Visualization deep dive in Python | Databricks on AWS [2020/3/4時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
このノートブックでは、Databricksに組み込まれている様々なチャートとグラフをカバーします。
このノートブックにおけるビジュアライゼーションで表示されるテストデータの生成にPythonを使用していますが、これらのチャートやグラフの設定方法は全てのノートブックに対して適用されます。
ノートブックはこちらからダウンロードできます。
テーブルビュー
テーブルビューはデータを参照する最も基本的な方法です。テーブルビューでは最初の1000行のみが表示されます。
from pyspark.sql import Row
array = map(lambda x: Row(key="k_%04d" % x, value = x), range(1, 5001))
largeDataFrame = spark.createDataFrame(sc.parallelize(array))
largeDataFrame.registerTempTable("largeTable")
display(spark.sql("select * from largeTable"))

Plot Optionsによる設定
- ほとんどのグラフタイプにおけるX軸として通常表示される制御変数をKeysセクションに指定します。ほとんどのグラフでは、キーに対して約1000の値をプロットできます。繰り返しになりますが、これはグラフによって異なります。
- 通常Y軸に表示される観測変数をValuesセクションに指定します。多くのグラフタイプにおいては観測される数値になる傾向があります。
- データを分割する方法をSeries groupingsで指定します。棒グラフにおいては、それぞれの系列グルーピングには異なる色と、それぞれの系列グルーピングを示す凡例が与えられます。多くのグラフタイプでは、10以下のユニークな値を持つ系列グルーピングのみを取り扱うことができます。
いくつかのグラフタイプではより多くのオプションを指定することができ、適用できる際にはこれらも議論します。
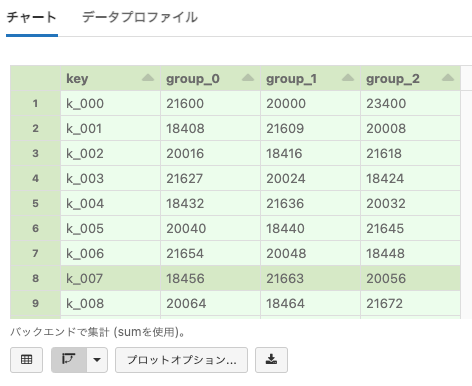
ピボットテーブル
Pivot tableはテーブル形式でデータを参照するもう一つの方法です。
テーブルで生の結果を表示するのではなく、テーブルに格納されているデータのソート、合計や平均を自動で計算します。
- ピボットテーブルの詳細に関しては右を参照ください: http://en.wikipedia.org/wiki/Pivot_table
- ピボットテーブルに対しては、キー、系列グルーピング、値のフィールドを指定することができます。
- Keyは最初のカラムとなり、ピボットテーブルではキーあたり1行が存在します。
- Series Groupingに対して、個々のユニークな値のカラムを追加することができます。
- テーブルのセルにはValuesフィールドが含まれます。値は集計関数を用いて結合できるように数値である必要があります。
- ピボットテーブルのセルには、オリジナルのテーブルの複数行から計算された値が入ります。
- オリジナルの行を結合するための方法としてSUM、AVG、MIN、MAX、COUNTを選択します。
- セルの値を計算するために、Databricksのクラウドのサーバーサイドでピボット処理が行われます。
ピボットテーブルを作成するには、下のグラフアイコンをクリックしてPivotを選択します。
