Faster SQL: Adaptive Query Execution in Databricks - The Databricks Blogの翻訳です。
2020年の記事です。
今年の初めに、Databricksでは、Spark 3.0およびDatabricks 7.0で提供された、全く新しいAdaptive Query Executionに関する記事を投稿しました。この記事は技術者からの多大なる興味と議論を引き起こしました。本日、Databricksランタイム、DBR 7.3において、デフォルトでAdaptive Query Executionが有効化されたことを嬉しく思っています。
AQEは、不十分、不正確、鮮度の低いオプティマイザの統計情報によって引き起こされるクエリー実行計画の非効率性、柔軟性の欠如への対策を狙いとした、実行時SQL最適化フレームワークです。我々はAQEの機能拡張を続けており、現状皆様が最もAQEが効率的と考えるであろう特定のユースケースとなります。
シャッフルの最適化
クエリー性能においてSparkのシャッフルが重要な部分となりますが、適切なシャッフルパーティションの数を選ぶことは、Sparkユーザーにとって常に大きな問題となっています。クエリーごとにデータサイズが異なり、1つのクエリーにおいてもステージ間でサイズが異なるため、同じシャッフルパーティション数を使うと、Sparkスケジューラーの利用が非効率的になる小規模のタスクや、ディスクのspillや過大なガーベージコレクション(GC)を引き起こす大規模なタスクを引き起こします。
今では、AQEはクエリーのそれぞれのステージで、map側のシャッフルアウトプットのサイズに基づいてシャッフルパーティション数を自動で調整します。ステージごとにデータサイズは増減しますが、タスクのサイズは大きすぎず、小さすぎず概ね同じものになります。
しかし、AQEはmap側のパーティション数を自動で設定しないことに注意する必要があります。このことは、AQEの機能が完全に動作するようにするためには、SQL設定spark.sql.shuffle.partitionsを最初は比較的大きい値に設定することをお勧めします。あるいは、代替案として、spark.databricks.adaptive.autoOptimizeShuffle.enabledをtrueに設定することで、Databricksの最新機能「シャッフルの自動最適化」を有効化することもできます。
Join戦略の選択
Sparkのオプティマイザにおける最も重要なコストベースの意思決定は、joinのリレーションの推定サイズに基づくjoin戦略の選択です。しかし、この推定は両方の方向で間違うケースがあります。過度の見積もりによる非効率的なjoin戦略、さらに悪いことには、見積もり不足によるアウトオブメモリーエラーになる場合があります。
AQEは、実行時により高速なbroadcast hash joinに切り替えることでトラブルのないソリューションを提供します。
Skew Joinの取り扱い
データの偏り(skew)は、データが均一に分配されておらず、特にsort merge joinにおいて、ボトルネックと深刻なパフォーマンスの悪化を引き起こす一般的な問題です。長時間実行されるタスクは落伍者となり、ステージ全体をスローダウンさせます。さらに、これらの偏ったパーティションにおいてメモリーからディスクにデータが溢れることで、スローダウンの影響を悪化させます。
データの偏りの予測不可能な性質は、クエリーのヒントを用いたとしても、静的なオプティマイザが自動で偏りを取り扱うことを困難にします。実行時の統計情報を収集することで、AQEは実行時にskew joinを検知し、偏りのあるパーティションを小規模なサブパーティション分割することで、クエリー性能におけるネガティブなインパクトを排除します。
AQEクエリープランを理解する
AQEクエリープランにおける主要な違いは、多くの場合で実行が進むにつれてプランが進化するというものです。実行に関する詳細情報を提供するために、いくつかのAQE固有のプランノードが導入されました。さらに、AQEは、初期クエリープラン、最終的クエリープランの両方で表示される新たなクエリープランの文字列フォーマットを使用します。このセクションでは、ユーザーが新たなAQEクエリープランになれるようにするお手伝いをし、クエリーにおけるAQEの効果をどのように特定するのかを説明します。
AdaptiveSparkPlanノード
AQEが適用されたクエリーには、それぞれのクエリー、あるいはサブクエリーのルートノードとして、1つ以上のAdaptiveSparkPlanノードが存在します。実行前、実行中には、isFinalPlanフラグはfalseとなります。クエリーが完了すると、このフラグはtrueに変わり、AdaptiveSparkPlanノードの下のプランはもう変化しません。

