こちらの記事を一通り読んだので推論テーブル(inference tables)を試してみます。
注意
この機能はサーバレスモデルサービングのエンドポイントを前提としています。まだ日本リージョンでは利用できません。すみません。
推論テーブルとは
推論テーブルは、お使いのモデルサービングエンドポイントにおけるリクエストとレスポンスを自動で捕捉し、Unity CatalogのDeltaテーブルに記録します。MLモデルを監視、デバッグ、改善するためにこのテーブルのデータを後で活用することができます。
例えば、推論テーブルを活用することで以下のようなことを達成することができます:
- お使いのモデルの次のイテレーションの再トレーニングデータセットの作成。
- プロダクションのデータとモデルの品質モニタリングの実施。
- 疑わしい推論の診断とデバッグの実行。
- 再ロードされるべき誤ったラベルのデータの作成。
推論テーブルの有効化
すでに、作成済みのモデルサービングエンドポイントがあったので、設定変更の際に有効化します。この時点ではNot enabledとなっています。
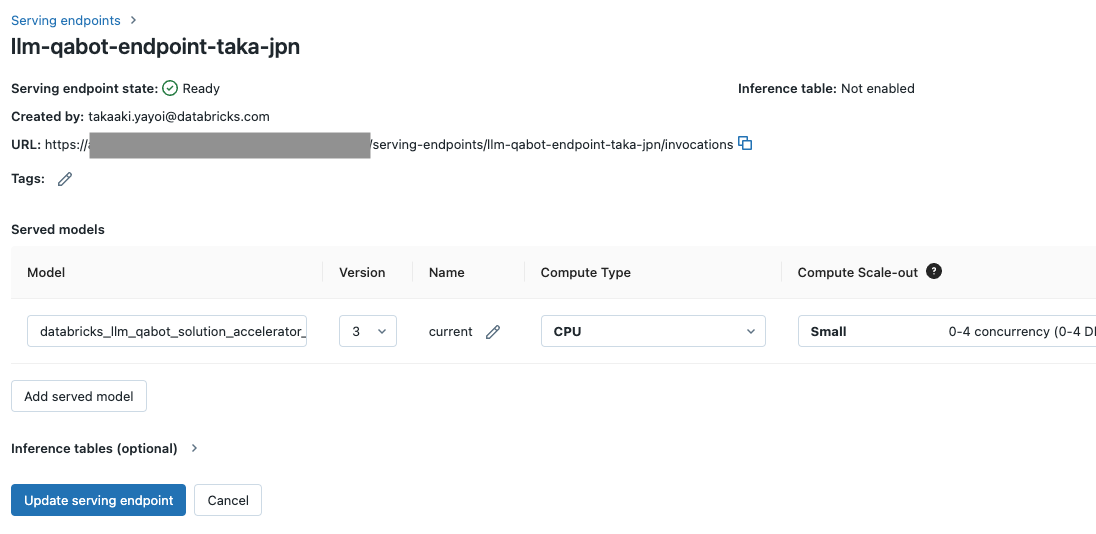
編集状態にして、Inference tables (optional) を展開します。
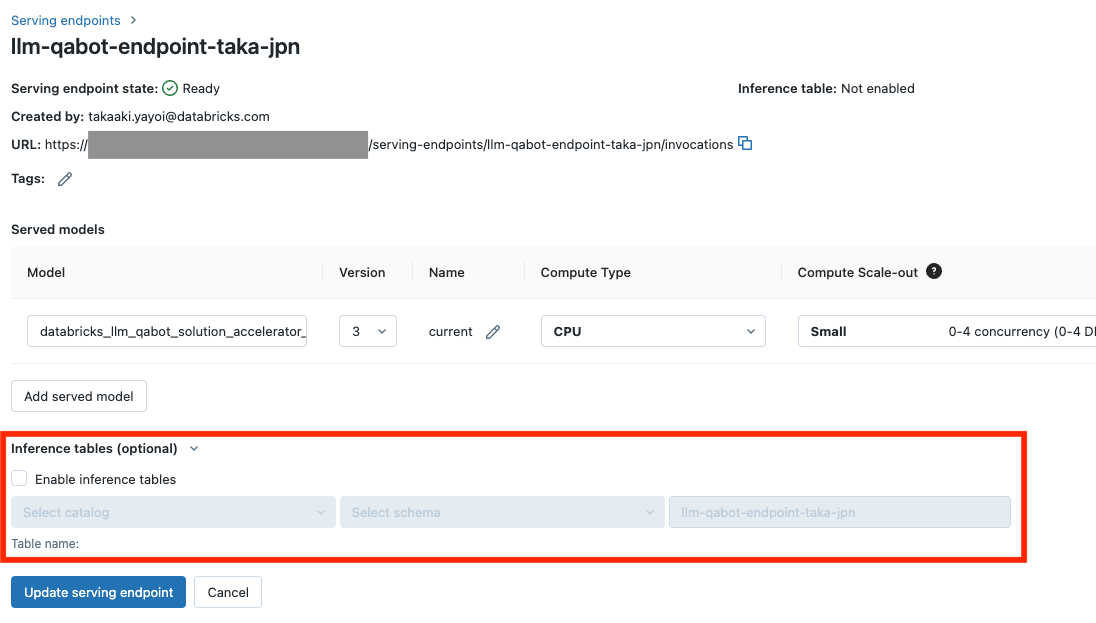
事前に格納用のカタログとスキーマ(データベース)を作成しておきます。ここでは、quickstart_catalog_takaとinference_tablesとなります。指定したらUpdate serving endpointをクリックします。
