Spark Web UI - Understanding Spark Execution — SparkByExamplesの翻訳です。
Apache Sparkは、ご自身のSpark/PySparkアプリケーション、Sparkクラスターのリソース消費、Spark設定をモニタリングするためのWeb UI/ユーザーインタフェース(Jobs、Stages、Tasks、Storage、Environment、Executors、SQL)を提供しています。
SparkがどのようにSpark/PySparkのジョブを実行するのかをより理解するためには、これら一連のユーザーインタフェースが役立ちます。本書では、小さなアプリケーションを実行し、Spark Web UIのそれぞれのセクションを用いることで、どのようにSparkがこれを実行するのかを説明します。
Spark UIに入っていく前に、以下の2つのコンセプトを学びます。
これら2つを簡単に説明させてください。あなたのアプリケーションコードは、Sparkジョブを実行するようにドライバーに指示を行う一連の命令であり、ドライバーはエグゼキューターの助けを借りて、どのようにこれを達成するのかを決定します。
ドライバーに対する指令はTransformationとActionと呼ばれ、処理を起動します。
トランスフォーメーションとアクションを行う小さなアプリケーションを記述しました。
![]()
アプリケーションコード
ここでは、csvファイルを読み込み、データフレームを作成してから、データフレームの行数をカウントしています。アプリケーションがSpark UI上でどのように表示されているのかを学んでいきましょう。
Spark UIは以下のタブから構成されます。
- Spark Jobs
- Stages
- Tasks
- Storage
- Environment
- Executors
- SQL