CustomShuffleReaderノード
CustomShuffleReaderノードはAQEにおける最適化の鍵となります。これは、シャッフルのmapステージで収集された統計情報に基づいて、シャッフル後のパーティション数を動的に調整します。Spark UIにおいては、ユーザーはシャッフルされたパーティションに適用された最適化を確認するために、ノード上にカーソルをホバーすることができます。
CustomShuffleReaderのフラグがcoalescedになっている場合、AQEはターゲットのパーティションサイズに基づいて小規模のパーティションを検知し、シャッフル後に結合したことを意味します。このノードの詳細では、シャッフルパーティションの数と結合後のパーティションサイズを確認することができます。

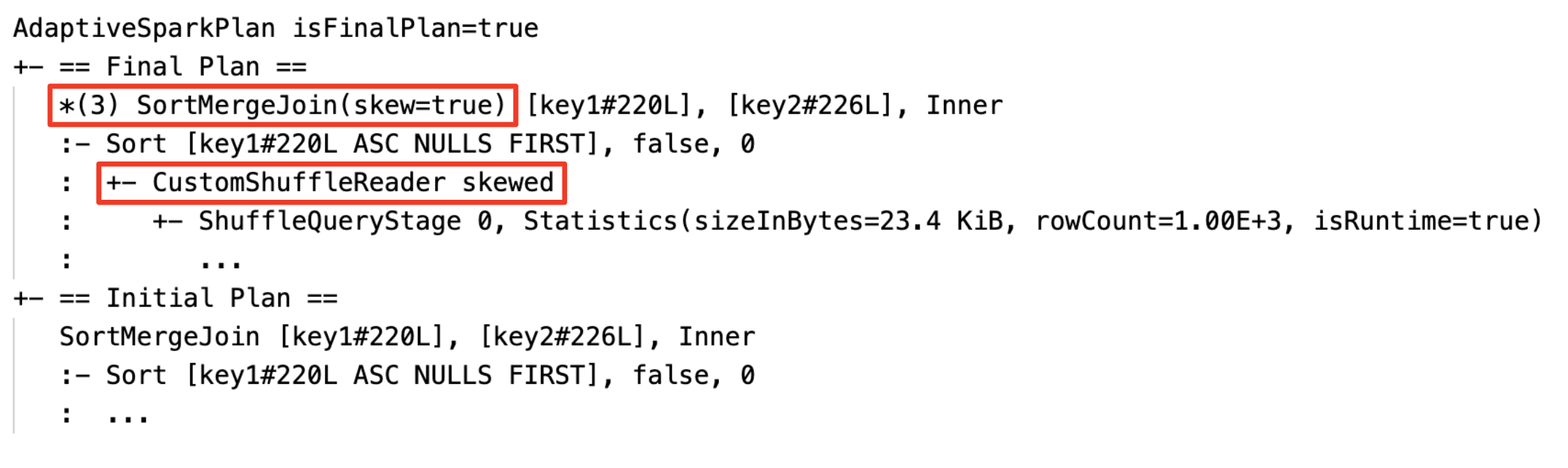
CustomShuffleReaderのフラグがskewedになっている場合、AQEがsort-merge joinオペレーションの前に、1つ以上のパーティションに偏りがあることを検知したこを意味します。このノードの詳細では、偏りのあるパーィションの数と、偏りのあるパーティションから分割された新たなパーティションの数が表示されます。

同時に2つの効果が得られる場合もあります。

Join戦略変更の検知
AQEの最適化前後におけるクエリープランのjoinノードの変化を比較することで、join戦略の変更を特定することができます。DBR 7.3では、AQEクエリープランの文字列には、初期プラン(AQE最適化の適用前のプラン)と現在のプラン、最終的なプランが含まれます。これにより、クエリーに適用されたAQEの最適化を、より詳細に確認できるようになります。以下には、sort-merge joinからbroadcast-hash joinに変更された新規クエリープランの礼を示します。

Spark UIでは、現在のプランのみが表示されます。Spark UIで効果を確認するためには、ユーザーはクエリー実行前と実行後でプランの図を比較する必要があります。

Skew Joinの検知
Skew join最適化の効果は、joinノード名で識別することができます。
Spark UI

クエリープランの文字列
Adaptive Query Executionは、クエリー実行をより効率的なものにするために実行時の統計情報を活用します。他の最適化技術と異なり、最適なシャッフル後のパーティションサイズ、パーティション数を決定し、join戦略を切り替え、skew joinをうまく取り扱います。AQEの詳細については、Spark + AIサミットのAdaptive Query Execution: Speeding Up Spark SQL at Runtime、およびAQEユーザーガイドをご覧ください。Databricksランタイム7.3以降でAQEの新機能を体験してみてください。