こちらのイベントで話した内容です。
資料のPDFはこちら。
今回の内容に関係するガバナンスのウェビナーを11月17日に開催します。講師は私です。
会社紹介。

MLOpsとは
MLOpsとは機械学習モデルライフサイクル全般を円滑にするために必要な体制・基盤・手法全般を意味します。
MLOps(Machine Learning Operations)とは、データサイエンスチーム、運用チームなど、機械学習モデルの構築・運用に関わるチームが協調し、円滑に機械学習モデルを運用していくための体制・基盤を構築すること、その概念全般を意味します。
LLMOpsはこの考え方をLLMに拡張したものです。
LLMOps(Large Language Model Operations)とは、データサイエンスチーム、運用チームなど、LLMの構築・運用に関わるチームが協調し、円滑にLLMを運用していくための体制・基盤を構築すること、その概念全般を意味します。
MLOpsはLLMで何が変わるのでしょうか?
| LLMの特性 | MLOpsの示唆 |
|---|---|
様々な形態でLLMを利用可能:
|
開発プロセス:
|
LLMは入力として自然言語のプロンプトを受け入れ:
|
開発プロセス:
|
| LLMにはサンプルやコンテキストを伴うプロンプトを指定可能 |
サービングのインフラストラクチャ:
|
| サードパーティのAPIプロバイダー経由でプロプライエタリモデルやOSSモデルを利用可能 |
APIガバナンス:
|
| LLMは非常に大きなディープラーニングモデルであり、多くの場合、数Gバイトから数百Gバイトに |
サービングのインフラストラクチャ:
|
| LLMにおいては、多くの場合、単一の「適切な」回答が存在しないため、従来のMLメトリクスを通じた評価が困難 |
人間のフィードバック:
|
これらの新たな要件に適合するために、多くの既存ツール、既存プロセスの修正は軽微です
- 開発、ステージング、プロダクションの分離は変わりません
- パイプラインやモデルをプロダクションに移行する際に、Gitのバージョン管理とUnity CatalogにおけるMLflowモデルレジストリは依然として主要なパイプラインとなります。
- データ管理に対するレイクハウスアーキテクチャは、効率性のために依然として適切で重要です。
- 既存のCI/CDインフラストラクチャには変更はありません。
- モデルトレーニングのためのパイプライン、モデル推論のためのパイプラインなどを用いた、
- モジュール化されたMLOpsの構造は同じです。

Lakehouse AI
AIライフサイクルにおけるサイロ化の課題はLLMでも同様です。データセットの準備からモデルの開発、アプリケーションのデプロイメントでシステムがサイロ化していると効率は上がらず、エラーが混入します。
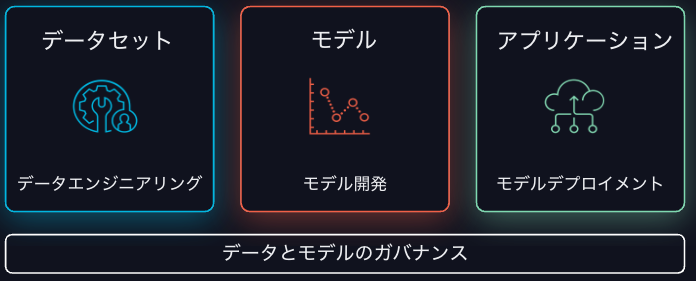
- モデル開発に必要なクリーンで信頼できるデータの取得が困難
- インテグレーション欠如による開発の遅延