# Plot Optionsボタンをクリックして、どのようにピボットテーブルが設定されるのかを見てみましょう。
from pyspark.sql import Row
largePivotSeries = map(lambda x: Row(key="k_%03d" % (x % 200), series_grouping = "group_%d" % (x % 3), value = x), range(1, 5001))
largePivotDataFrame = spark.createDataFrame(sc.parallelize(largePivotSeries))
largePivotDataFrame.registerTempTable("table_to_be_pivoted")
display(spark.sql("select * from table_to_be_pivoted"))
ピボットテーブルの別の考え方として、キーと系列グルーピングでオリジナルのテーブルをグルーピングし、(キー、系列グルーピング、集計関数)タプルを出力するのではなく、スキーマがキーと、系列グルーピングそれぞれのユニークな値であるテーブルを出力するというものがあります。
- 上のピボットテーブルの全てのデータを含みますが結果のスキーマが異なる、以下のgroup_by文の結果をご覧ください。
%sql select key, series_grouping, sum(value) from table_to_be_pivoted group by key, series_grouping order by key, series_grouping

棒グラフ
Bar Chartはピボットテーブルのビジュアルなグラフであり、データを可視化する基本的な方法となります。
- 以下のグラフを設定するために Plot Options... を使用します。
- KeyはX軸に表示されるYearとなります。
- Series groupingsはProductであり、それぞれに対して異なる色が割り当てられます。
- ValuesはY軸に表示されるsalesAmountとなります。
- 集計方法としてSumが選択され、ピボットのために行が加算されます。
from pyspark.sql import Row
salesEntryDataFrame = spark.createDataFrame(sc.parallelize([
Row(category="fruits_and_vegetables", product="apples", year=2012, salesAmount=100.50),
Row(category="fruits_and_vegetables", product="oranges", year=2012, salesAmount=100.75),
Row(category="fruits_and_vegetables", product="apples", year=2013, salesAmount=200.25),
Row(category="fruits_and_vegetables", product="oranges", year=2013, salesAmount=300.65),
Row(category="fruits_and_vegetables", product="apples", year=2014, salesAmount=300.65),
Row(category="fruits_and_vegetables", product="oranges", year=2015, salesAmount=100.35),
Row(category="butcher_shop", product="beef", year=2012, salesAmount=200.50),
