こちらの続編です。
追加の要件
- 取り込む対象のディレクトリには過去のデータが格納されている。
- DLTパイプラインを初回実行する際には、過去のデータは取り込みたくない。
- 以降のDLTパイプライン実行では、初回パイプライン実行後に追加されたファイルのみを用いて、洗い替えを行いたい。
DLTパイプラインの設定
DLTパイプラインを初回に実行する際、既存のファイルを処理するかどうかを指定するオプションがあります。
cloudFiles.includeExistingFiles:
ストリーム処理入力パスに既存のファイルを含めるか、初期セットアップ後に到着する新しいファイルのみを処理するかどうか。このオプションは、初めてストリームを開始するときにのみ評価されます。ストリームの再開後にこのオプションを変更しても効果はありません。
こちらの設定をパイプラインを実装するノートブックで追加します。
CREATE
OR REFRESH STREAMING TABLE complete_bronze_w_filter TBLPROPERTIES (
'delta.minReaderVersion' = '2',
'delta.minWriterVersion' = '5',
'delta.columnMapping.mode' = 'name',
'pipelines.reset.allowed' = 'false'
) COMMENT "Parquetをそのまま保持するブロンズテーブル" AS
SELECT
*,
current_timestamp() as processed -- 処理時刻
FROM
cloud_files(
"/tmp/takaaki.yayoi@databricks.com/dlt/landing/",
"parquet",
map("cloudFiles.includeExistingFiles", "false") -- 初回実行時に既存ファイルを無視
)
今回はシンプルにするため、シルバーテーブルは作成せずにブロンズテーブルのみとします。
DLTパイプラインの作成
上述のノートブックを指定してDLTパイプラインを作成します。前回同様、ターゲットはUCのtakaakiyayoi_catalog.dltにします。
削除用クエリーの作成
