を置いています。すべてのビジネスモデルが素晴らしいコンテンツを制作し、ディストリビューターにライセンスする企業においては、完全なガラス張りの体験へのシフトは、顧客にコンテンツをデリバリーするためのメディアサプライチェーン、数多くのデバイスとオペレーティングシステムをサポートしたアプリ、請求やカスタマーサービスのようなカスタマーリレーションシップなど、新たな機能が必要となりました。
多くのvMVPD(バーチャル マルチチャンネル ビデオディストリビューター)と、SVOD(ストリーミング ビデオオンデマンド)サービスは月次ベースで更新され、サブスクリプションサービス事業者は彼らの購読者に対して、毎月、毎週、毎日価値を提供する必要があります(AVOD(広告ありビデオオンデマンド)の視聴者にとっては離脱の障壁はさらに低くなります。単純に他のアプリか、チャンネルを開けばいいのです)。一般的なビデオストリーミングの品質問題(バッファリング、レーテンシー、解像度の低下、ジッタリング、パケット損失、ブランクスクリーンなど)は、購読者の解約や、ビデオエンゲージメントの減少など、ビジネスに重大なインパクトを与えます。
ストリーミングを開始すると、オンプレミス、クラウドのサーバーのソース、CDNレベルあるいはISPレベル、さらには視聴者のホームネットワークの転送、あるいは、プレーヤーやクライアントなど、あまりに多くの場所で問題が起き、視聴者体験が損なわれ得ることを理解します。n x 104の同時ストリーミングにおける障害は、n x 105 や n x 106の障害と異なります。リアルワールドのユーザーを再現し、彼らがチェンネルをサーフィングし、アプリをクリックし、同時に異なるデバイスからサインインするなどして、最も冗長性のあるシステムで障害を起こせるようなリリース前のテスト手法は存在しません。TVの性質上、最も重要で人気のあるイベントは最大の視聴者を引き寄せ、事態は最悪なものになります。もしあなたがソーシャルメディアで不満を受け取り始めたら、それらが特定のユーザーに限定されるものなのか、特定の地域なのかあるいは国全体なのか判別できるでしょうか?もし、国レベルであれば、それはすべてのデバイスにおけるものなのか、固有のタイプのものなのか分かるでしょうか(例えば、OEMが古いデバイスのOSをアップデートして、クライアントとの互換性の問題を引き起こした)?
視聴者体験の品質問題の特定、対策、防御は、ユーザーの数、ユーザーによるアクションの数、そして、体験における引き渡し(サーバー→CDN→ISP→ホームネットワーク→クライアント)の数を考えるとビッグデータの問題となります。サービス品質(QoS)は、これらのデータストリームを意味あるものにするので、問題が何で、どこで、なぜ起きているのかを理解できるようになります。最終的には、何か問題が起きそうか、問題が起きる前にどのように対策が打てるのかの予兆分析に取り組むことになります。