Row(category="butcher_shop", product="chicken", year=2012, salesAmount=200.75),
Row(category="butcher_shop", product="pork", year=2013, salesAmount=400.25),
Row(category="butcher_shop", product="beef", year=2013, salesAmount=600.65),
Row(category="butcher_shop", product="beef", year=2014, salesAmount=600.65),
Row(category="butcher_shop", product="chicken", year=2015, salesAmount=200.35),
Row(category="misc", product="gum", year=2012, salesAmount=400.50),
Row(category="misc", product="cleaning_supplies", year=2012, salesAmount=400.75),
Row(category="misc", product="greeting_cards", year=2013, salesAmount=800.25),
Row(category="misc", product="kitchen_utensils", year=2013, salesAmount=1200.65),
Row(category="misc", product="cleaning_supplies", year=2014, salesAmount=1200.65),
Row(category="misc", product="cleaning_supplies", year=2015, salesAmount=400.35)
]))
salesEntryDataFrame.registerTempTable("test_sales_table")
display(spark.sql("select * from test_sales_table"))

小技: チャートのそれぞれのバーの上にマウスカーソルを移動すると正確な値を確認することができます。
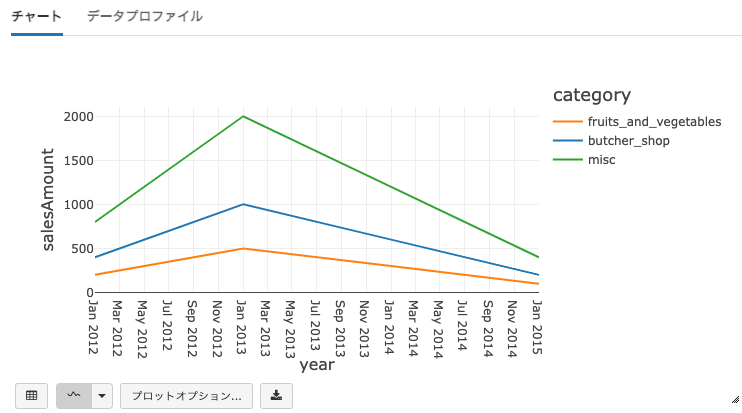
折れ線グラフ
Line Graphはデータセットのトレンドをハイライトする別のピボットテーブルグラフのサンプルとなります。
- 以下のグラフを設定するために Plot Options... を使用します。
- KeyはX軸に表示されるYearとなります。
- Series groupingsはCategoryであり、それぞれに対して異なる色が割り当てられます。
- ValuesはY軸に表示されるsalesAmountとなります。
- 集計方法としてSumを選択します。
%sql select cast(string(year) as date) as year, category, salesAmount from test_sales_table
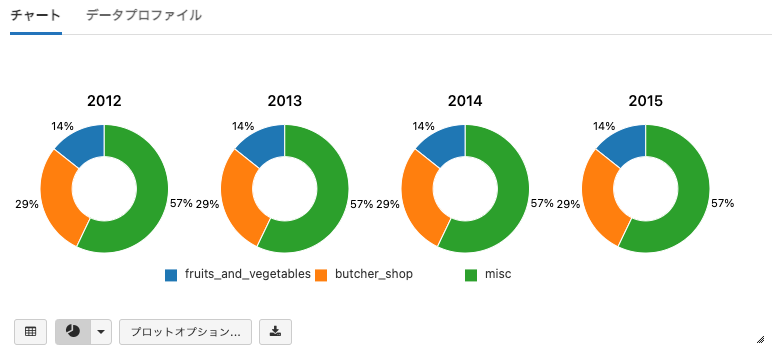
円グラフ
Pie Chartは、データセットの値のパーセンテージを参照できるピボットテーブルのグラフタイプとなります。
- 注意: 上のサンプルとは異なり、キーと系列グルーピングがスイッチされます。
- 以下のグラフを設定するために Plot Options... を使用します。
- KeyはX軸に表示されるYearとなります。
- Series groupingsはCategoryであり、それぞれに対して異なる色が割り当てられます。
