Databricks AutoMLでトレーニングを実行する際に、Databricks Feature Storeの特徴量テーブルと連携できることに最近気づきました。
これによって、Feature Storeで特徴量を管理しつつ、お手軽にAutoMLを活用することができます。
マニュアルの該当部分だけ訳します。
Feature Storeのインテグレーション
Feature Storeのインテグレーション
Databricks機械学習ランタイム11.3以降では、分類、回帰問題における入力データセットを拡張するために、Feature Storeの既存の特徴量テーブルを使用することができます。
既存の特徴量テーブルを使うには、AutoMLのUIで特徴量テーブルを選択するか、AutoMLランの設定でfeature_store_lookupsを設定します。
feature_store_lookups = [
{
"table_name": "example.trip_pickup_features",
"lookup_key": ["pickup_zip", "rounded_pickup_datetime"],
},
{
"table_name": "example.trip_dropoff_features",
"lookup_key": ["dropoff_zip", "rounded_dropoff_datetime"],
}
]
サンプルノートブックのウォークスルー
実際にノートブックから実行してみます。
このノートブックでは以下のことを行います:
- Feature Storeで新規特徴量テーブルを作成
- AutoMLエクスペリメントでFeature Storeの特徴量テーブルを使用
使用する既存の特徴量テーブルがある場合には、特徴量テーブルを用いたAutoMLエクスペリメントの作成セクションまでスキップすることができます。
要件
- Databricks機械学習ランタイム11.3以降

データのロード
完全なNYC Taxiデータから生成されたデータを使用します。
# `nyc-taxi-tiny`データセットのロード
raw_data = spark.read.format("delta").load("/databricks-datasets/nyctaxi-with-zipcodes/subsampled")
display(raw_data)

特徴量の計算
from databricks import feature_store
from pyspark.sql.functions import *
from pyspark.sql.types import FloatType, IntegerType, StringType
from pytz import timezone
@udf(returnType=IntegerType())
def is_weekend(dt):
tz = "America/New_York"
return int(dt.astimezone(timezone(tz)).weekday() >= 5) # 5 = 土曜日, 6 = 日曜日
@udf(returnType=StringType())
def partition_id(dt):
# datetime -> "YYYY-MM"
return f"{dt.year:04d}-{dt.month:02d}"
def filter_df_by_ts(df, ts_column, start_date, end_date):
if ts_column and start_date:
df = df.filter(col(ts_column) >= start_date)
if ts_column and end_date:
df = df.filter(col(ts_column) < end_date)
return df