ローカルでSparkアプリケーションを実行している際、Spark UIは http://localhost:4040/ を用いることでアクセスすることができます。デフォルトではSpark UIはポート4040で動作し、Sparkアプリケーションをトラッキングするために幾つかの追加のUIが役に立ちます。
Spark Web UI
- Spark Application UI: http://localhost:4040/
- Resource Manager: http://localhost:9870
- Spark JobTracker: http://localhost:8088/
- Node Specific Info: http://localhost:8042/
注意
これらのURLにアクセスするためには、Sparkアプリケーションが実行中の状態にある必要があります。Sparkアプリケーションの状態に関係なしにURLにアクセスし、常にSpark UIにアクセスしたい場合には、Spark History serverを起動する必要があります。
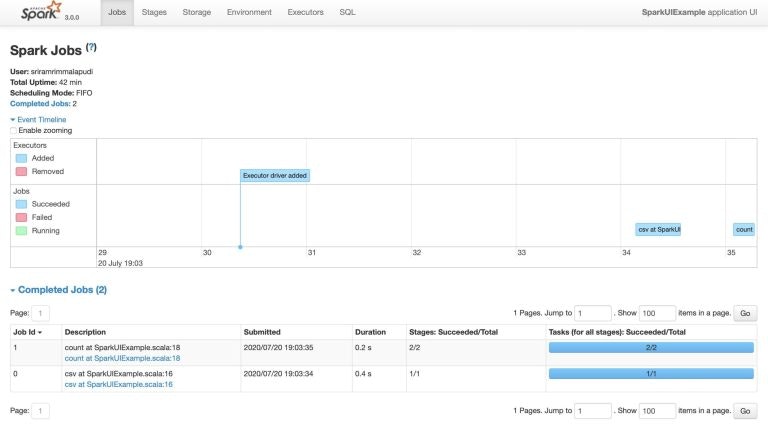
1. Spark Jobsタブ
Jobsタブ
Jobsセクションで気づいていただきたい詳細な点は、Scheduling mode、number of Spark Jobs、number of stages、およびSparkジョブのnumber of stagesです。
1.1 Scheduling mode(スケジューリングモード)
スケジューリングモードは3つあります。
- Standaloneモード
- YARNモード
-
Mesos

Spark Schedulingタブ
1.2 Number of Spark Jobs(Sparkジョブの数)
Sparkジョブの数はアプリケーションにおけるアクションの数と同じであり、Sparkジョブは少なくとも1つのステージが必要とすることを、常に頭に留めておく必要があります。上のアプリケーションでは、3つのSparkジョブが含まれています(0、1、2)。
- Job 0. CSVファイルの読み込み