- ValuesはY軸に表示されるsalesAmountとなります。
- 集計方法としてSumを選択します。
%sql select * from test_sales_table
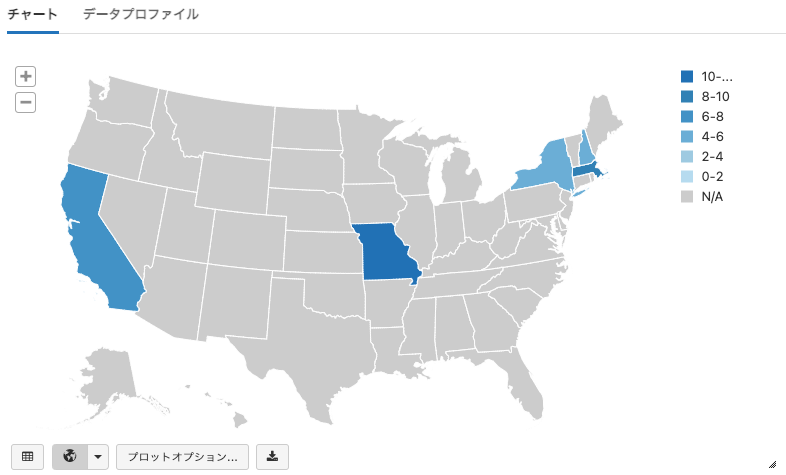
地図グラフ
Map Graphは地図上にデータを可視化することができます。
- 以下のグラフを設定するために Plot Options... を使用します。
- Keysには位置を示すフィールドを含める必要があります。
- Series groupingsはWorld Mapグラフでは常に無視されます。
- Valuesには、数値を持つ1つのフィールドを含める必要があります。
- 同じ位置のキーを持つ複数行が存在するので、一つのキーに対して値を組み合わせるために"Sum", "Avg", "Min", "Max", "COUNT"を選択します。
- 異なる値に対して地図上の異なる色が割り当てられ、レンジは常に均等な間隔となります。
ティップ: 値が均等に分布していない場合、グラフに対してスムーシング関数を適用してください。
from pyspark.sql import Row
stateRDD = spark.createDataFrame(sc.parallelize([
Row(state="MO", value=1), Row(state="MO", value=10),
Row(state="NH", value=4),
Row(state="MA", value=8),
Row(state="NY", value=4),
Row(state="CA", value=7)
]))
stateRDD.registerTempTable("test_state_table")
display(spark.sql("Select * from test_state_table"))
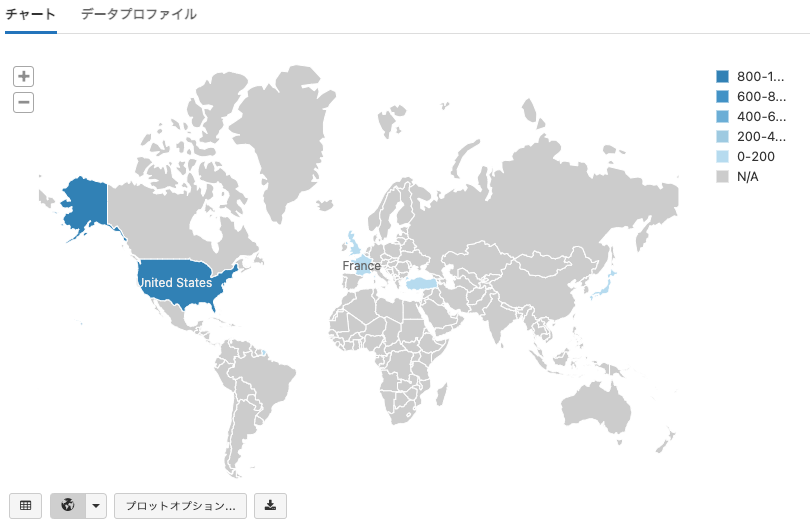
世界地図にグラフをプロットするには、キーとしてcountry codes in ISO 3166-1 alpha-3 formatを使用します。
from pyspark.sql import Row
worldRDD = spark.createDataFrame(sc.parallelize([
Row(country="USA", value=1000),
Row(country="JPN", value=23),
Row(country="GBR", value=23),
Row(country="FRA", value=21),
Row(country="TUR", value=3)
]))
display(worldRDD)
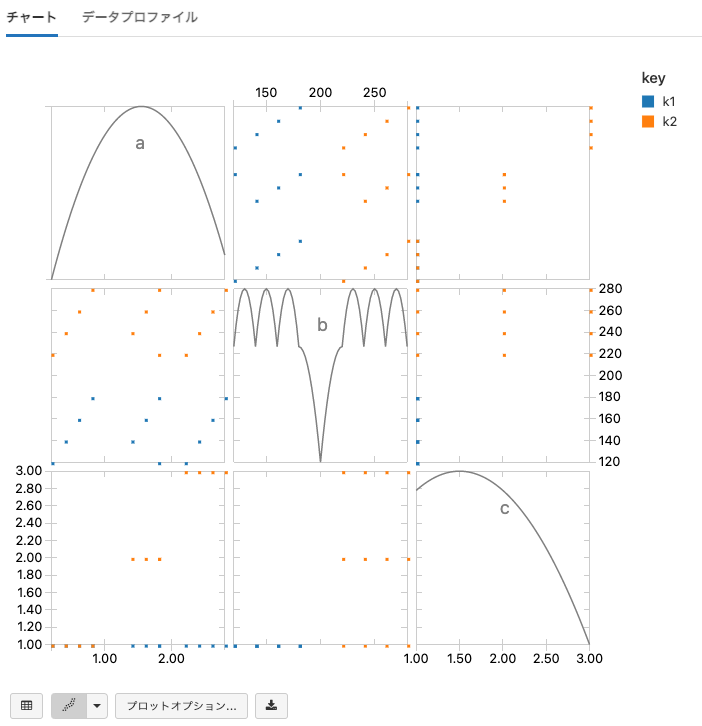
散布図
Scatter Plotを用いることで、二つの変数に相関があるかどうかを確認することができます。
- 以下のグラフを設定するために Plot Options... を使用します。
- Keysはグラフのポイントの色と凡例に使用されます。
- Series groupingsは無視されます。
- Valuesには、最低2つのフィールドを含める必要があります。グラフは値としてa、b、cを持っています。
- 結果のプロットの対角線は変数のカーネル密度となります。
- 行には常にY軸の変数を持ち、カラムはX軸の変数を持ちます。
from pyspark.sql import Row
scatterPlotRDD = spark.createDataFrame(sc.parallelize([