DatabricksにおけるQoSソリューション概要
**このソリューションは、QoSシステムを改善したいと考える、あらゆるビデオストリーミングプラットフォームのコアを提供することを狙いとしています。**これは、AWSの研究所が提供するAWSストリーミングメディア分析ソリューションをベースとしています。我々は、リアルタイムの洞察と先進的な分析機能の両方のための統合データ分析基盤として、このソリューションをDatabricksの上に構築しました。
Databricksを用いることで、ストリーミングプラットフォームは堅牢かつ信頼性のあるデータパイプラインによって提供される完全かつ最新のデータセットを用いて迅速に洞察を得ることができ、エンドツーエンドの機械学習ライフサイクル管理をサポートするコラボレーティブな環境を用いて、データサイエンスを加速することで新機能の市場投入に要する時間を短縮し、データエンジニアリングとデータサイエンス両方を統合したプラットフォームを持つことで、ソフトウェア開発サイクル全体でのオペレーションコストを削減することができます。
ビデオQoSソリューションのアーキテクチャ
低レーテンシーのモニタリングアラートや、ピーク時のビデオトラフィックに対応するためのスケーラブルなインフラストラクチャのような複雑性に対して、アーキテクチャに対する分かりやすい選択肢はDeltaアーキテクチャでした。複数の種類のパイプライン(ストリーミングとバッチ)を維持することによる運用上の手間に関する欠点を持つLambdaやKappaアーキテクチャのような標準的なビッグデータアーキテクチャは、データエンジニアリングとデータサイエンス両方のアプローチへのサポートが欠如していました。
Deltaアーキテクチャは、組織のすべての種類のデータペルソナががより生産的になれるようにする次世代のパラダイムです。
- データエンジニアは、バッチとストリーミングを選択することなしに、継続的かつコスト効率が良いデータパイプラインを構築できます。
- データアナリストは、BIの問い合わせに対して迅速に答えとニアリアルタイムの洞察を得ることができます。
-
データサイエンティストは、再現性のあるエクスペリメントとレポートを円滑にするタイムトラベルのサポートによって、より信頼性のあるデータセットを用いて、より良い機械学習モデルを構築できます。
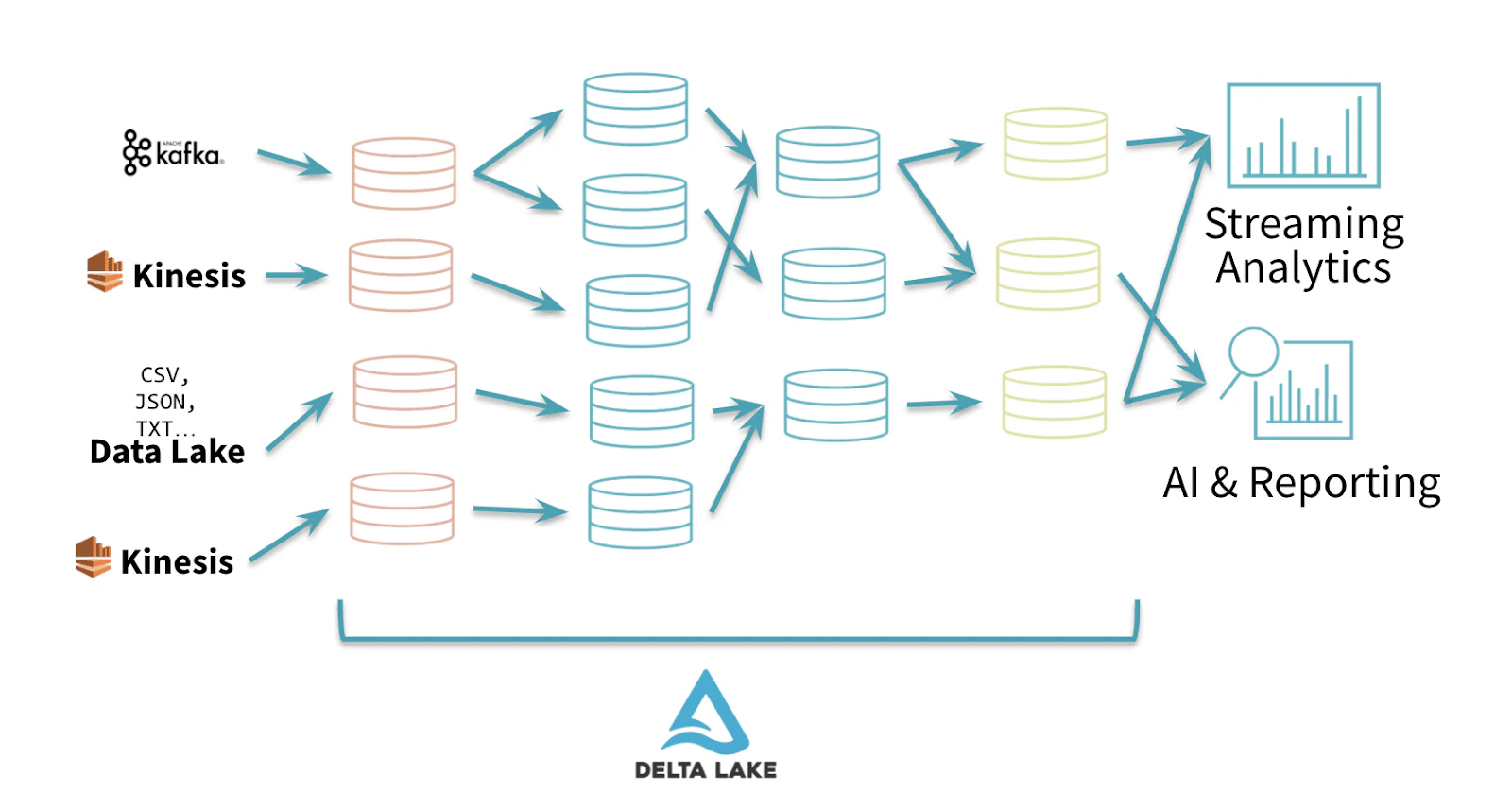
図1. データパイプラインに対する"マルチホップ"アプローチを用いるDeltaアーキテクチャ