こちらも前回同様です。
DELETE FROM takaakiyayoi_catalog.dlt.complete_bronze_w_filter;
テーブル確認用クエリーの作成
こちらは新たなコンポーネントです。これは、初回のジョブ実行時にはレコードを削除するテーブルが存在せず、その際にDELETE FROMを実行するとエラーになるのを避けるためです。
SELECT * FROM takaakiyayoi_catalog.dlt.complete_bronze_w_filter LIMIT 1;
ジョブの作成
上述のコンポーネントをタスクとして組み合わせます。
タスク: check_table
- 種類: SQL
- SQLタスク: クエリー
- SQLクエリー: check_table
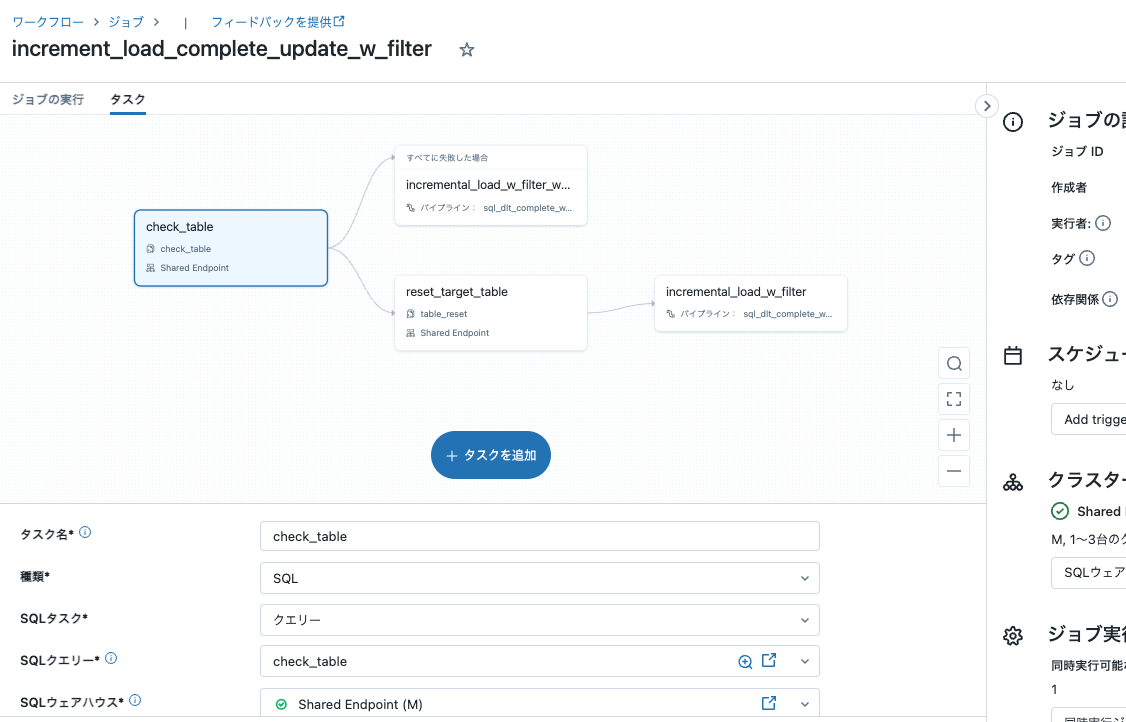
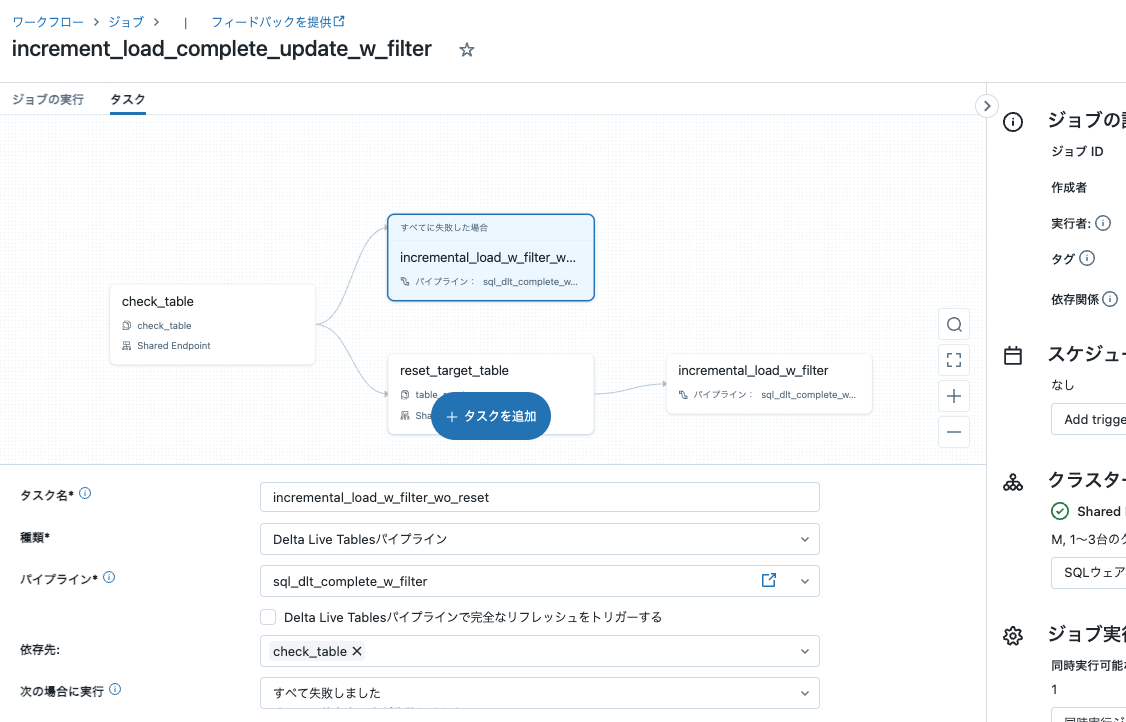
タスク: incremental_load_w_filter_wo_reset
- 種類: Delta Live Tablesパイプライン
- パイプライン: sql_dlt_complete_w_filter
- Delta Live Tablesパイプラインで完全なリフレッシュをトリガーする: チェックしない
- 依存先: check_table
- 次の場合に実行: すべて失敗しました
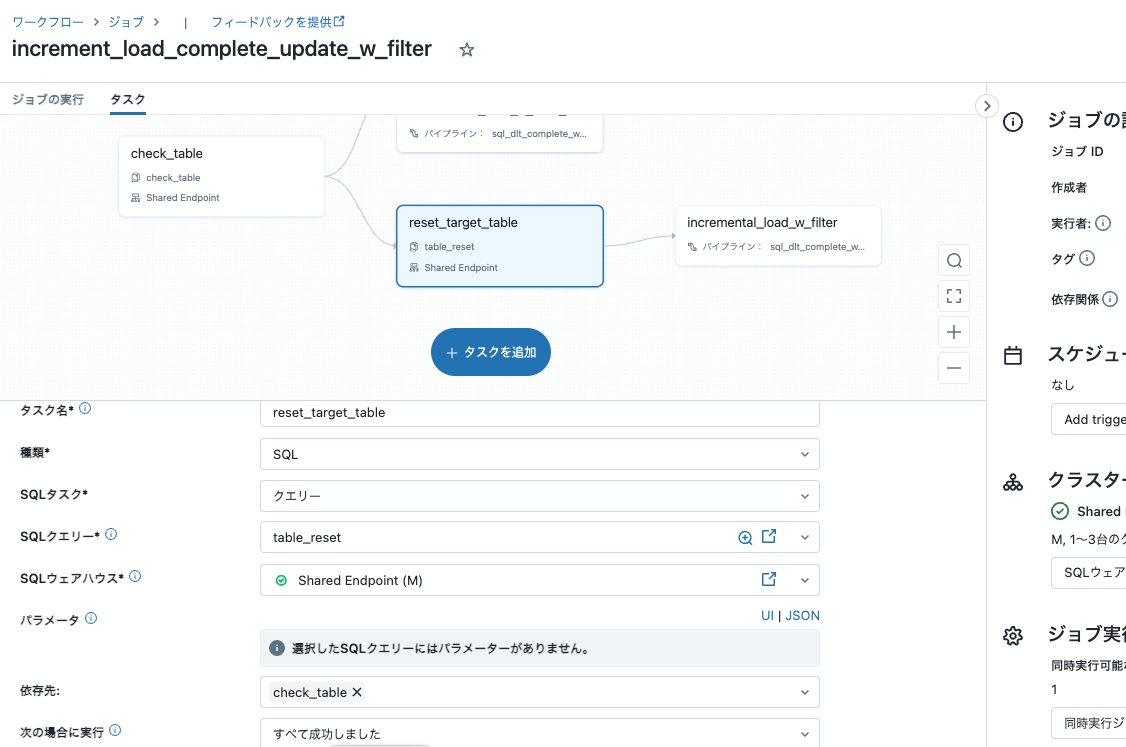
タスク: reset_target_table
- 種類: SQL
- SQLタスク: クエリー
- SQLクエリー: reset_table
- 依存先: check_table
- 次の場合に実行: すべて成功しました
タスク: incremental_load_w_filter_w_reset
- 種類: Delta Live Tablesパイプライン
- パイプライン: sql_dlt_complete_w_filter
- Delta Live Tablesパイプラインで完全なリフレッシュをトリガーする: チェックしない
- 依存先: reset_target_table
- 次の場合に実行: すべて成功しました