Row(key="k1", a=0.2, b=120, c=1), Row(key="k1", a=0.4, b=140, c=1), Row(key="k1", a=0.6, b=160, c=1), Row(key="k1", a=0.8, b=180, c=1),
Row(key="k2", a=0.2, b=220, c=1), Row(key="k2", a=0.4, b=240, c=1), Row(key="k2", a=0.6, b=260, c=1), Row(key="k2", a=0.8, b=280, c=1),
Row(key="k1", a=1.8, b=120, c=1), Row(key="k1", a=1.4, b=140, c=1), Row(key="k1", a=1.6, b=160, c=1), Row(key="k1", a=1.8, b=180, c=1),
Row(key="k2", a=1.8, b=220, c=2), Row(key="k2", a=1.4, b=240, c=2), Row(key="k2", a=1.6, b=260, c=2), Row(key="k2", a=1.8, b=280, c=2),
Row(key="k1", a=2.2, b=120, c=1), Row(key="k1", a=2.4, b=140, c=1), Row(key="k1", a=2.6, b=160, c=1), Row(key="k1", a=2.8, b=180, c=1),
Row(key="k2", a=2.2, b=220, c=3), Row(key="k2", a=2.4, b=240, c=3), Row(key="k2", a=2.6, b=260, c=3), Row(key="k2", a=2.8, b=280, c=3)
]))
display(scatterPlotRDD)
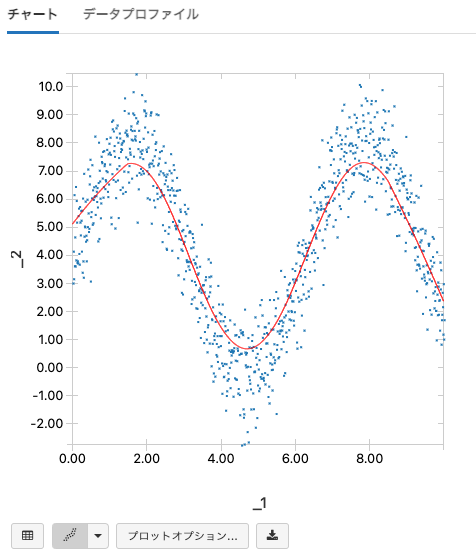
散布図のLOESSフィット曲線
LOESSは、お使いの散布図におけるデータのトレンドを説明するスムース推定曲線を生成するために、データに対する局所的な回帰を実行する方法です。データポイントの近傍点で曲線を内挿することで、これを実現します。LOESSフィット曲線は、プロットをスムースにするために使用する近隣のポイントの数を指定する帯域パラメーターで制御されます。高い帯域パラメーター(1に近い値)は非常にスムースな曲線を提供しますが、一般的なトレンドを捉えられない場合があります。一方、低い帯域パラメーター(0に近い値)はあまりプロットをスムースにしません。
LOESSフィット曲線は、散布図で利用できます。ここでは、お使いのサンプル図に対するLOESSフィットをどのように作成するのかを示します。
注意: データセットに5000ポイント以上ある場合、LOESSフィットは最初の5000ポイントを用いて計算されます。
import numpy as np
import math
# 散布図のデータポイントを作成します
np.random.seed(0)
points = sc.parallelize(range(0,1000)).map(lambda x: (x/100.0, 4 * math.sin(x/100.0) + np.random.normal(4,1))).toDF()
テーブル表示の左下にあるコントロールを用いてこのデータを散布図にします。

Plot Optionsを選択した際にLOESSフィットオプションにアクセスすることができます。

ノイジーなデータに対して曲線がどのように適用されるのかを見るために、帯域パラメーターを変えて実験することができます。
変更を受け入れると、散布図に対するLOESSフィットを確認することができます!