- 完全なAIライフサイクルを制御、管理、追跡できないことによるリスクの増加
これらの課題を解決するために、我々はデータ中心アプローチのLakehouse AIを提供します。
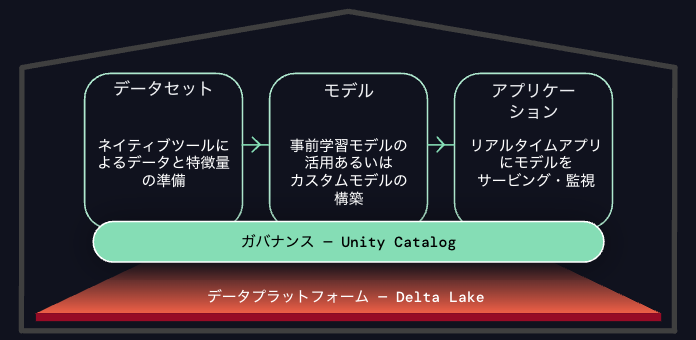
- データプラットフォーム(レイクハウス)上に構築
- 高速なデプロイメント
- ビルトインのガバナンスとモニタリング
Lakehouse AIのコンポーネント
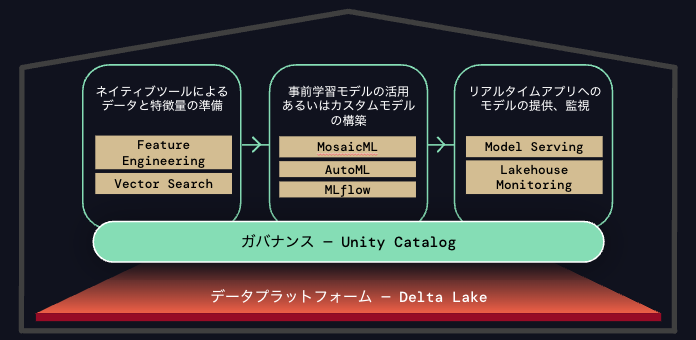
Unity Catalogにおける特徴量エンジニアリング
- 特徴量の効率的かつ高信頼な作成、管理、提供
- Unity Catalogのテーブルをトレーニングやサービングにおけるソースとして活用可能
- レイクハウスのDeltaテーブルに基づいて継続的に更新
- モデルサービングや外部エンドポイントを使用しているアプリにオンデマンドのサービング
ベクトル検索(Vector Search)
- Unity Catalogのデータから自動更新されるベクトル検索インデックスの作成
- ビルトインのガバナンス、権限管理、リネージ
- フルマネージド、サーバレス、すぐに利用可能
- エンベディング生成においてMLflowやモデルサービングとインテグレーション
MosaicML
- 大規模AIモデルのトレーニングを最大7倍高速、安価に
- 簡素化され、スケーラブルでコスト効率の高い大規模AIモデルのトレーニング
- ご自身のセキュアな環境で自分のデータを用いて、自分の生成AIモデルをトレーニングあるいはファインチューニング
- モデルとデータプライバシーに対する完全なコントロール
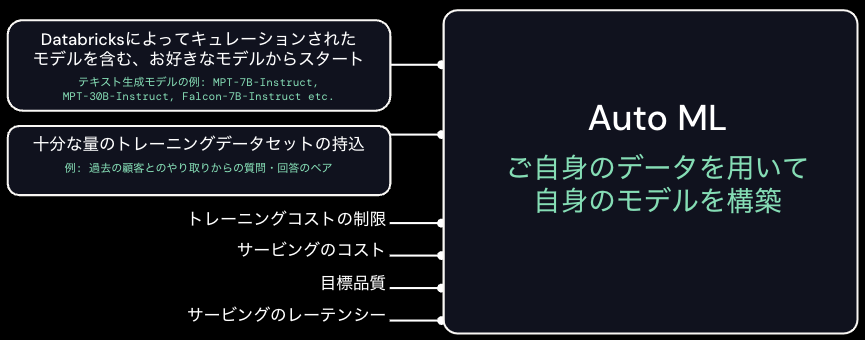
AutoML
- エンベディングのファインチューニングやモデル作成のためのローコードツール
MLflow
- エンドツーエンドのMLOpsとLLMOps
- 月間1,100万ダウンロードのMLOpsのスタンダード
- モデルの実験、追跡、評価、管理
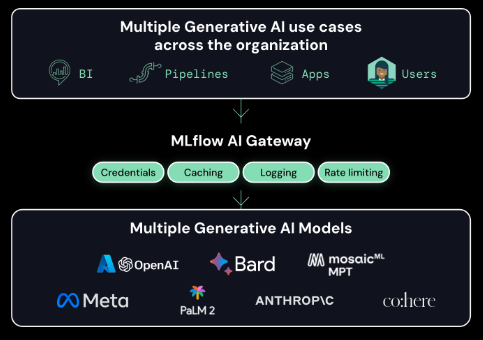
- 権限管理やガバナンスを自動化するためのAI GatewayのようなLLMOpsの新機能
モデルサービング
- 最大10倍のレーテンシー削減、コスト削減を提供するモデルのリアルタイム推論
- 高可用性、低レーテンシー、ゼロまで自動スケールするサービング
- デプロイメントを自動化し、エラーを削減するための、自動特徴量検索、監視、統合ガバナンス
- 最大10倍のレーテンシー、コスト削減を実現するオープンソース生成AIモデルに最適化
レイクハウスモニタリング
- インテリジェントなデータとモデルのモニタリング
- 数分でデータとモデルに対する完全な可視性を提供し、市場投入に要する時間とコストを削減
- データとモデルの異常をプロアクティブかつシンプルに検知
- 異常の根本原因を追跡することでシームレスにデバッグ