はじめに
ちょっと暇つぶしにpythonの練習がてらに様々なソートアルゴリズムを実装してる最中に思いついて実装してみた無駄な発想です
バブルソートを使って標準正規分布に基づく乱数っぽいのを生成する
バブルソートの実装を行い、それぞれランダムで生成したデータをソートさせ、平均回数を求めてている時に、ソート回数は一様な標準正規分布に基づくのではないかと誰しもが当たり前に思いつくことを用いて、一様なランダム数から標準正規分布に基づく乱数を生成するプログラムを作った。
そのプログラムは有用なの?
pythonのベクトル演算numpyの
R = np.random.rand()
を使わなくても標準正規分布に基づく乱数を生成できる。
randomでも
random.normalvariate(mu, sigma)
を用いることによって正規分布に基づく乱数生成できます。
つまりpythonにnumpyを入れなくても標準正規分布に基づく乱数を生成できる有用的でない発想です。
本当に有用的ではないです。
以下プログラム
.py
# -*- coding: utf-8 -*-
import random
import matplotlib.pyplot as plt
def bubble_sort(data,data_num):
count = 0
for i in range(0,data_num):
for j in range(data_num-1,i,-1):
if data[j] <= data[j-1]:
count += 1
data[j] , data[j-1] = data[j-1] , data[j]
return count
if __name__ == '__main__':
t = 10 #それぞれ各バブルソートお行う乱数の数
n = t*(t-1)/2 #nの範囲で標準正規分布が作成される
y = [0]*n #それぞれバブルソートを行なった時のソートにかかった回数を格納
data = [] #毎回t個のソートするデータ
for j in range(0,100000):
count = 0
for i in range(0,t):
data.append(random.randint(1,100))
count = bubble_sort(data,t)
y[count] = y[count] + 1
del data[:] #データの初期化
plt.plot(y,marker="o")
plt.show()
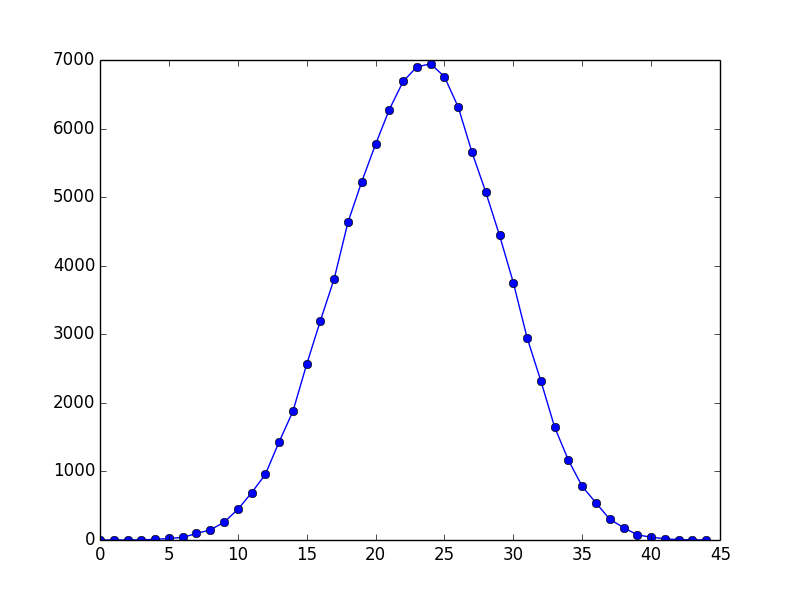
結果について
今回は10万回10個の乱数リストをソートし、それぞれソートにかかった回数を新たに生成された乱数として捉え、数えてグラフにしました。グラフから見て取れるように標準正規分布っぽい感じがします。n個のデータをバブルソートでソートを行なった時の最大ソート回数はn(n-1)/2であるので、今回はそれぞれ行うソートデータが10個なので10*(10-1)/2 = 45という計算になります。何故標準正規分布っぽくなるかは、ソート回数に属する乱数のパターンであると考えられます。
まとめ
ただの自己満足のプログラムです。