display(points)
ヒストグラム
Histogramを用いることで値の分布を確認することができます。
- 以下のグラフを設定するために Plot Options... を使用します。
- Valuesには1つのフィールドを含める必要があります。
- Series groupingsは常に無視されます。
-
Keysでは2フィールドまで指定することができます。
- キーが指定されない場合、1つのヒストグラムが出力されます。
- 2つのフィールドが指定された場合、ヒストグラムが格子状に表示されます。
- Aggregationは適用できません。
- Number of binsはヒストグラムプロットでのみ表示される特殊なオプションであり、ヒストグラムのビンの数を制御します。
- ビンはヒストグラムに対してサーバーサイドで計算されるので、テーブルの全ての行がプロットされます。
from pyspark.sql import Row
# プロットされた値の正確な値をヒストグラムから読み取るためにはエントリーにマウスカーソルを移動します
histogramRDD = spark.createDataFrame(sc.parallelize([
Row(key1="a", key2="x", val=0.2), Row(key1="a", key2="x", val=0.4), Row(key1="a", key2="x", val=0.6), Row(key1="a", key2="x", val=0.8), Row(key1="a", key2="x", val=1.0),
Row(key1="b", key2="z", val=0.2), Row(key1="b", key2="x", val=0.4), Row(key1="b", key2="x", val=0.6), Row(key1="b", key2="y", val=0.8), Row(key1="b", key2="x", val=1.0),
Row(key1="a", key2="x", val=0.2), Row(key1="a", key2="y", val=0.4), Row(key1="a", key2="x", val=0.6), Row(key1="a", key2="x", val=0.8), Row(key1="a", key2="x", val=1.0),
Row(key1="b", key2="x", val=0.2), Row(key1="b", key2="x", val=0.4), Row(key1="b", key2="x", val=0.6), Row(key1="b", key2="z", val=0.8), Row(key1="b", key2="x", val=1.0)]))
display(histogramRDD)

Quantileプロット
Quantile plotを用いることで、指定された分位数に対する値が何かを確認することができます。
- Quantile Plotの詳細については、 http://en.wikipedia.org/wiki/Normal_probability_plot を参照ください。
- 以下のグラフを設定するために Plot Options... を使用します。
- Valuesには1つのフィールドを含める必要があります。
- Series groupingsは常に無視されます。
-
Keysでは2フィールドまで指定することができます。
- キーが指定されない場合、1つのヒストグラムが出力されます。
- 2つのフィールドが指定された場合、Quantileプロットが格子状に表示されます。
- Aggregationは適用できません。
- Quantileは現状サーバーサイドでは計算されませんので、プロットには1000行のみが反映されます。
from pyspark.sql import Row