Deltaアーキテクチャを用いたデータパイプラインの書き込みは、データに対して順次構造を追加していく複数のレイヤー「マルチホップ」を持つというベストプラクティスに従います。「ブロンズ」テーブル、あるいは取り込みテーブルは通常、ネイティブフォーマット(JSON、CSV、txt)の生データであり、「シルバー」テーブルは、レポーティングあるいはデータサイエンスに使用できるクレンジング後、変換後のデータセットであり、「ゴールド」は最終的なプレゼンテーションレイヤーとなります。
純粋なストリーミングのユースケースにおいては、データフレームを中間Deltaテーブルに永続化するかどうかは、基本的にレーテンシー/SLAとコストのトレードオフ(例:リアルタイムモニタリングのアラート vs 新たなコンテンツに基づくレコメンドシステムの更新)となります。
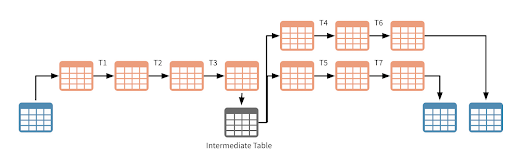
図2. データフレームをDeltaテーブルに永続化しつつも、ストリーミングアーキテクチャを実現することは可能です
このアプローチにおける「ホップ」の数は、視聴者のダウンストリームの数、集計の複雑度(例えば、構造化ストリーミングは複数の集計の連鎖に対して特定の制限を課します)、オペレーションの効率の最大化に直接影響を受けます。
このQoSソリューションアーキテクチャでは、データ処理のベストプラクティスにフォーカスしており、完全なVOD(ビデオオンデマンド)ソリューションではありません。データと分析にフォーカスするために、ハイレベルのアーキテクチャからは「フロントドア」サービスのAmazon API Gatewayのような幾つかの標準的なコンポーネントは除外されています。
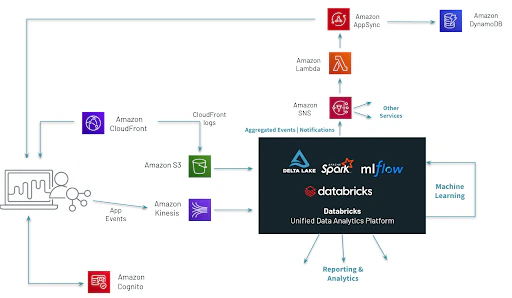
図3. QoSプラットフォームのハイレベルアーキテクチャ
データを分析可能な状態にする
QoSソリューションに含まれる両方のデータソース(アプリケーションのイベントログとCDNログ)はJSONフォーマットを使用しています。これは、複雑なネスト構造を表現でき、交換が容易ですが、スケーラブルではなく、データレイクや分析システムの格納フォーマットとして維持することは困難です。
企業全体で直接検索できるようにするために、ブロンズからシルバーへのパイプライン(「皆がデータを利用できるようにする」パイプラインです)は、あらゆる生のフォーマットをDelta形式に変換し、あらゆる規制に対応するためにデータのマスキングや品質チェックを行うべきです。
ビデオアプリケーションのイベント
このアーキテクチャにおいては、ビデオアプリケーションのイベントはKinesisストリームに直接プッシュされ、スキーマに変更を加えることなしに、Deltaの追加専用テーブルに取り込まれます。

図4. アプリケーションイベントの生データフォーマット
このパターンを用いることで、Kinesisストリームのスループットをスケールさせる必要なしに、大量の視聴者のダウンストリームで、データを処理することができます。Deltaテーブル(optimizeをサポートしています!)をシンクとして用いることの副次的な効果として、処理のウィンドウがターゲットテーブルのファイル数に影響すること、ビッグデータにおける「小さなファイル問題」を心配する必要はありません。