ジョブ定義のJSONはこちらとなります。
{
"run_as": {
"user_name": "takaaki.yayoi@databricks.com"
},
"name": "increment_load_complete_update_w_filter",
"email_notifications": {
"no_alert_for_skipped_runs": false
},
"webhook_notifications": {},
"timeout_seconds": 0,
"max_concurrent_runs": 1,
"tasks": [
{
"task_key": "check_table",
"run_if": "ALL_SUCCESS",
"sql_task": {
"query": {
"query_id": "bb7bfe8f-166c-42e6-8165-3266aa7d5d91"
},
"warehouse_id": "2e1a7a349827f40c"
},
"timeout_seconds": 0,
"email_notifications": {},
"notification_settings": {
"no_alert_for_skipped_runs": false,
"no_alert_for_canceled_runs": false,
"alert_on_last_attempt": false
}
},
{
"task_key": "incremental_load_w_filter_wo_reset",
"depends_on": [
{
"task_key": "check_table"
}
],
"run_if": "ALL_FAILED",
"pipeline_task": {
"pipeline_id": "b05bea64-463a-4e9d-b3a0-c41dde5aa104",
"full_refresh": false
},
"timeout_seconds": 0,
"email_notifications": {},
"notification_settings": {
"no_alert_for_skipped_runs": false,
"no_alert_for_canceled_runs": false,