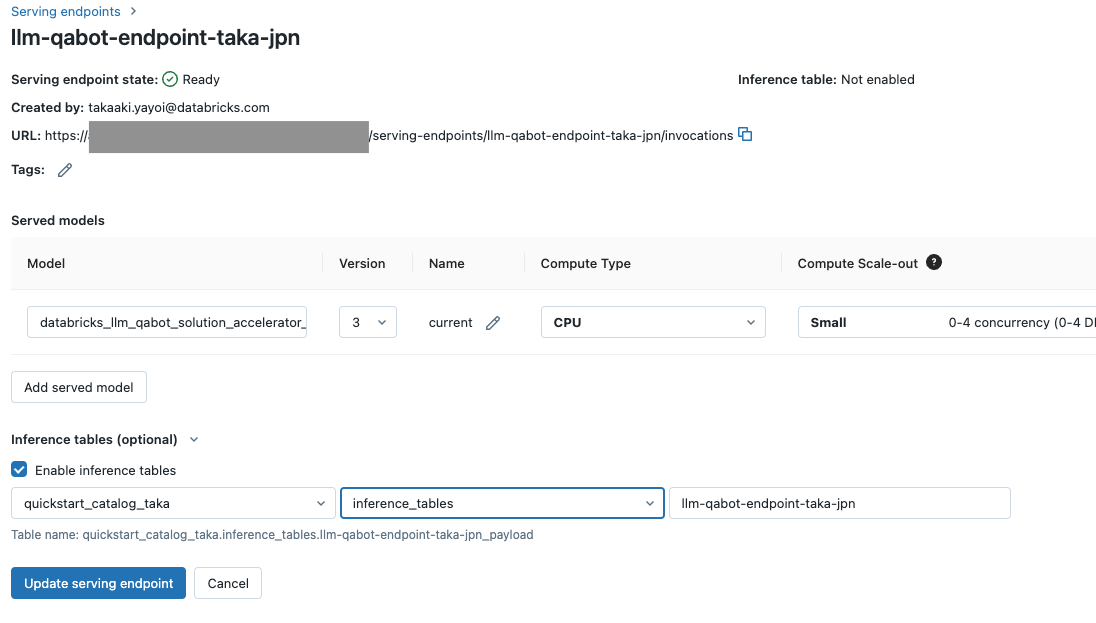
少し待つとInference tableがEnabledになります。
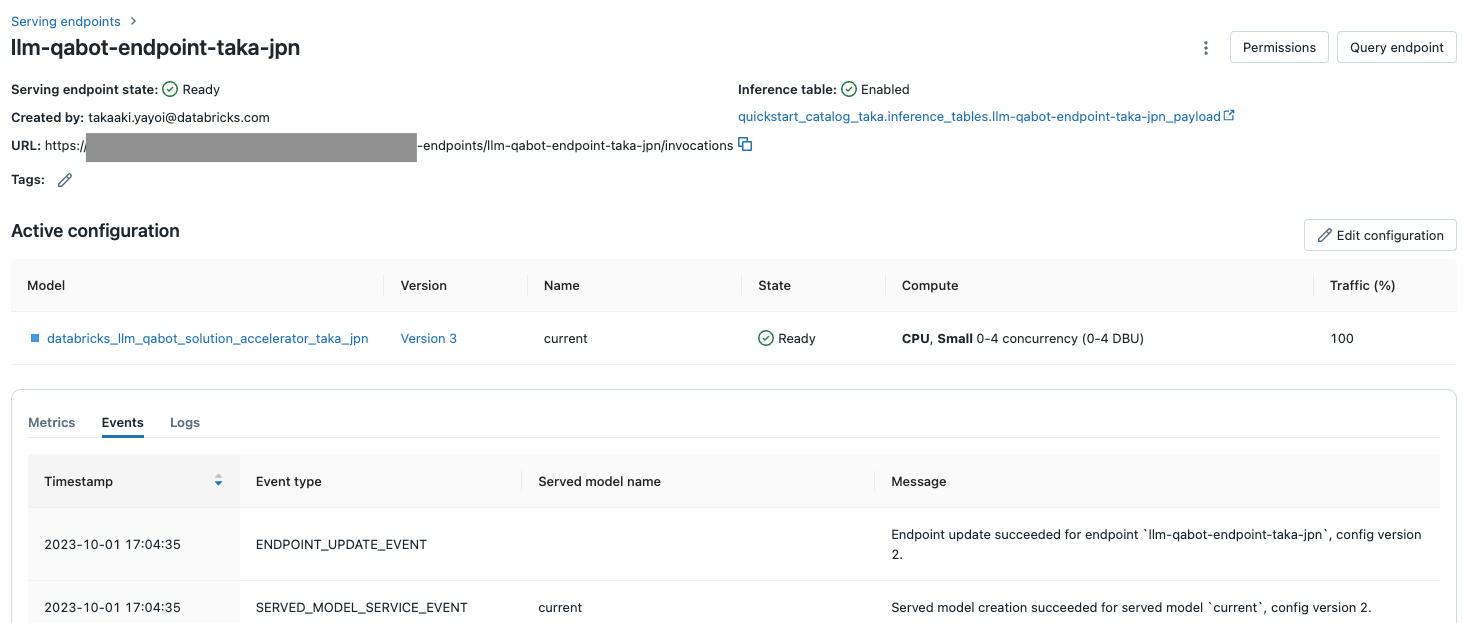
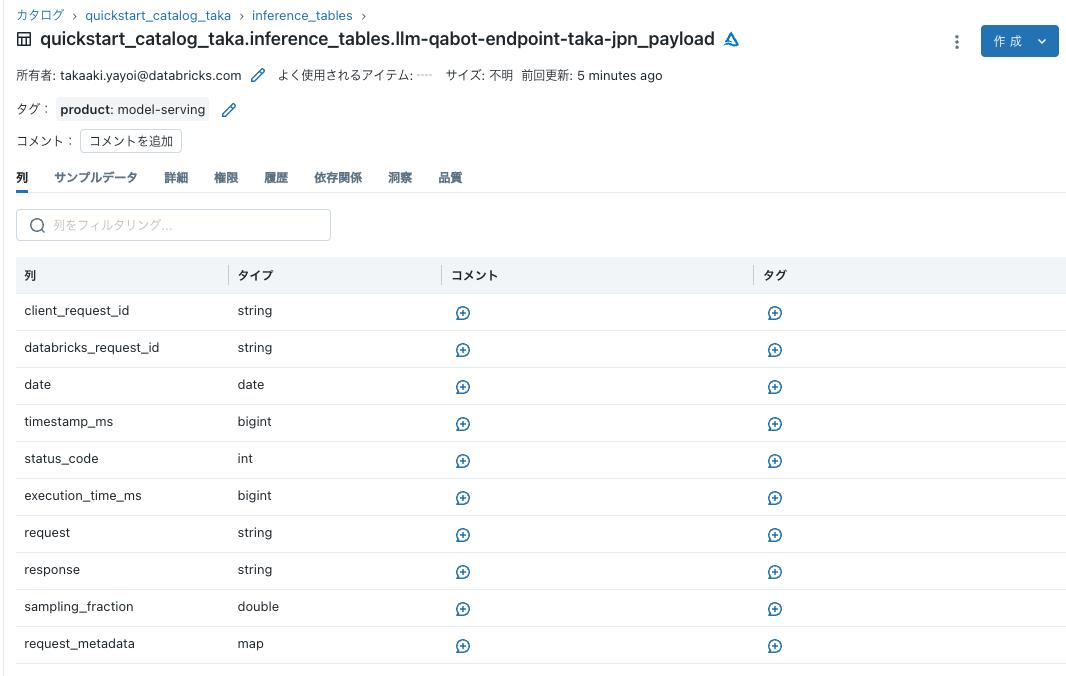
その下のテーブル名のリンクをクリックすると、カタログエクスプローラが開き推論テーブルにアクセスすることができます。まだこの時点ではレコードは存在しません。