処理したいイベントの種別を選択できるようにし、パーティショニングできるようにするために、JSONのイベントファイルからタイムスタンプとメッセージの種別を抽出します。イベントに対する単一のKinesisストリームとDeltaの「Events」テーブルを再び組み合わせることで、ピーク時のスケーリングを容易にしつつも、オペレーション上の複雑性を低減することができます。
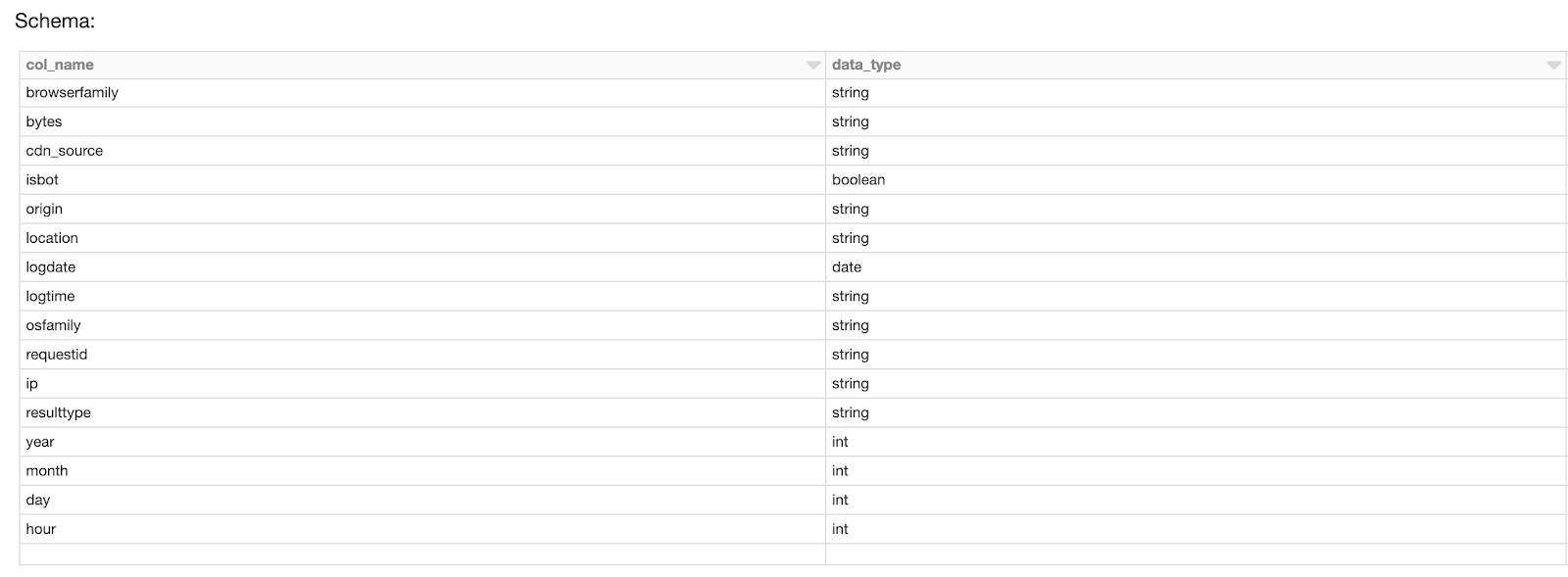
図5. シルバーテーブルを作成するためにJSONからすべての詳細情報が抽出されます
CDNログ
CDN(コンテンツデリバリーネットワーク)のログはS3にデリバリーされるので、これらを処理する最も簡単な方法は、追加の設定なしにS3に到着する新たなデータファイルをインクリメンタルかつ効率的に処理するオートローダーを使用することです。
auto_loader_df = spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "json") \
.option("cloudFiles.region", region) \
.load(input_location)
anonymized_df = auto_loader_df.select('*', ip_anonymizer('requestip').alias('ip'))\
.drop('requestip')\
.withColumn("origin", map_ip_to_location(col('ip')))
anonymized_df.writeStream \
.option('checkpointLocation', checkpoint_location)\
.format('delta') \
.table(silver_database + '.cdn_logs')
ログには、GDPR規制の元では個人情報とみなされるIPが含まれているので、「皆がデータを利用できるようにする」パイプライン」パイプラインでは、匿名化のステップを含める必要があります。別のテクニックを使うことが可能ですが、ここでは単にIPv4の最後のオクテット、IPv6の最後の80ビットを削除することにしました。さらに、このデータセットは、後ほどローカリゼーションのためにネットワークオペレーションセンターで使用する、アクセス元の国やISPプロバイダーなどの情報が拡張されています。
ダッシュボード / バーチャルなネットワークオペレーションセンターの構築