- Job 1. ファイルからのInferschema
- Job 2. Countのチェック
上の図を見ると、3つのアクションから3つのSparkジョブが生成されていることが明らかに分かります。
1.3 Number of Stages(ステージの数)
それぞれのWide Transformationは異なるNumber of Stagesを生み出します。我々のケースでは、Spark job0とSpark job1は個々のステージを持っていますが、Spark job3はデータのパーティションのため2つのステージが存在します。
1.4 Description(説明)
Descriptionには、関連づけられるSparkJobののステータス、DAGの可視化、完了したステージのような完全な詳細情報へのリンクを提供します。以降のパートで詳細を説明します。
2. Stagesタブ
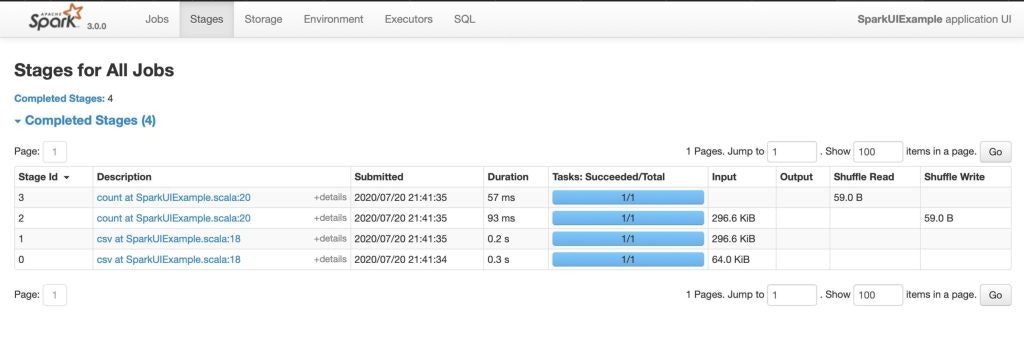
Sparkステージタブ
2つの方法でStageタブにナビゲートすることができます。
- それぞれのSparkジョブのDescriptionを選択します(選択されたSparkジョブに対応するステージのみを表示します)。
- Sparkジョブタブの上でStagesオプションを選択します(アプリケーションの全てのステージを表示します)。
我々のアプリケーションでは、合計4つのステージがあります。
Stageタブには、SparkアプリケーションにおけるすべてのSparkジョブの全てのステージの現在の状態を表示するサマリーページが表示されます。
それぞれのステージで確認できるタスクの数は、スパークが処理を行うパーティションの数であり、ステージ内のそれぞれのタスクには、sparkによる同じ処理が含まれますが、異なるパーティションが対象となります。
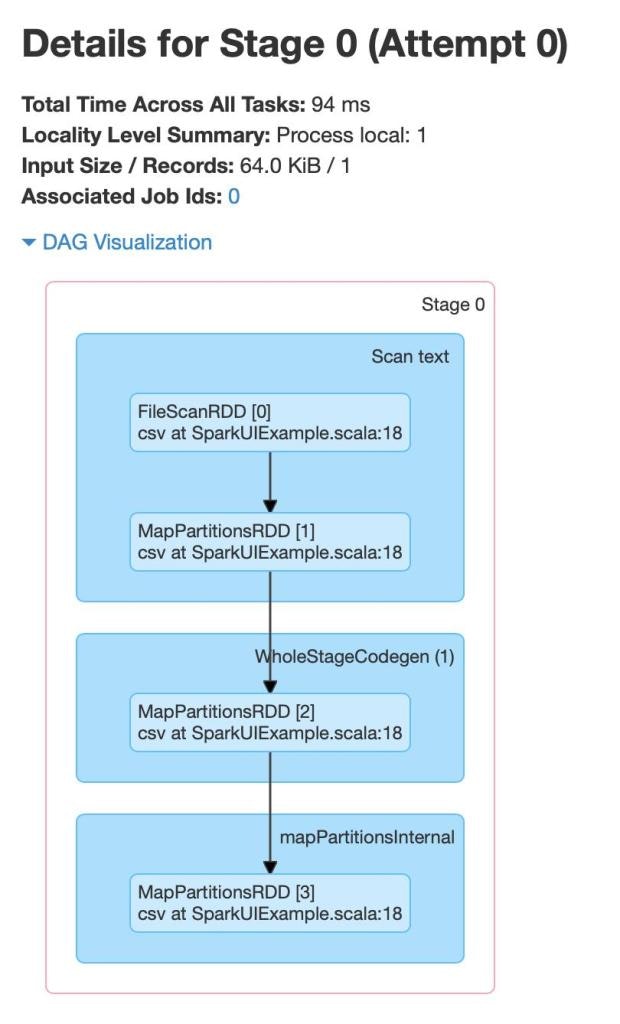
Stage 0
Stage detail(ステージ詳細)