def pickup_features_fn(df, ts_column, start_date, end_date):
"""
pickup_features特徴量グループの計算
特徴量を時間レンジで限定するには、kwargsとしてts_column、start_date、end_dateを指定します
"""
df = filter_df_by_ts(
df, ts_column, start_date, end_date
)
pickupzip_features = (
df.groupBy(
"pickup_zip", window("tpep_pickup_datetime", "1 hour", "15 minutes")
) # 1時間ウィンドウ、15分毎のスライディング
.agg(
mean("fare_amount").alias("mean_fare_window_1h_pickup_zip"),
count("*").alias("count_trips_window_1h_pickup_zip"),
)
.select(
col("pickup_zip").alias("zip"),
unix_timestamp(col("window.end")).alias("ts").cast(IntegerType()),
partition_id(to_timestamp(col("window.end"))).alias("yyyy_mm"),
col("mean_fare_window_1h_pickup_zip").cast(FloatType()),
col("count_trips_window_1h_pickup_zip").cast(IntegerType()),
)
)
return pickupzip_features
def dropoff_features_fn(df, ts_column, start_date, end_date):
"""
dropoff_features特徴量グループの計算
特徴量を時間レンジで限定するには、kwargsとしてts_column、start_date、end_dateを指定します
"""
df = filter_df_by_ts(
df, ts_column, start_date, end_date
)
dropoffzip_features = (
df.groupBy("dropoff_zip", window("tpep_dropoff_datetime", "30 minute"))
.agg(count("*").alias("count_trips_window_30m_dropoff_zip"))
.select(
col("dropoff_zip").alias("zip"),
unix_timestamp(col("window.end")).alias("ts").cast(IntegerType()),
partition_id(to_timestamp(col("window.end"))).alias("yyyy_mm"),
col("count_trips_window_30m_dropoff_zip").cast(IntegerType()),
is_weekend(col("window.end")).alias("dropoff_is_weekend"),
)
)
return dropoffzip_features
from datetime import datetime
pickup_features = pickup_features_fn(
raw_data, ts_column="tpep_pickup_datetime", start_date=datetime(2016, 1, 1), end_date=datetime(2016, 1, 31)
)
dropoff_features = dropoff_features_fn(