ストリーミング会社は、地理、デバイス、ネットワーク、現在、過去の視聴行動などの新たなセグメントを容易に定義し、セグメントレベルに抽象化する能力を用いて、個人レベルまでトラッキングすることで、可能な限りニアリアルタイムでネットワークのパフォーマンスとユーザー体験をモニタリングする必要があります。マクロレベルでユーザーのストリーミング体験の健康状態をモニタリングし、問題を早期に検知し、対応するために、ストリーミング会社は通信ネットワークからネットワークオペレーションセンター(NOC)の概念を導入しました。最も基本的なところでは、プロダクトチームが迅速かつ容易にサービスの異常を検知、対応できるようにするために、NOCはパフォーマンスのベースラインと現在のユーザーエクスペリエンスを比較できるダッシュボードを提供すべきです。
**このQoSソリューションでは、Databricksのダッシュボードを取り込みました。**より複雑な可視化を行うためにBIツールを簡単に接続することもできますが、お客様のフィードバックによれば、多くのケースでビルトインのダッシュボードが、ビジネスユーザーに対して洞察を表現する最も迅速な方法とのことでした。
NoCのために集計されたテーブルは、基本的にDeltaアーキテクチャのゴールドレイヤー、CDNログとアプリケーションイベントの組み合わせとなります。
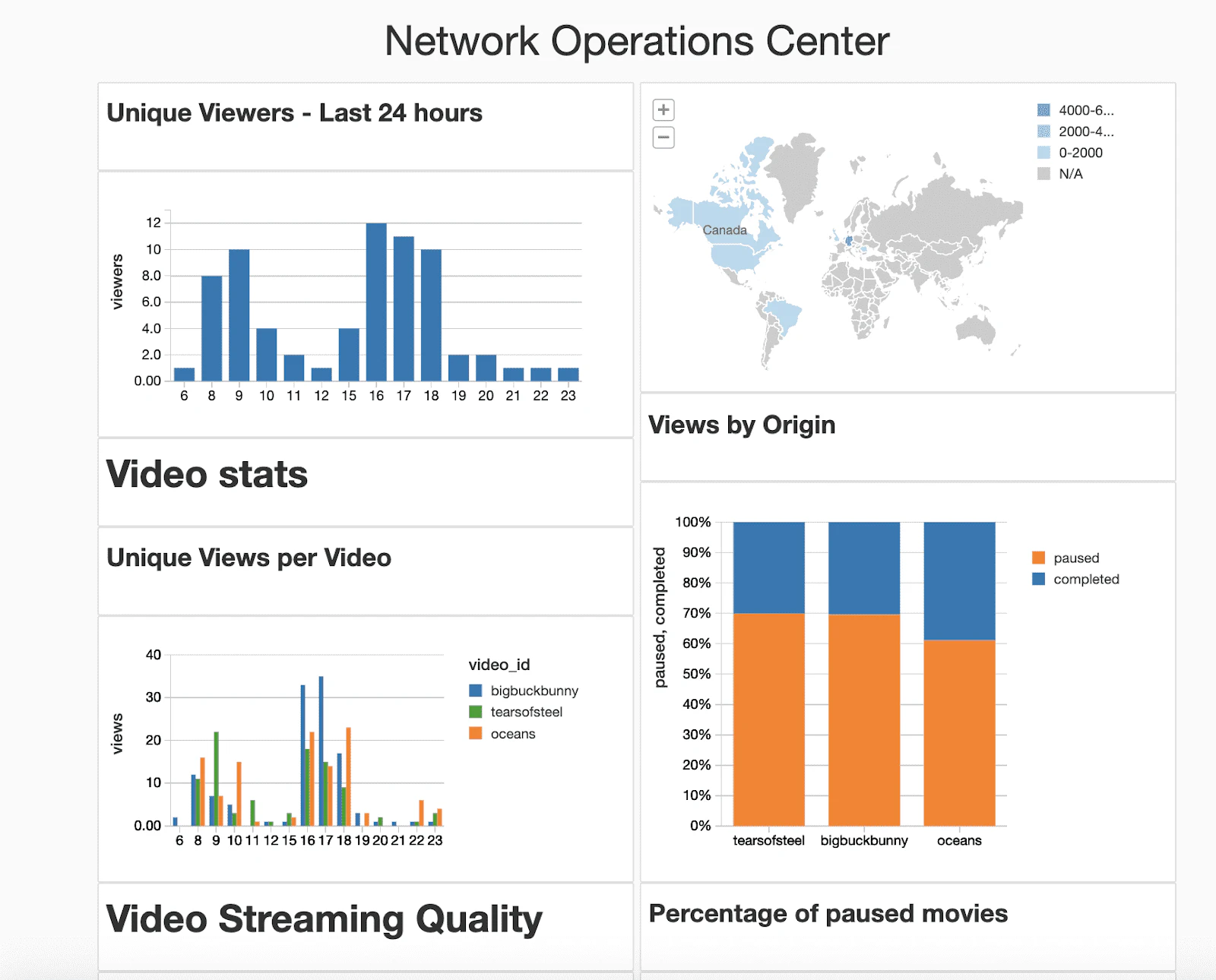
図6. ネットワークオペレーションセンターのダッシュボードの例
ダッシュボードはSQLあるいはPython/Rの変換処理の結果を可視化したものです。それぞれのノートブックは複数のダッシュボードをサポートしているので、複数のエンドユーザーが異なる要件を持っていても、コードを複製する必要はありません。加えて、Databricksのジョブによって、更新をスケジュールすることも可能です。
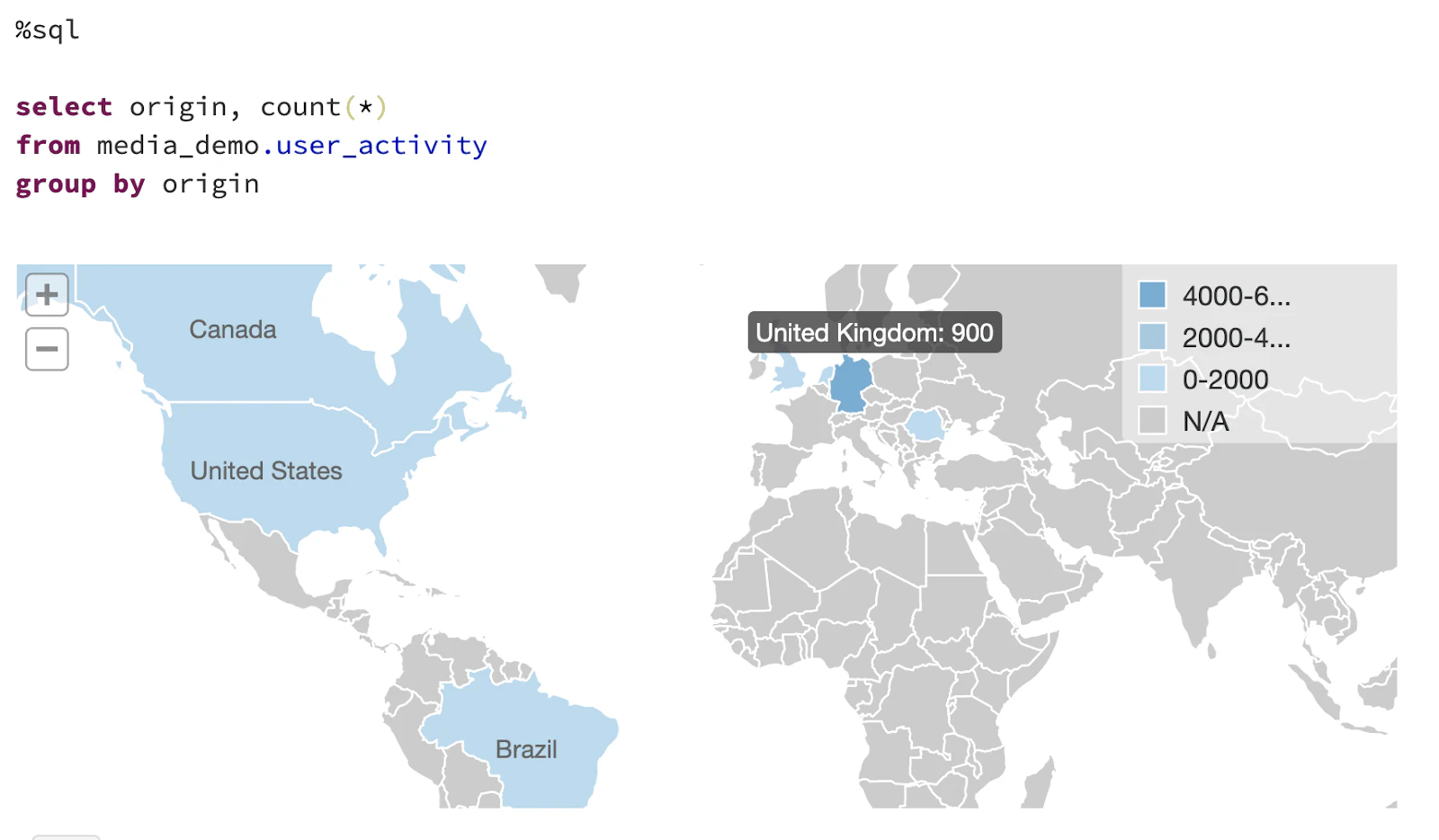
図7. SQLクエリー結果の可視化
ビデオのロード時間(最初のフレームまでの時間)は、お使いのCDN、この場合はAWSのCloudFrontエッジノードのそれぞれの場所におけるパフォーマンスの理解に役立ちます。これは、複数のCDNにユーザートラフィックを分散させるか、AWSのCloudFrontであればエッジ上のLambdaを用いて動的に接続元を選択する機能を実装するかと言った、KPIを改善するための戦略に直接インパクトを与えます。
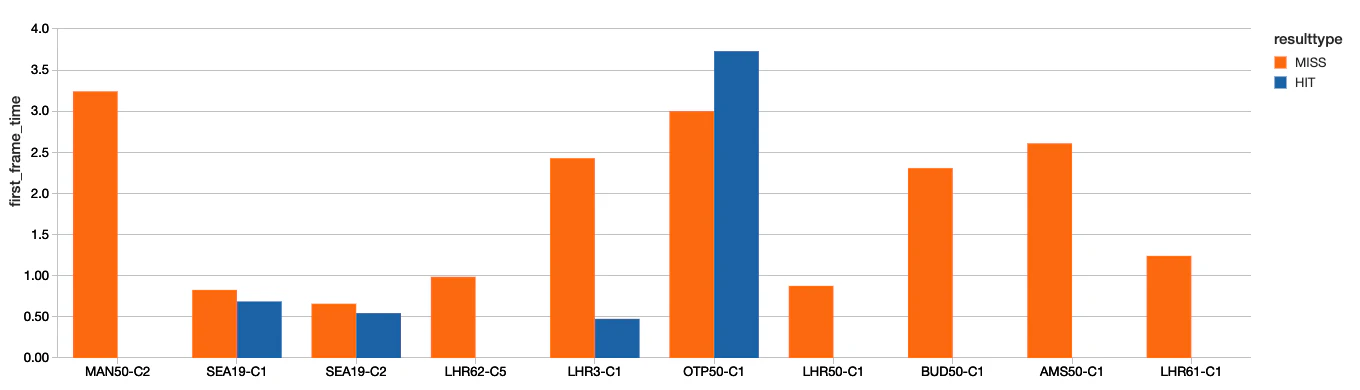
ハイレベルでのバッファリング、それによる貧弱なビデオ品質の体験を理解できずにいることは、購読者の解約率に重大な影響をもたらします。さらに、視聴者のエンゲージメントを減少させるような広告に対して、広告提供者はお金を支払いたいとは思わないでしょう。それらの広告はさらにバッファリングを追加することになるので、広告ビジネスにおける収益にもインパクトを与えることになります。この文脈においては、分析者がビデオの品質だけでなく、ブラウザーやアプリケーションのタイプ、バージョンに対する分析が行えるように、アプリケーション側から可能な限りの情報を集取することが重要です。