ステージの詳細には、ステージのDirected Acyclic Graph (DAG)が表示され、頂点がRDDとデータフレームを表示し、エッジが適用されたオペレーションを表現しています。
ステージのオペレーションを分析しましょう。Stage0のオペレーションは、以下となっています。
- FileScanRDD
- MapPartitionsRDD
FileScanRDD
FileScanはファイルからのデータの読み込みを表現します。PartitionedFiles(ファイルブロック)のカスタムRDDパーティションであるFilePartitionsが所定のものとなります。我々のシナリオにおいては、CSVファイルが読み込まれています。
MapPartitionsRDD
マップパーティションのトランスフォーメーションを行う際、MapPartitionsRDDが作成されます。
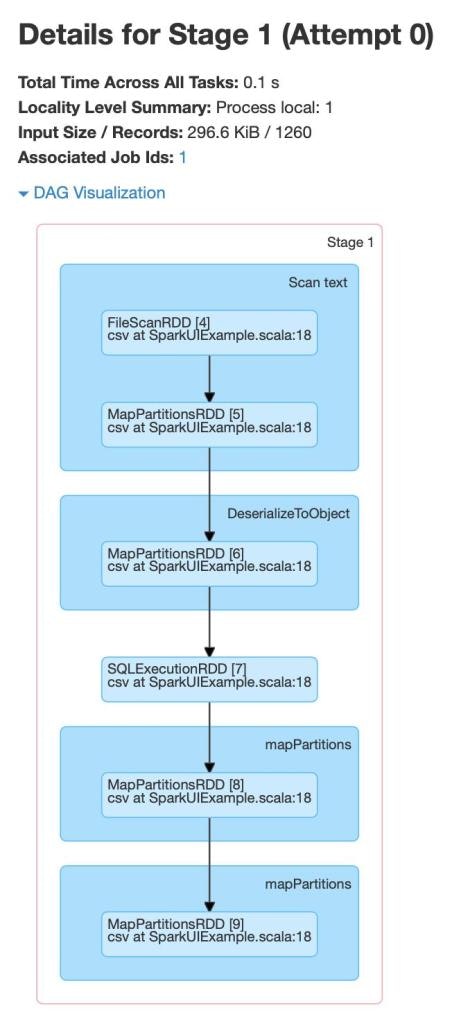
Stage 1
Stage(1)のオペエレーションは以下のものとなります。
- FileScanRDD
- MapPartitionsRDD
- SQLExecutionRDD
ファイルスキャンとMapPartitionsRDDは既に説明しました。SQLExecutionRDDを見ていきましょう。
SQLExecutionRDD
SQLExecutionRDDは、単一の構造化クエリーの実行を共に構成する複数のSparkジョブを追跡する際に用いられるSparkプロパティです。
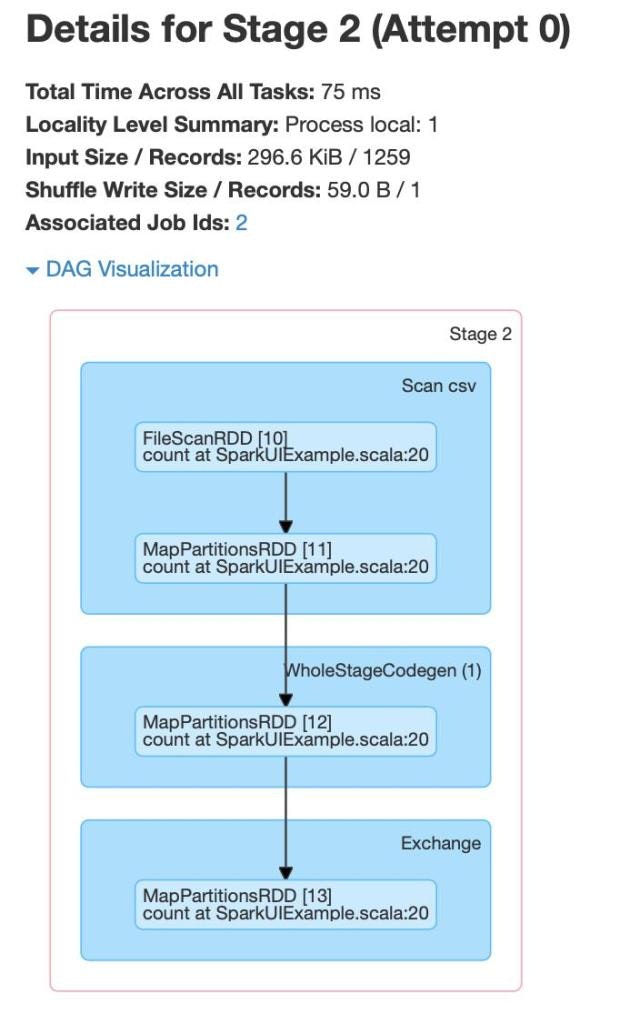
Stage 2
Stage(2)とStage(3)のオペレーションは以下から構成されます。
- FileScanRDD
- MapPartitionsRDD
- WholeStageCodegen
- Exchange
Wholestagecodegen
複数の物理オペレーターを統合するSpark SQLにおける物理クエリーのオプティマイザーです。
Exchange