推論テーブルの動作確認
モデルサービングエンドポイントを呼び出してみます。なお、このエンドポイントはこちらで作成したDatabricks Q&A botのものです。
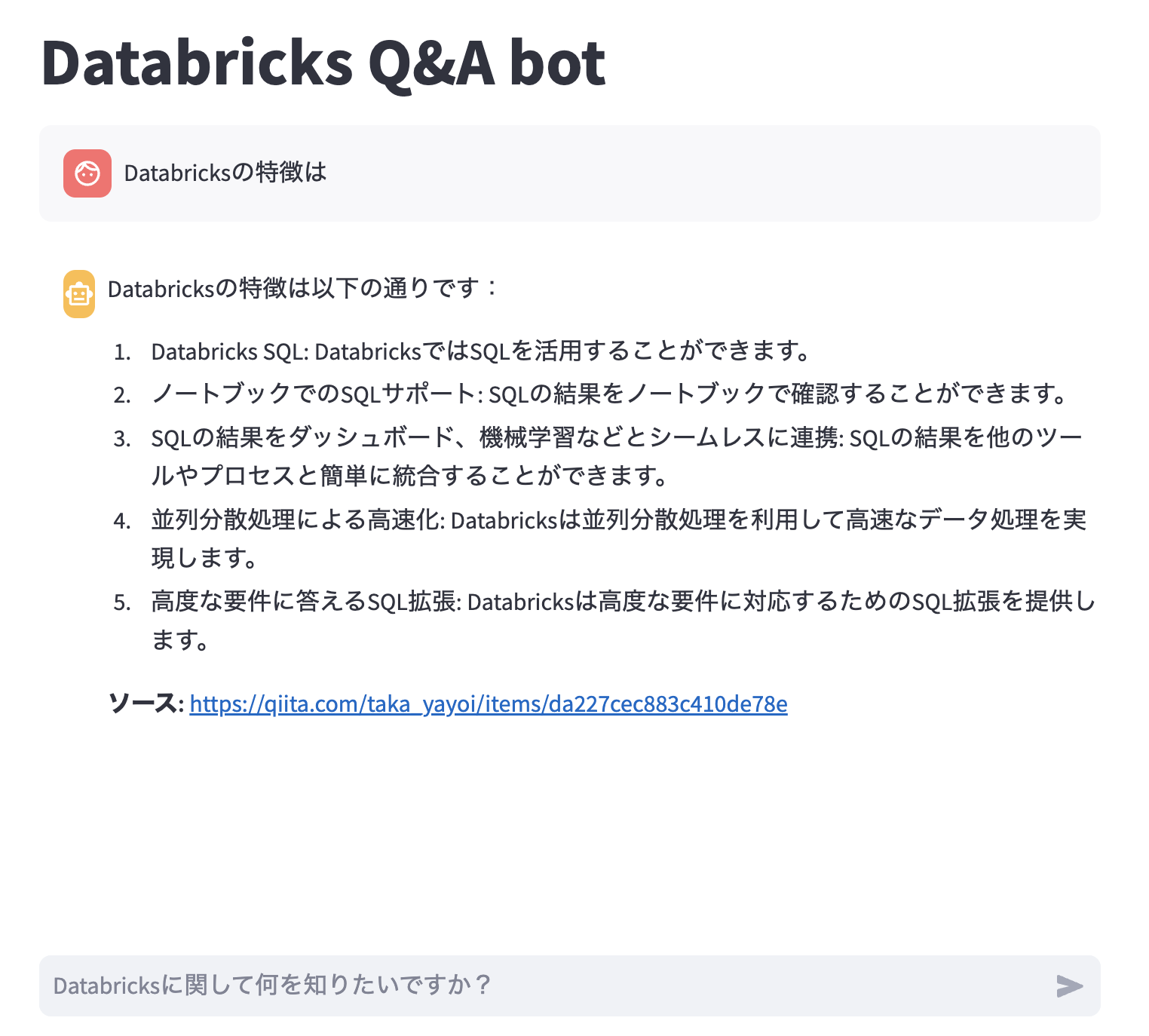
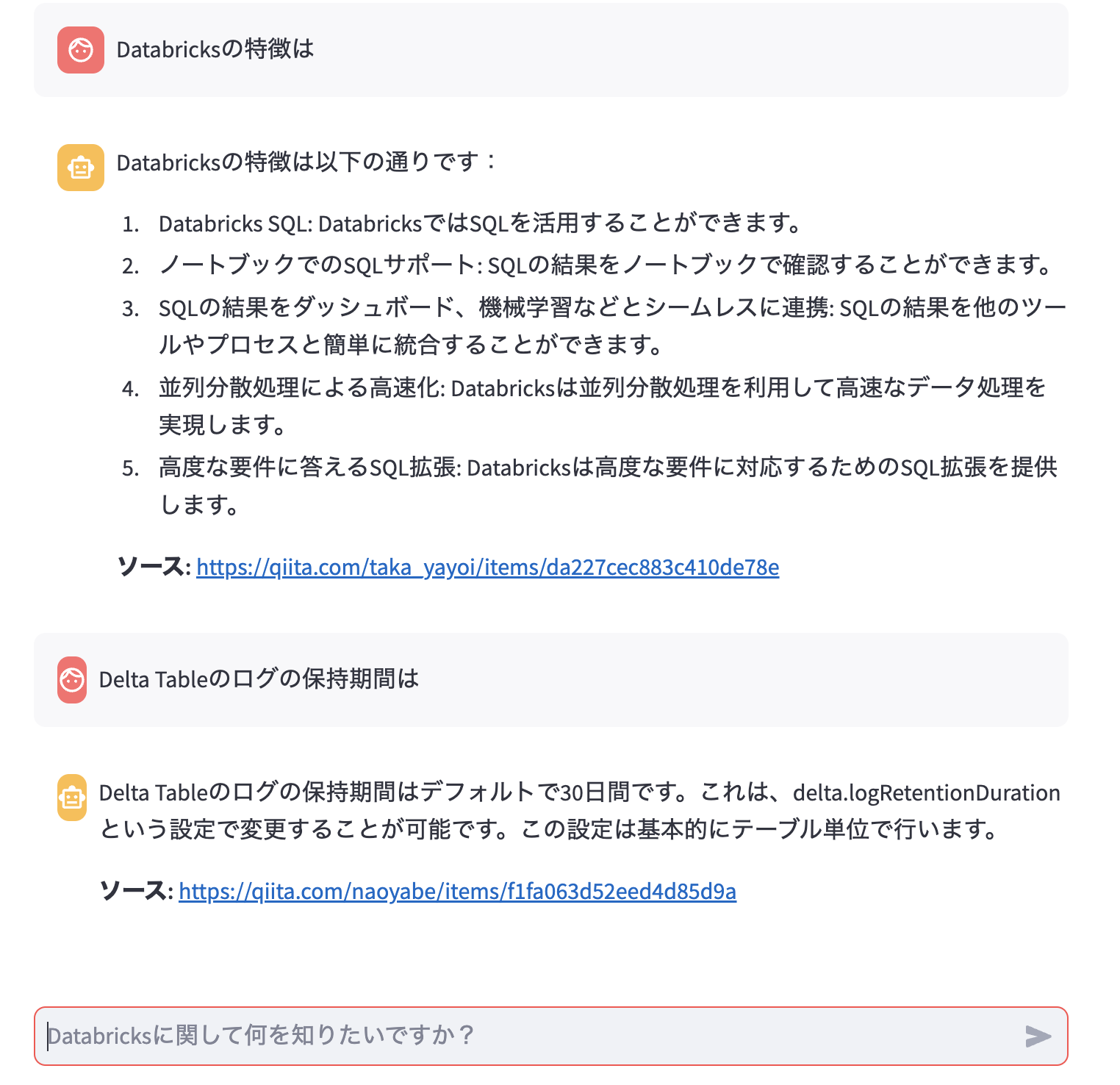
何度か問い合わせを行います。この際にリクエストとレスポンスが推論テーブルに記録されます。