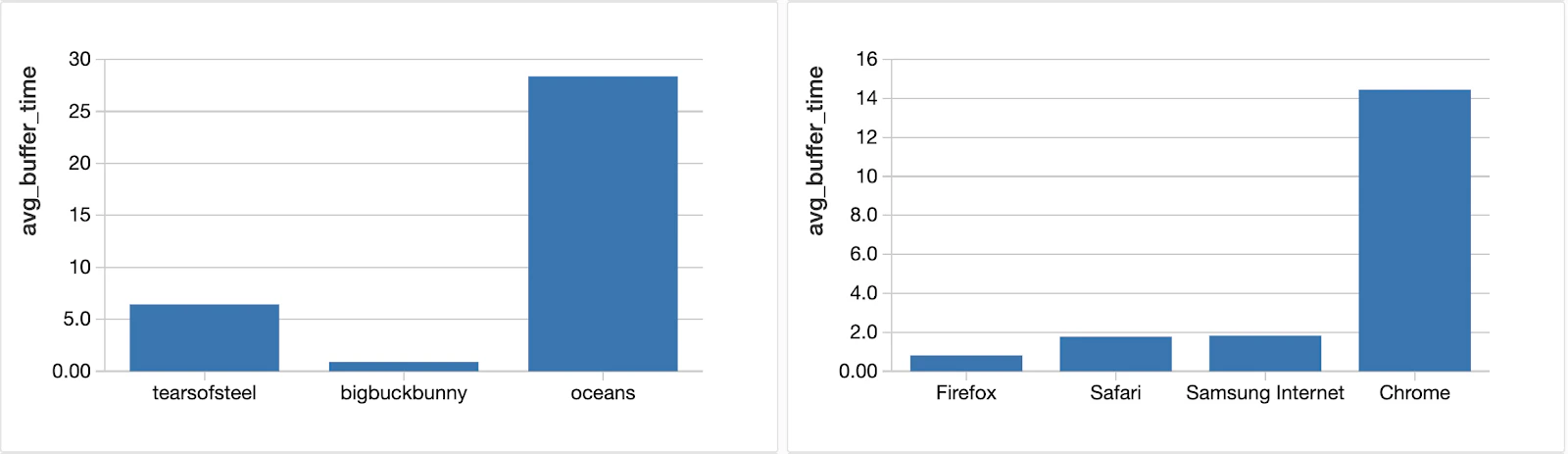
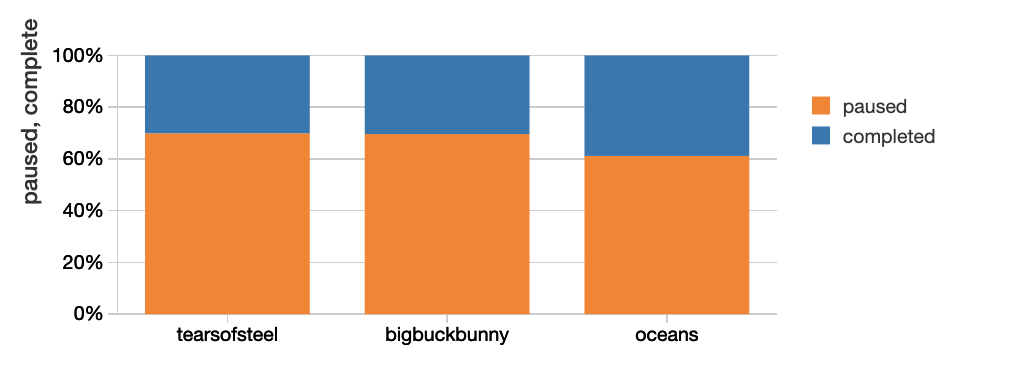
コンテンツ側では、アプリケーションのイベントが、ユーザーの振る舞いと全体的な体験の品質に関する有用な情報を提供します。ビデオを一時停止した人の何人が実際にそのビデオ、エピソードを最後まで観たのでしょうか?コンテンツの品質が視聴停止の理由でしょうか、あるいはデリバリーの問題でしょうか?もちろん、ユーザーのプロファイル構築だけでなく、解約予測を行うためにすべてのデータソース(ユーザーの行動、CDNやISPのパフォーマンス)を結合することで、さらなる分析が可能となります。
(ニア)リアルタイムアラートの作成
数百万人のユーザーに対するビデオストリーミングから生成されるデータの速度、ボリューム、多様性に対応する際、ダッシュボードの複雑性によって、NOCにおける人間のオペレータがある時点で最も重要なデータや、根本原因の問題に集中することが困難になります。このソリューションにおいては、容易に自動化されたアラートを設定できるので、パフォーマンスが特定の閾値を上回った場合に、ネットワークの人間のオペレータを支援したり、Lambda関数を用いて自動回復プロトコルを実行することもできます。以下のような例が考えられます。
- CDNがベースラインよりもはるかに大きいレーテンシー(例:ベースラインの平均よりも10%以上高いレーテンシー)を示している場合には、自動でCDN切り替え処理を実行。
- クライアントの一定数以上(例:5%)が再生エラーを報告した際には、プロダクトチームに対して特定デバイスのクライアントにおける問題の可能性を通知。
- 特定のISPの視聴者が平均のバッファリング、解像度低下の問題に直面した際には、フロントの顧客窓口に対応と問題軽減の方法(例:ストリーミング品質を低く設定)を通知。
技術的観点では、リアルタイムの通知を生成するためには、ストリーミングエンジンにおいてリアルタイムのデータ処理とプッシュ通知のためのパブリッシュ・サブスクライブサービスが必要となります。
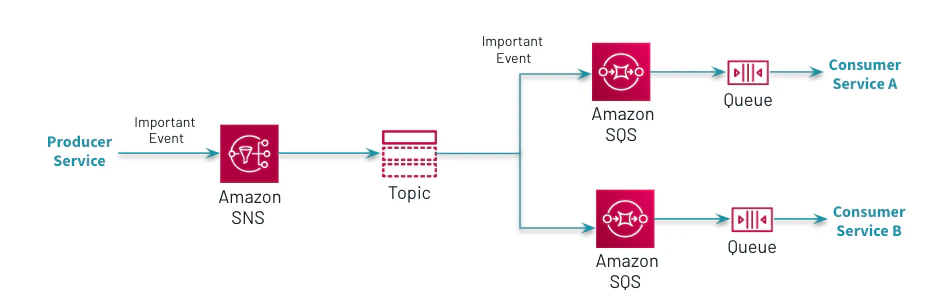
図8. Amazon SNSとAmazon SQSを用いたマイクロサービスの統合
このQoSソリューションは、Amazon SNSとAmazon Lambdaとの統合(以下のWebアプリケーションの更新の例を見てください)や他のコンシューマのためのAmazon SQSを用いたAWSにおけるマイクロサービス統合のベストプラクティスを実装しています。カスタムのforeachライターオプションによって、ルールベースエンジンに基づく(例:一定期間における個々のタイプのアプリのエラーのパーセンテージを検証)メールの通知を送るためのパイプラインへの書き込みを分かりやすいものにしています。