raw_data, ts_column="tpep_dropoff_datetime", start_date=datetime(2016, 1, 1), end_date=datetime(2016, 1, 31)
特徴量テーブルのデータの一つであるpickup_features(乗車時の特徴量)を確認します。
display(pickup_features)
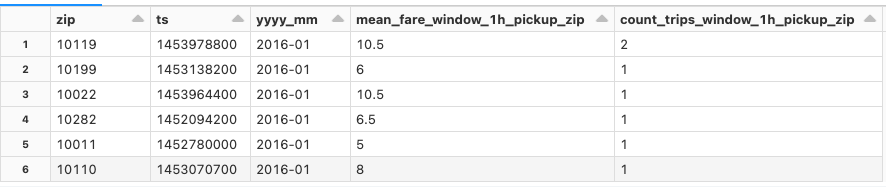
新規の特徴量テーブルを作成するためにFeature Storeライブラリを使用
%sql
CREATE DATABASE IF NOT EXISTS feature_store_automl_takaaki_yayoi;
fs = feature_store.FeatureStoreClient()
ここでは、ランダムな文字列を埋め込んで特徴量テーブルの名前を生成しています。
import uuid
feature_database = "feature_store_automl_takaaki_yayoi"
random_id = str(uuid.uuid4())[:8]
pickup_features_table = f"{feature_database}.trip_pickup_features_{random_id}"
dropoff_features_table = f"{feature_database}.trip_dropoff_features_{random_id}"
Feature StoreのAPIを通じて特徴量テーブルを作成します。これによって、特徴量テーブルを作成したノートブックや元データ、特徴量を使用しているモデルやジョブなどがトラッキングされる様になります。加えて、機械学習モデルトレーニングのロジックから、特徴量生成のロジックを分離できる様になります。
spark.conf.set("spark.sql.shuffle.partitions", "5")
fs.create_table(
name=pickup_features_table,
primary_keys=["zip", "ts"],
df=pickup_features,
partition_columns="yyyy_mm",
description="Taxi Fares. Pickup Features",
)
fs.create_table(
name=dropoff_features_table,
primary_keys=["zip", "ts"],
df=dropoff_features,
partition_columns="yyyy_mm",
description="Taxi Fares. Dropoff Features",
)
特徴量テーブルを用いたAutoMLエクスペリメントの作成
トレーニングデータを準備します。
from pyspark.sql import *
from pyspark.sql.functions import current_timestamp
from pyspark.sql.types import IntegerType
import math
from datetime import timedelta
import mlflow.pyfunc
def rounded_unix_timestamp(dt, num_minutes=15):
"""
datetimeのdtをintervalのnum_minutesに切り上げ、Unixタイムスタンプを返却します
"""
nsecs = dt.minute * 60 + dt.second + dt.microsecond * 1e-6
delta = math.ceil(nsecs / (60 * num_minutes)) * (60 * num_minutes) - nsecs