quantileSeries = map(lambda x: Row(key="key_%01d" % (x % 4), grouping="group_%01d" % (x % 3), otherField=x, value=x*x), range(1, 5001))
quantileSeriesRDD = spark.createDataFrame(sc.parallelize(quantileSeries))
display(quantileSeriesRDD)
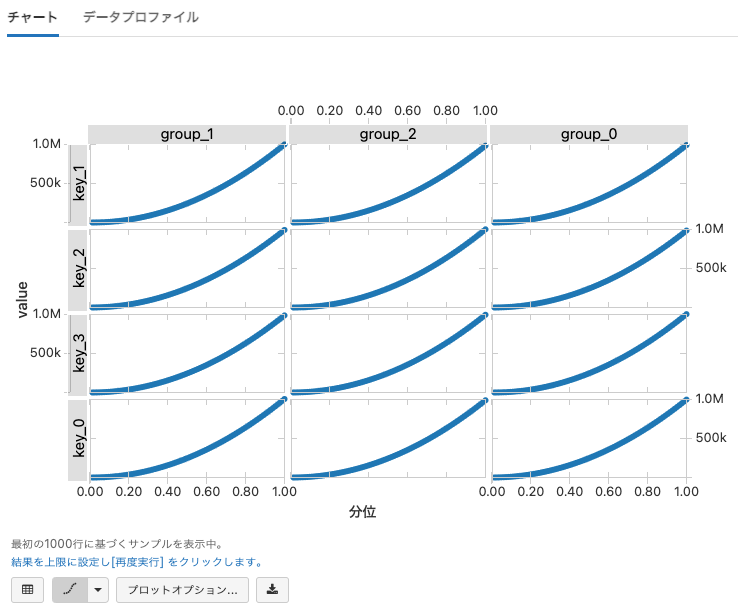
Q-Qプロット
Q-Qプロットは、フィールドの値の分布を表示します。
- Q-Qプロットの詳細については、 http://en.wikipedia.org/wiki/Q%E2%80%93Q_plot を参照ください。
- Valueは1つあるいは2つのフィールドを含める必要があります。
- Series Groupingは常に無視されます。
-
Keysでは2フィールドまで指定することができます。
- キーが指定されない場合、1つのヒストグラムが出力されます。
- 2つのフィールドが指定された場合、Quantileプロットが格子状に表示されます。
- Aggregationは適用できません。
- Q-Qプロットは現状サーバーサイドでは計算されませんので、プロットには1000行のみが反映されます。
from pyspark.sql import Row
qqPlotSeries = map(lambda x: Row(key="key_%03d" % (x % 5), grouping="group_%01d" % (x % 3), value=x, value_squared=x*x), range(1, 5001))
qqPlotRDD = spark.createDataFrame(sc.parallelize(qqPlotSeries))
Valuesに対して1つのフィールドのみが指定された場合、Q-Qプロットは単に正規分布とフィールドの分布を比較します。
display(qqPlotRDD)

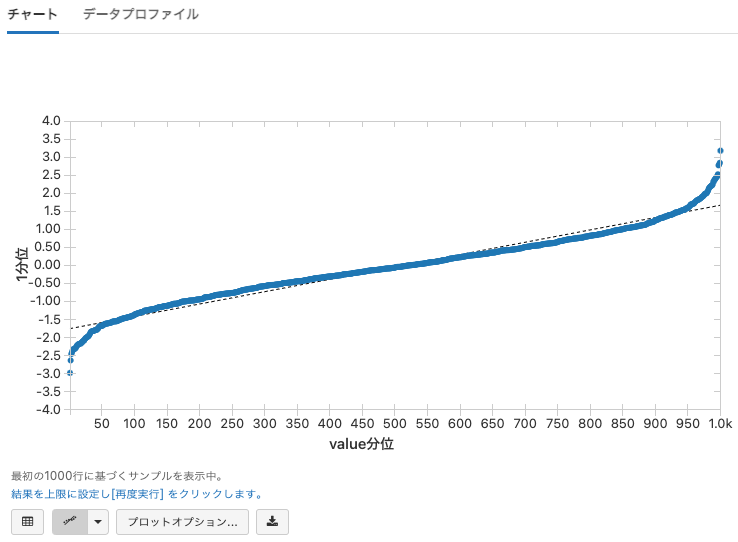
Valuesに2つのフィールドを指定すると、2つのフィールドの分布を比較します。
display(qqPlotRDD)


Q-Qプロットで格子プロットを作成するには、最大2つのキーを設定します。
display(qqPlotRDD)


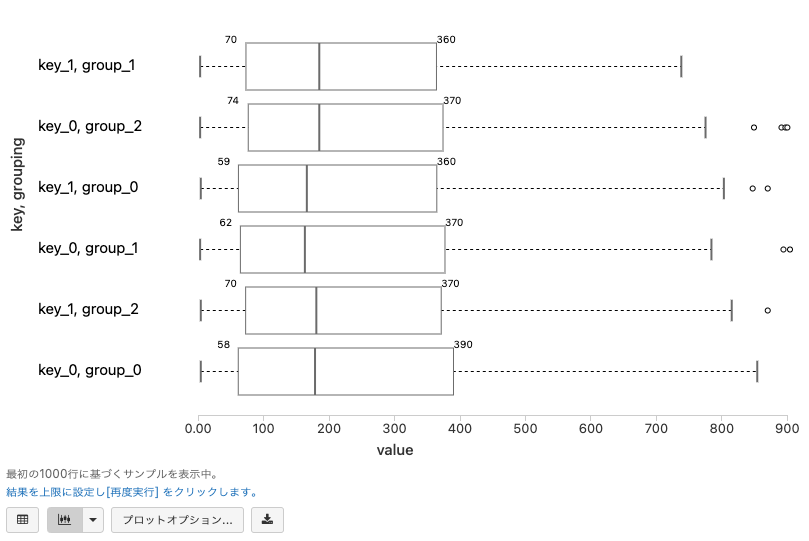
ボックスプロット
Box plotは期待される値のレンジが何であるのか、外れ値があるのかに対するアイデアを与えてくれます。
- ボックスプロットに関しては http://en.wikipedia.org/wiki/Box_plot をご覧ください。
- Valueには1つのフィールドを含める必要があります。
- Series Groupingは常に無視されます。
-
Keysを追加することができます。
- キーのそれぞれの値に対して一つのボックス・ウィスカープロットが作成されます。
- Aggregationは適用できません。
- ボックスプロットは現状サーバーサイドでは計算されませんので、プロットには1000行のみが反映されます。
- ボックスの上にマウスカーソルを移動すると、ボックスプロットの中央値が表示されます。
from pyspark.sql import Row
import random
# ボックスの上にマウスカーソルを移動すると、ボックスプロットの中央値が表示されます。
boxSeries = map(lambda x: Row(key="key_%01d" % (x % 2), grouping="group_%01d" % (x % 3), value=random.randint(0, x)), range(1, 5001))
boxSeriesRDD = spark.createDataFrame(sc.parallelize(boxSeries))
display(boxSeriesRDD)