def send_error_notification(row):
sns_client = boto3.client('sns', region)
error_message = 'Number of errors for the App has exceeded the threshold {}'.format(row['percentage'])
response = sns_client.publish(
TopicArn=,
Message= error_message,
Subject=,
MessageStructure='string')
# Structured Streaming Job
getKinesisStream("player_events")\
.selectExpr("type", "app_type")\
.groupBy("app_type")\
.apply(calculate_error_percentage)\
.where("percentage > {}".format(threshold)) \
.writeStream\
.foreach(send_error_notification)\
.start()
図9. AWS SNSを用いたメール通知の送信
基本的なメールのユースケースに加えて、デモのプレーヤーには、AWS AppSyncを用いてリアルタイムで更新されるウィジェット(アクティブユーザーの数、最も人気のあるビデオ、ビデオを同時に参照しているユーザーの数)が含まれています。

図10. リアルタイム集計によるアプリケーションの更新
このQoSソリューションは、Amazon SQSを用いて追加のコンシューマがプラグインできるようにしてすべての値を更新するのに同様のアプローチ、構造化ストリーミングとAmazon SNSを適用しています。これは大量のイベントを拡張し、分析する際には一般的なパターンとなります。データを一度事前集計しておき、それぞれのサービス(コンシューマ)が自身の下流で意思決定を行えるようにします。
次のステップ: 機械学習
履歴データを人手で理解することは重要ですが非常に遅いものです。未来において、自動で意思決定をしたいと考えた場合には、機械学習アルゴリズムを導入する必要があります。
レイクハウスプラットフォームとして、DatabricksはHyperopt、Horvod、AutoMLをビルトインでサポートしているMLランタイムや、エンドツーエンドの機械学習ライフサイクル管理ツールであるMLflowとの統合などの機能によって、データサエンティストがより優れたデータサイエンスの成果物を生み出すことを支援します。