return int((dt + timedelta(seconds=delta)).timestamp())
rounded_unix_timestamp_udf = udf(rounded_unix_timestamp, IntegerType())
def rounded_taxi_data(taxi_data_df):
# タクシーデータのタイムスタンプを15分、30分間隔に丸めて、pickupやdropoffの特徴量をそれぞれjoinすることができます
taxi_data_df = (
taxi_data_df.withColumn(
"rounded_pickup_datetime",
rounded_unix_timestamp_udf(taxi_data_df["tpep_pickup_datetime"], lit(15)),
)
.withColumn(
"rounded_dropoff_datetime",
rounded_unix_timestamp_udf(taxi_data_df["tpep_dropoff_datetime"], lit(30)),
)
.drop("tpep_pickup_datetime")
.drop("tpep_dropoff_datetime")
)
taxi_data_df.createOrReplaceTempView("taxi_data")
return taxi_data_df
taxi_data = rounded_taxi_data(raw_data)
display(taxi_data)
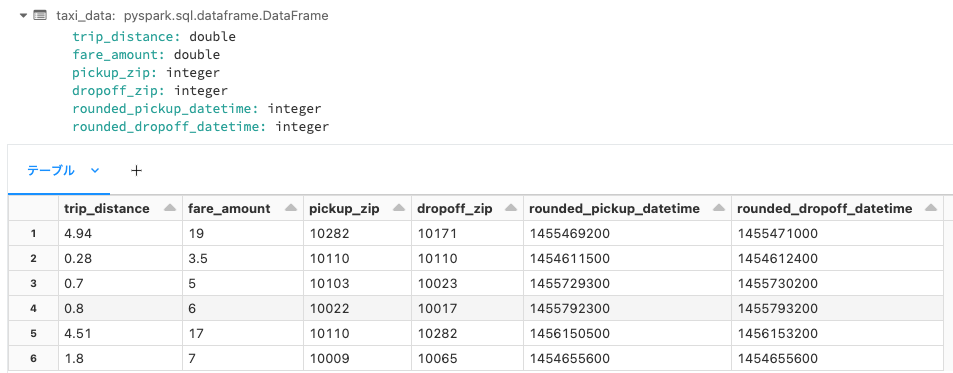
Python API経由でAutoMLを実行します。この際には上述の通り、feature_store_lookupsを指定して、トレーニングデータと特徴量テーブルをどの様にjoinするのかを指定します。
import databricks.automl
# AutoMLで参照する特徴量テーブルの検索設定(テーブル、検索キー)
feature_store_lookups = [
{
"table_name": pickup_features_table,
"lookup_key": ["pickup_zip", "rounded_pickup_datetime"],
},
{
"table_name": dropoff_features_table,
"lookup_key": ["dropoff_zip", "rounded_dropoff_datetime"],
}
]
# AutoMLの実行
summary = databricks.automl.regress(taxi_data,
target_col="fare_amount",
timeout_minutes=120,
feature_store_lookups=feature_store_lookups)
これによって、Feature Storeの特徴量を用いたAutoMLが実行され、ベストなモデルを手に入れることができます。
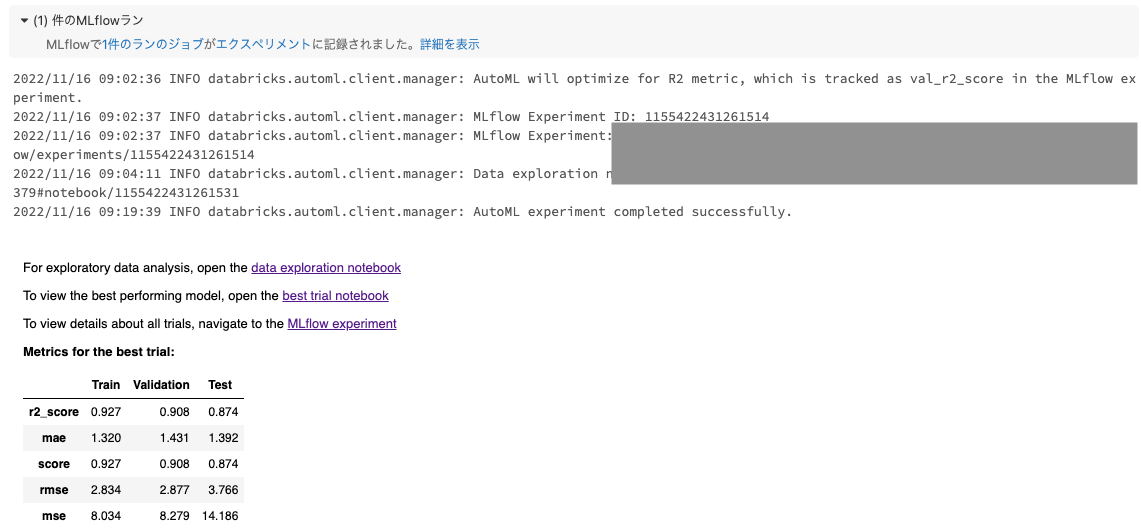
結合されている特徴量テーブルを確認することもできます。
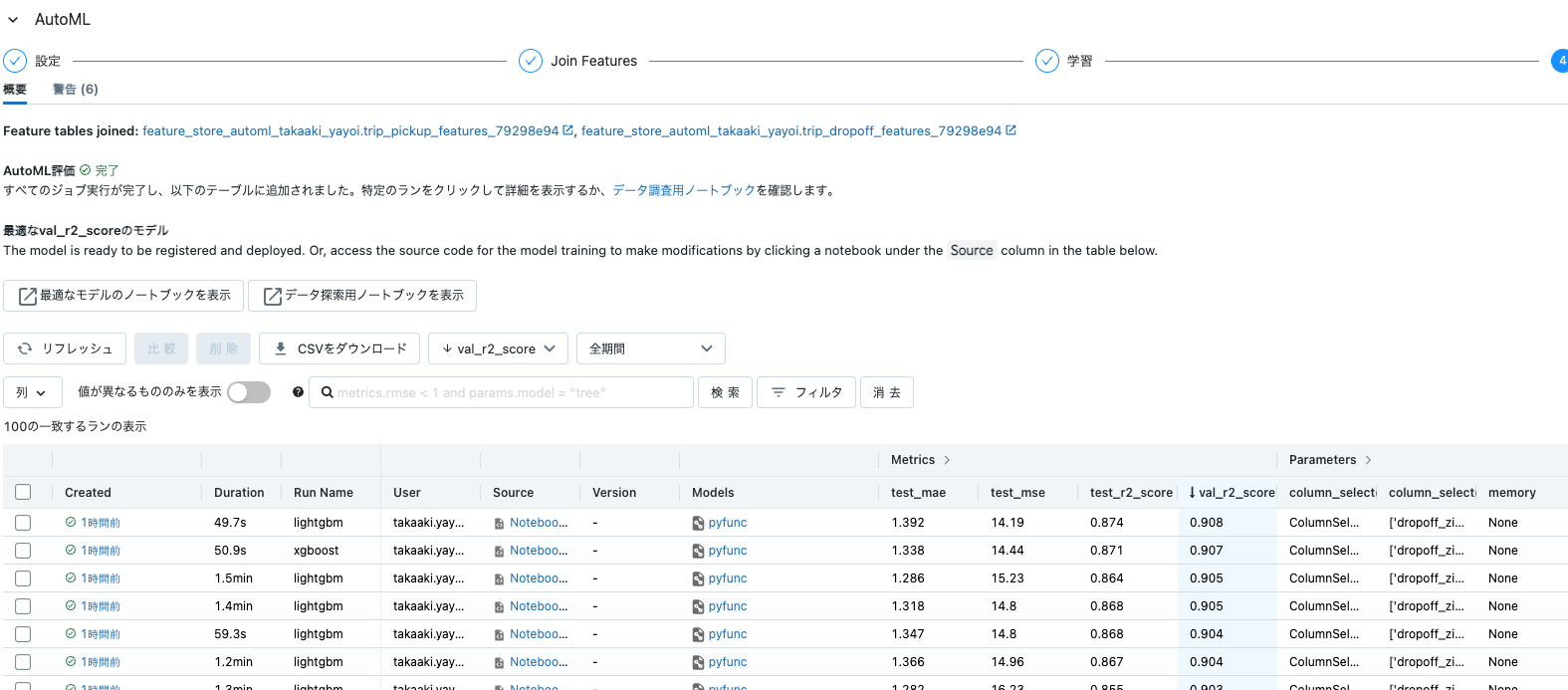

このように、特徴量にガバナンスを効かせつつも、自由度を持ってAutoMLを実行することができます。しかも、DatabrickのAutoMLはガラスボックスアプローチを採用しているので、ベストなモデルを生成したロジックはすべてPythonノートブックとして参照することができ、更なる改善のために手を加えることが可能です。
以下がベストモデルを作成したノートブックです。今回のケースでは、LightGBMのモデルがベストなパフォーマンスを示しました。

なお、冒頭で触れた通り、GUIからも特徴量テーブルを選択することが可能です。