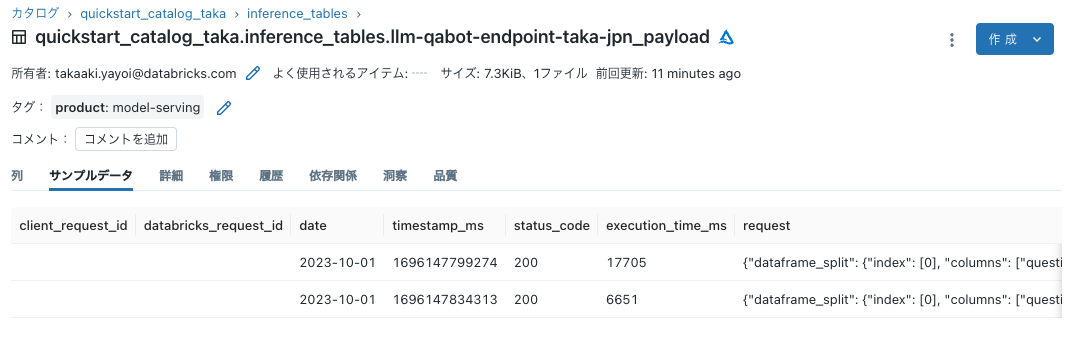
数分経ってからテーブルにアクセスするとレコードを確認できました!
次はパーシングなど行ったり、こちらのノートブックも試してみます。特に大規模言語モデルを運用する際には、どのようなリクエストが来ていて、それに対して大規模言語モデルがどのようなレスポンスをしているのかをモニタリングすることは品質面でも重要なことかと思います。(日本で利用できるようになったら)推論テーブルを是非ご活用ください!