COUNTメソッドによってExchangeが実行されます。データはパーティションに分割され、エグゼキューター間で共有され、個々のパーティションに対するカウントが累積されることでカウントの合計が計算されます。
これは、クラスター(エグゼキューター)におけるデータ移動であるシャッフルを表現します。もっとも高コストなオペレーションであり、パーティションの数が多くなると、エグゼキューター間のデータ交換もまた多くなります。
3. Tasks
タスクはそれぞれのステージの下部のスペースに位置付けられています。タスクページで注意すべきことは以下のことです。
- Input Size – ストレージに対する入力です。
- Shuffle Write - アウトプットはステージによる書き込みです。
4. Storageタブ
Storageタブには、アプリケーションで永続化されたRDDやデータフレームが表示されます。サマリーページには、全てのRDDのストレージのレベル、サイズ、パーティションが表示され、詳細ページにはRDD、データフレームにおける全てのパーティションに対するサイズと、アクセスしているエグゼキューターが表示されます。
5. Environmentタブ
Spark Environmentタブ
Environmentページには5つのパートがあります。ご自身のプロパティが適切に設定されているかどうかを確認するために役立ちます。
- Runtime Information: シンプルにJava、Scalaのバージョンのようなランタイムプロパティが含まれます。
-
Spark Properties: lists the application properties like
spark.app.nameやspark.driver.memoryのようなアプリケーションのプロパティの一覧を表示します。 -
Hadoop Properties: Hadoop、YARNに関係するプロパティの一覧を表示します。注意:
spark.hadoopのようなプロパティはこのパートには表示されずSpark Propertiesに表示されます。 - System Properties: JVMに関する詳細情報を表示します。