"alert_on_last_attempt": false
}
},
{
"task_key": "reset_target_table",
"depends_on": [
{
"task_key": "check_table"
}
],
"run_if": "ALL_SUCCESS",
"sql_task": {
"query": {
"query_id": "ba8c07e3-7f5d-4bb8-a614-4484afd90830"
},
"warehouse_id": "2e1a7a349827f40c"
},
"timeout_seconds": 0,
"email_notifications": {},
"notification_settings": {
"no_alert_for_skipped_runs": false,
"no_alert_for_canceled_runs": false,
"alert_on_last_attempt": false
}
},
{
"task_key": "incremental_load_w_filter",
"depends_on": [
{
"task_key": "reset_target_table"
}
],
"run_if": "ALL_SUCCESS",
"pipeline_task": {
"pipeline_id": "b05bea64-463a-4e9d-b3a0-c41dde5aa104",
"full_refresh": false
},
"timeout_seconds": 0,
"email_notifications": {},
"notification_settings": {
"no_alert_for_skipped_runs": false,
"no_alert_for_canceled_runs": false,
"alert_on_last_attempt": false
}
}
],
"format": "MULTI_TASK"
}
動作確認
データを準備します。別にノートブックを作成し、7/6のデータのみを保存します。
data_07_06 = [{"Date": "2023/07/06", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Date": "2023/07/06", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Date": "2023/07/06", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Date": "2023/07/06", "Category": 'D', "ID": 4, "Value": 33.87, "Truth": True}
]
df_07_06 = spark.createDataFrame(data_07_06)
display(df_07_06)
data_07_07 = [{"Date": "2023/07/07", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Date": "2023/07/07", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
#{"Date": "2023/07/07", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Date": "2023/07/07", "Category": 'D', "ID": 4, "Value": 33.87, "Truth": True}
]
df_07_07 = spark.createDataFrame(data_07_07)
display(df_07_07)
data_07_08 = [#{"Date": "2023/07/08", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
#{"Date": "2023/07/08", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Date": "2023/07/08", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": True},
