ある意味、こちらの続きです。
しかし、宇宙船タイタニックとは。SF好きにはたまらない。宇宙船のどの乗客が別次元に転送されてしまったのかを予測する問題。
こちらからサンプルノートブックを取得します。
データはこちらから。
データは前回同様にボリュームにアップロードします。パスは/Volumes/takaakiyayoi_catalog/default/dataです。
%sh
ls /Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic.zip
/Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic.zip
解凍します。
%sh
unzip /Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic.zip -d /Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic/
Archive: /Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic.zip
inflating: /Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic/sample_submission.csv
inflating: /Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic/test.csv
inflating: /Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic/train.csv
tensorflow_decision_forestsが無いとエラーになったのでインストールします。
Python
%pip install tensorflow_decision_forests
dbutils.library.restartPython()
データセットをロードする際にはボリューム上のパスを指定します。
Python
# Load a dataset into a Pandas Dataframe
dataset_df = pd.read_csv('/Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic/train.csv')
print("Full train dataset shape is {}".format(dataset_df.shape))
Full train dataset shape is (8693, 14)
この後でデータの統計情報やデータ型の確認をするのですが、dbutils.data.summarizeを使うと簡単にプロファイリングできます。
Python
dbutils.data.summarize(dataset_df)
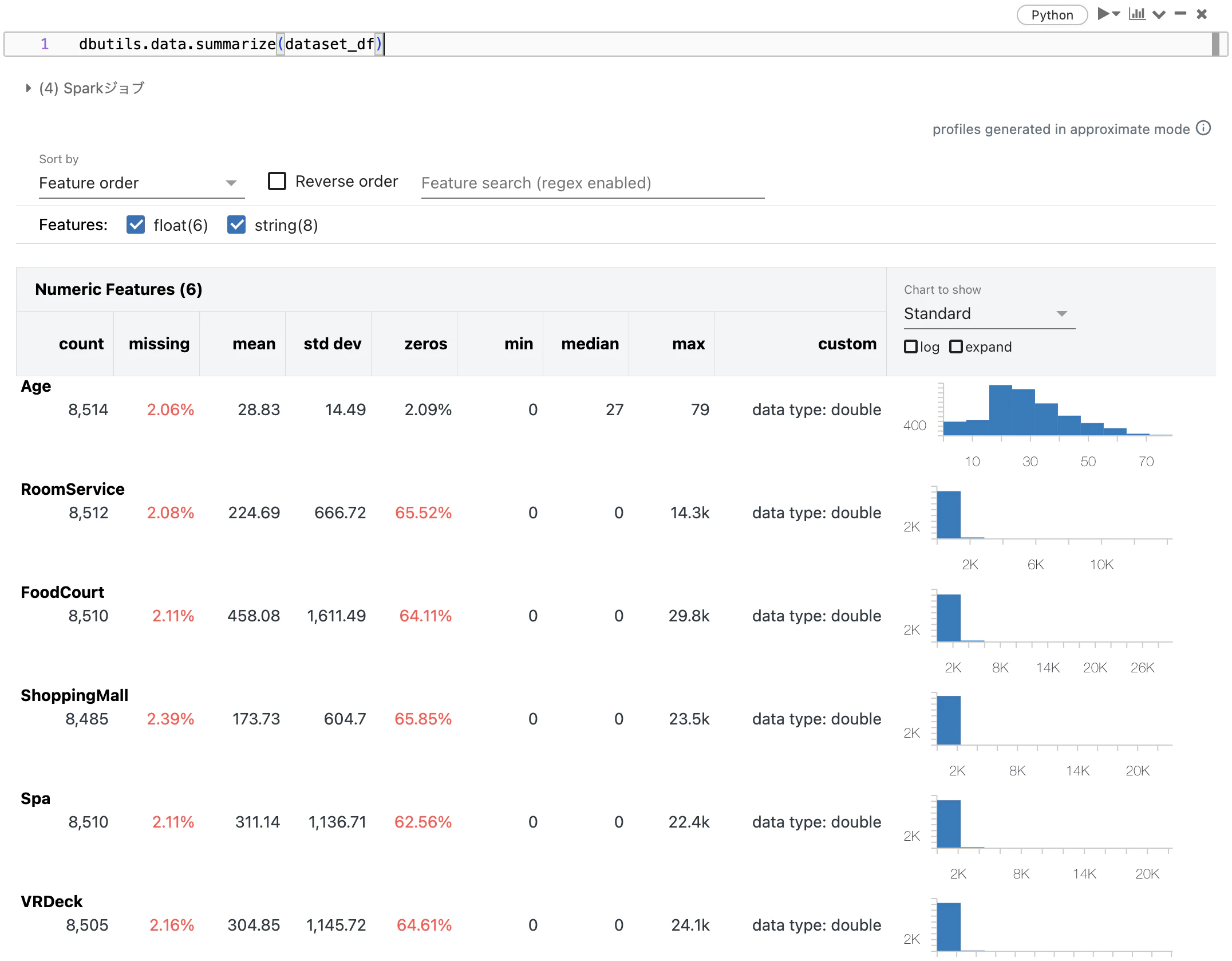
その他のクレンジングなどを行った後にフィッティングを行います。
Python
rf = tfdf.keras.RandomForestModel()
rf.compile(metrics=["accuracy"]) # Optional, you can use this to include a list of eval metrics
Python
rf.fit(x=train_ds)
Reading training dataset...
Training dataset read in 0:00:05.167006. Found 6925 examples.
Training model...
Model trained in 0:00:56.797938
Compiling model...
Model compiled.
<keras.src.callbacks.History at 0x7f6aa9def760>
モデルを可視化します。これは便利ですね。
Python
tfdf.model_plotter.plot_model_in_colab(rf, tree_idx=0, max_depth=3)

この他、精度検証などを行い、テストデータセットに対する予測を行います。
Python
# Load the test dataset
test_df = pd.read_csv('/Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic/test.csv')
submission_id = test_df.PassengerId
# Replace NaN values with zero
test_df[['VIP', 'CryoSleep']] = test_df[['VIP', 'CryoSleep']].fillna(value=0)
# Creating New Features - Deck, Cabin_num and Side from the column Cabin and remove Cabin
test_df[["Deck", "Cabin_num", "Side"]] = test_df["Cabin"].str.split("/", expand=True)
test_df = test_df.drop('Cabin', axis=1)
# Convert boolean to 1's and 0's
test_df['VIP'] = test_df['VIP'].astype(int)
test_df['CryoSleep'] = test_df['CryoSleep'].astype(int)
# Convert pd dataframe to tf dataset
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df)
# Get the predictions for testdata
predictions = rf.predict(test_ds)
n_predictions = (predictions > 0.5).astype(bool)
output = pd.DataFrame({'PassengerId': submission_id,
'Transported': n_predictions.squeeze()})
output.head()
提出用データセットを出力します。
Python
sample_submission_df = pd.read_csv('/Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic/sample_submission.csv')
sample_submission_df['Transported'] = n_predictions
sample_submission_df.to_csv('/Volumes/takaakiyayoi_catalog/default/data/spaceship-titanic/submission.csv', index=False)
sample_submission_df.head()
最終的にはボリュームに以下のようにファイルが格納されることになります。

submission.csvをKaggleに提出します。

提出しました!

時間できたらもう少し頑張ってみます。