-
Classpath Entries: 様々なソースからロードされるクラスの一覧を表示し、クラスの競合を解決する際に役立ちます。
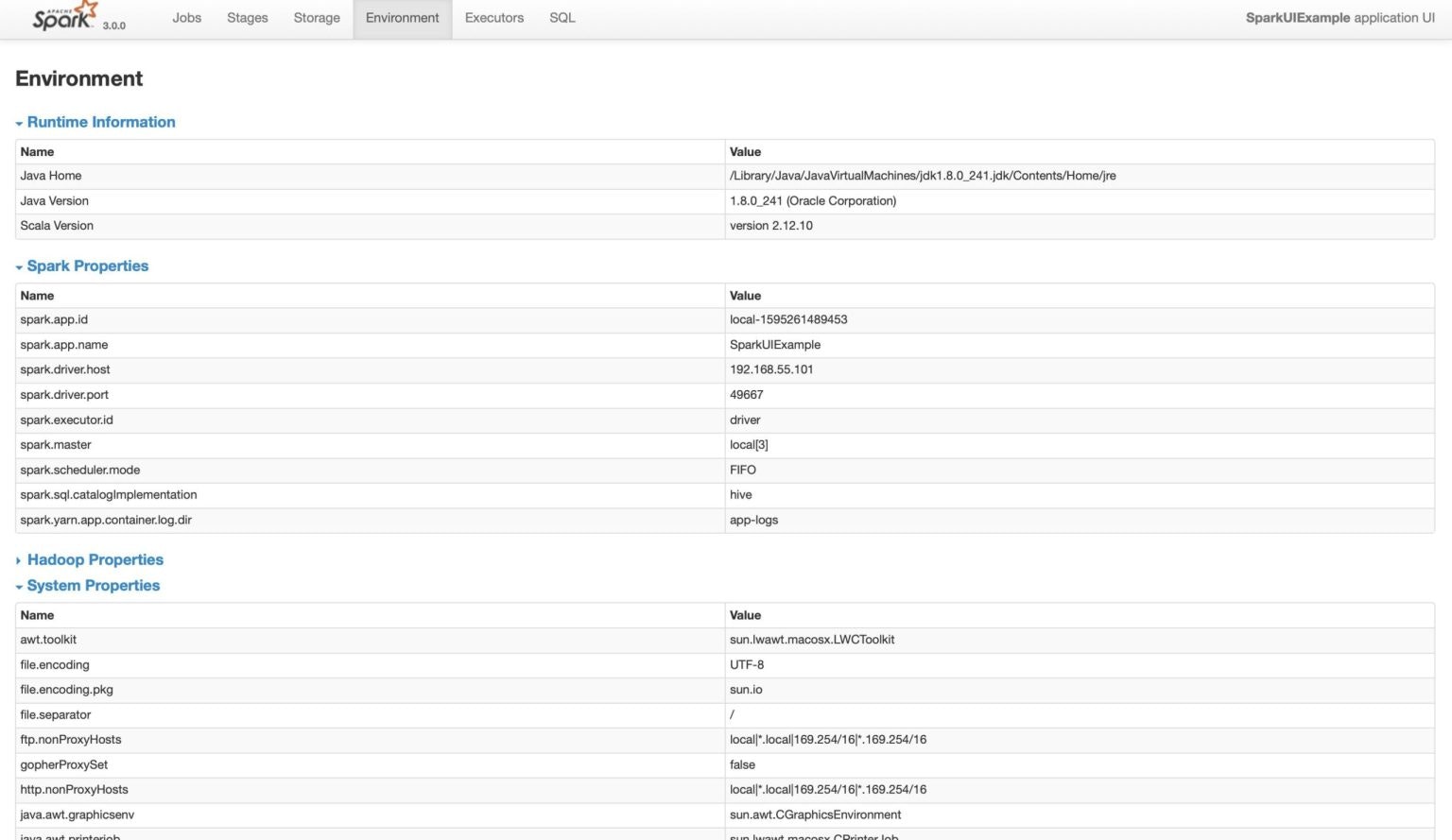
Spark Environmentプロパティ
Environmentタブには、JVM、Spark、システムプロパティなど様々な環境変数、設定値が表示されます。
6. Executorsタブ
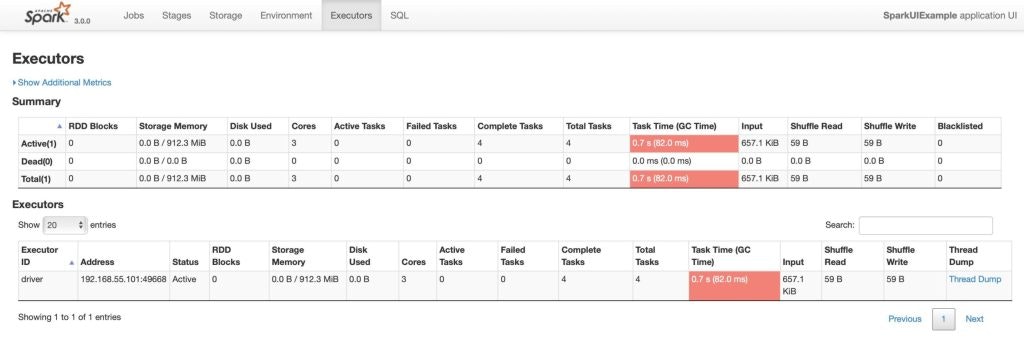
Spark Executorsタブ
Executorsタブには、アプリケーション向けに生成されたエグゼキューターに関する、メモリー、ディスク使用料、タスク、シャッフル情報などのサマリー情報が表示されます。Storage Memoryカラムには使用されたメモリー、データキャッシュのために確保されたメモリーの量が表示されます。
Executorsタブには、個々のエグゼキューターによって使用されているメモリー、ディスク、コアのようなリソース情報のみではなく、パフォーマンスに関する情報も表示されます。
Executoreには、Number of cores = 3と表示されており、3スレッドとlocalを指定しているので、Number of tasks = 4となります。
7. SQLタブ
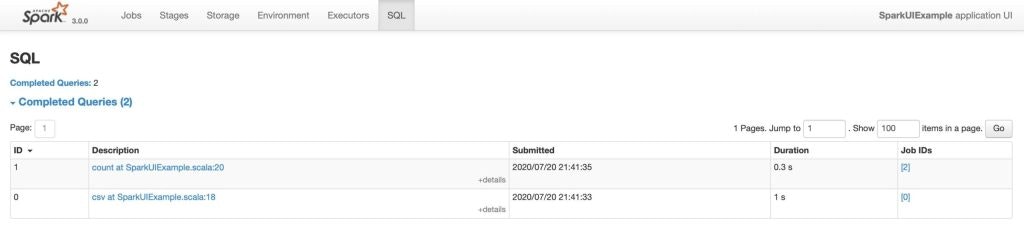
Spark SQLタブ
アプリケーションがSpark SQLクエリーを実行する際、SQLタブには時間、Sparkジョブ、クエリーに対する物理プラン、論理プランのような情報が表示されます。
我々のアプリケーションでは、ファイルとデータフレームに対する読み込み、カウントを実行しました。readとcountがSQLタブに表示されます。
いくつかのリソースは https://spark.apache.org/ に格納されています。
"……………学び続け、成長し続けましょう……………"