{"Date": "2023/07/08", "Category": 'E', "ID": 5, "Value": 33.87, "Truth": True}
]
df_07_08 = spark.createDataFrame(data_07_08)
display(df_07_08)
save_path = f"{data_path}/2023/07/06/"
df_07_06.write.format("parquet").option("header", "true").mode("overwrite").save(save_path)
display(dbutils.fs.ls(f"{data_path}/2023/07"))

初回実行
ジョブを実行します。
初回はテーブルが存在しないので、上のルートが実行されます。テーブルをリセットせずにDLTパイプラインが実行されます。
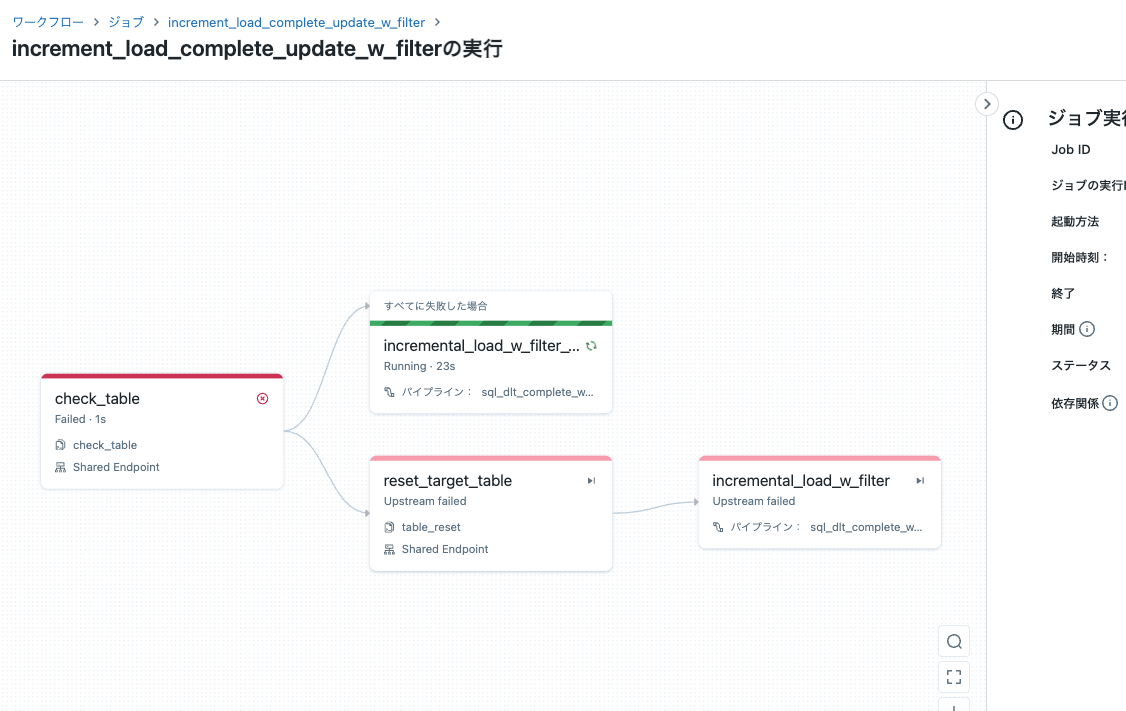
DLTパイプラインの実行結果を確認すると、cloudFiles.includeExistingFiles=falseが設定されているので、7/6のデータは処理されません。
テーブルは作成されますが、中身は空です。
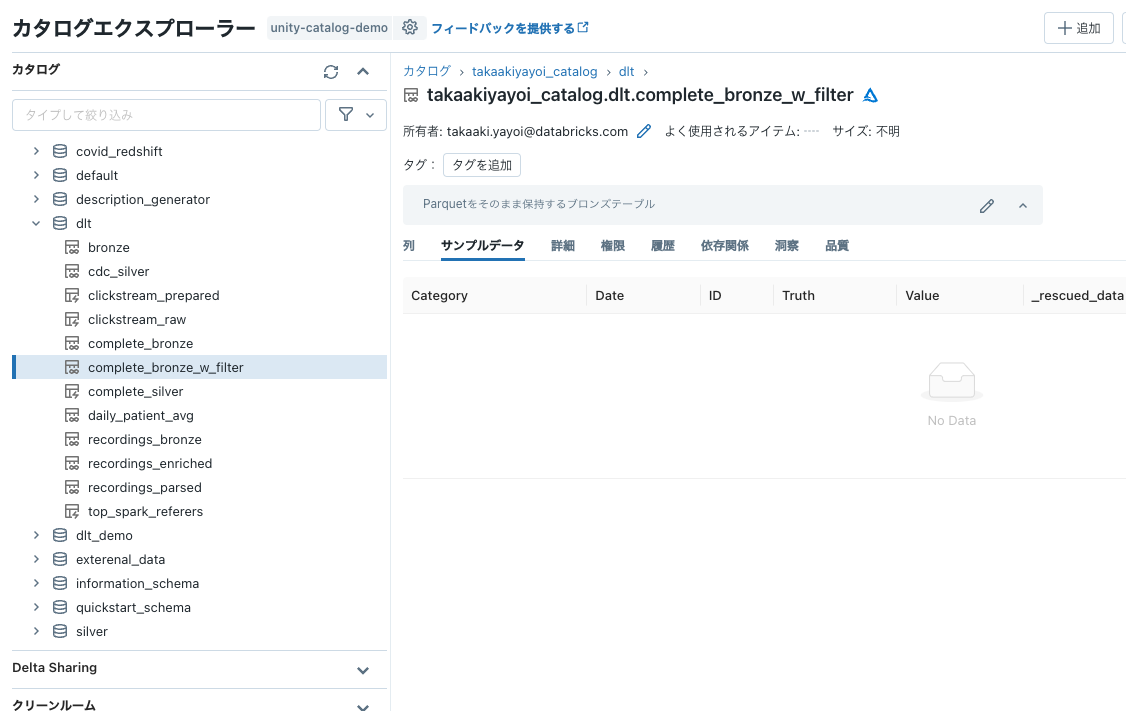
2回目以降の実行
別のノートブックで7/7のデータを保存します。
save_path = f"{data_path}/2023/07/07/"
df_07_07.write.format("parquet").option("header", "true").mode("overwrite").save(save_path)
display(dbutils.fs.ls(f"{data_path}/2023/07"))
7/6と7/7のデータが存在しています。

再度ジョブを実行します。今度はテーブルが存在しているので下のルートが実行されます。
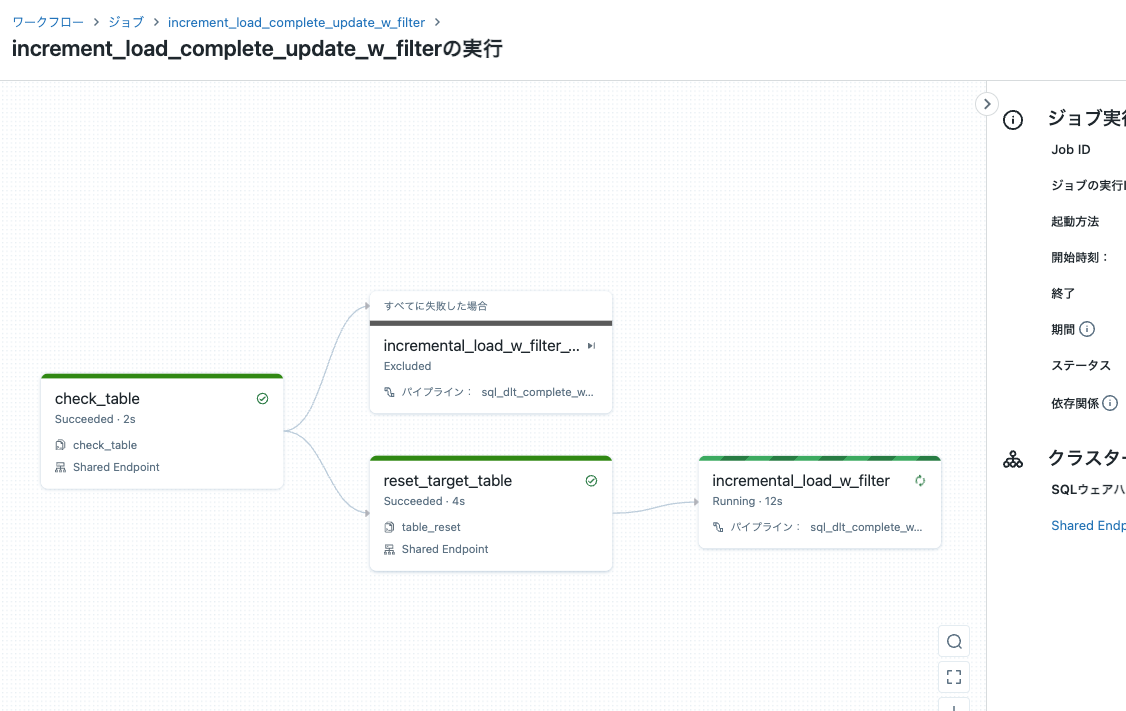
今度は7/7のデータのみが処理され、テーブルが洗い替えされます。
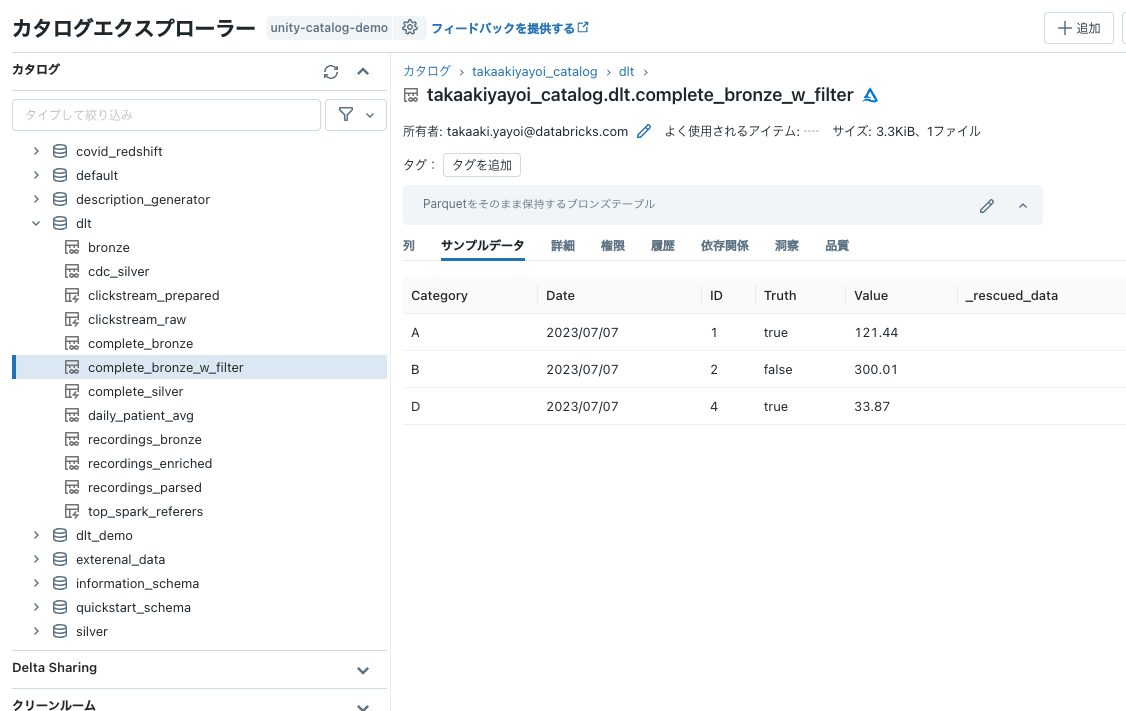
7/8のデータが追加された後でジョブを実行すると7/8のデータで洗い替えされます。