これまでのカスタマーベースにおいては、QoSソリューションへの拡張可能性にフォーカスしつつも、すでにいくつかの重要なユースケースを探索してきました。
障害ポイントの予測、対策
D2Cのストリーム提供者が多くのユーザーにリーチするほど、サービスの経済的損失に伴うコストは増加します。MLを活用することで、問題がどこで起きそうかを予測し、問題が悪化する前に対策を打つ(例:同時視聴者数のスパイクによって、自動的によりキャパシティのあるCDNに切り替える)ことで、オペレータはレポートから問題の防御に体制を移行することができます。
顧客解約
サブスクリプションサービスの成長に重要なことは、顧客を維持することです。個人レベルのサービス品質の理解によって、解約モデル、顧客障害価値モデルにQoSを追加することができます。さらに、プロアクティブなメッセージやギフトのオファーをテストするために、ビデオ品質問題に遭遇した顧客集団を生成することができます。
DatabricksのビデオストリーミングQoSソリューションを始めてみる
ビデオストリーミング体験において一貫性のある品質を提供することは、豊富なエンターテインメントの選択肢によって、移り気な視聴者をあなたのプラットフォームに引き止めるためには最低限必要なことです。多くのビデオストリーミングプラットフォーム環境に対するクイックスタートとして模索した、このQoSリアルタイムストリーミング分析ソリューションを組み込むことで以下のメリットがあります。
- 視聴者のあらゆるサイズにスケールします。
- 配信ワークフローのキーパーツにおける品質パフォーマンス問題を迅速に検知します。
- 新たな自動アラートを作成したり、データサイエンティストが予兆分析や機械学習をできるようにしたいなどの要件や、視聴者を容易にカスタマイズできいるように柔軟かつモジュール化されています。
**スタートするためには、Databricks streaming video QoS solutionのノートブックをダウンロードしてください。**どのようにして一つのシステムにバッチとストリーミングデータを統合するのかを学びたいのであれば、Deltaアーキテクチャに関するウェビナーをご覧ください。
参考資料
- Data Quality Monitoring on Streaming Data Using Spark Streaming and Delta Lake
- Databricks, AWS, and SafeGraph Team Up For Easier Analysis of Consumer Behavior
- Automate and Fast-track Data Lake and Cloud ETL with Databricks and StreamSets