はじめに
アイデミーのAIアプリ開発コースで学習した総仕上げとして、バナナの食べ頃判定アプリを作成してみました。
きっかけは、私の1歳になる息子がバナナが大好物なのでスーパー等で買うことが多いのですが、売っているバナナは見た目はキレイにもかかわらず、食べ頃までは数日かかることが多いという印象を以前から持っていたことです。
食べ頃というのは人によっても異なり、これが正解というのを決めるのは難しいと思うのですが、調べてみたところ、バナナの皮にシュガースポットという茶色の斑点が出てくると糖度が増してより美味しくなるようなので、今回はこれを基準に作成しています。
実行環境
python-3.9.7
Visual Studio Code
Google Colaboratory
1.画像収集
#icrawlerのインストール
!pip install icrawler
from icrawler.builtin import BingImageCrawler
#ダウンロードするキーワード
search_word = "バナナ "
crawler = BingImageCrawler(storage={'root_dir':"/content/drive/MyDrive/成果物/"+search_word})
#ダウンロード画像は最大300枚
crawler.crawl(keyword=search_word, max_num=300)
チューターの方に教えていただき、icrawlerを利用しました。このおかげで画像収集の手間と時間が劇的に削減できたと思います。
使い方は、キーワードを「バナナ 青い」、「バナナ 食べ頃」等に変えながら実行するだけです。今回はバナナの食べ頃を成熟の程度から4つのカテゴリー(「まだしばらく待ってください!」、「食べれますが、数日待てばもっと甘くなりますよ!」、「今がちょうど食べ頃です!」、「食べ時を過ぎた可能性が高いので注意してください!」)に分けて判定したいので、最終的に4つのフォルダに画像を分類しました。
2.画像の選別
バナナ以外のものが多数入っている画像やバナナとあまり関係ない画像等も収集されるので、それらを削除しました。また、「バナナ 食べ頃」で収集した画像の中に明らかに食べ頃ではない画像も含まれているため、それらを適切な分類のフォルダに移動させ、最終的に各フォルダの画像数は60~120枚程度になりました。
3.必要なモジュールのインポートと画像データの読み込み
import os#osモジュール(os機能がpythonで扱えるようにする)
import cv2#画像や動画を処理するオープンライブラリ
import numpy as np#python拡張モジュール
import matplotlib.pyplot as plt#グラフ可視化
from tensorflow.keras.utils import to_categorical#正解ラベルをone-hotベクトルで求める
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input#全結合層、過学習予防、平滑化、インプット
from tensorflow.keras.applications.vgg16 import VGG16#学習済モデル
from tensorflow.keras.models import Model, Sequential#線形モデル
from tensorflow.keras import optimizers#最適化関数
上記のコードで今回のバナナ判定アプリに必要なモジュールをインポートします。
今回はVGG16を使用して精度の良いモデルを構築します。
#画像の格納
img_1 = "/content/drive/MyDrive/成果物/バナナ青い/"
img_2 = "/content/drive/MyDrive/成果物/バナナもう少し/"
img_3 = "/content/drive/MyDrive/成果物/バナナ食べ頃/"
img_4 = "/content/drive/MyDrive/成果物/バナナ黒い/"
image_size = 200#画像サイズを指定
#os.listdir() で指定したファイルを取得
path_1 = os.listdir(img_1)
path_2 = os.listdir(img_2)
path_3 = os.listdir(img_3)
path_4 = os.listdir(img_4)
#画像を格納するリスト作成
img_1_list = []
img_2_list = []
img_3_list = []
img_4_list = []
for i in range(len(path_1)):
#print(drive_1+ path_1[i])
# "/content/drive/MyDrive/成果物/バナナ青い/000001 (1).jpg"
img = cv2.imread(img_1+ path_1[i])#画像を読み込む
img = cv2.resize(img,(image_size,image_size))#画像をリサイズする
img_1_list.append(img)#画像配列に画像を加える
for i in range(len(path_2)):
img = cv2.imread(img_2+ path_2[i])
img = cv2.resize(img,(image_size,image_size))
img_2_list.append(img)
for i in range(len(path_3)):
img = cv2.imread(img_3+ path_3[i])
img = cv2.resize(img,(image_size,image_size))
img_3_list.append(img)
for i in range(len(path_4)):
img = cv2.imread(img_4+ path_4[i])
img = cv2.resize(img,(image_size,image_size))
img_4_list.append(img)
#np.arrayでXに学習画像、yに正解ラベルを代入
X = np.array(img_1_list + img_2_list + img_3_list + img_4_list)
#正解ラベルの作成
y = np.array([0]*len(img_1_list) + [1]*len(img_2_list) + [2]*len(img_3_list) + [3]*len(img_4_list))
label_num = list(set(y))
#配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#学習データと検証データを用意
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#正解ラベルをone-hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
格納されている各クラスのフォルダごとの画像を読み込みます。
その際、画像サイズを縦横200X200になるように整形します。
格納した画像をnumpy配列に変換し、シャッフルします。その後、データを学習用80%、検証用20%に分割します。
また、教師ラベルは、教師ラベルに対応する要素のみ1で他は0であるOne-hotベクトルに整形して学習させます。
#転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 4.モデルの構築
#モデルの定義
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(512, activation="relu"))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dense(64, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(4, activation='softmax'))
#VGG16とtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#VGG16による特徴抽出部分の重みを15層までに固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:15]:
layer.trainable = False
#訓練プロセスを設定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
VGG16というのは,「ImageNet」と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルで、オックスフォード大学の研究グループが提案し、2014年のILSVRC(ImageNet Large Scale Visual Recognition Challenge)で好成績を収めているものです。
VGG16は、畳み込み13層+全結合層3層=16層のニューラルネットワークですが、最後の全結合層は使わずに途中までの層を特徴抽出のための層として使うことで、転移学習に用いることができます。
5.学習および精度の評価
#学習の実行
#グラフ(可視化)用コード
history = model.fit(X_train, y_train, batch_size=32, epochs=100, verbose=1, validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()

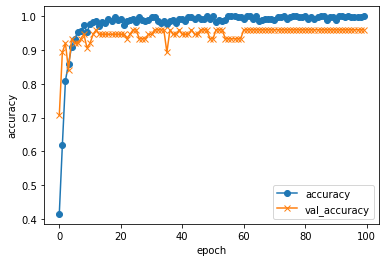
正解率96%弱と思ったより良い結果が出ましたが、「今がちょうど食べ頃です!」を「食べれますが、数日待てばもっと甘くなりますよ!」、「食べ時を過ぎた可能性が高いので注意してください!」の2つの判定に間違うことがあるようです。

6.動作の確認
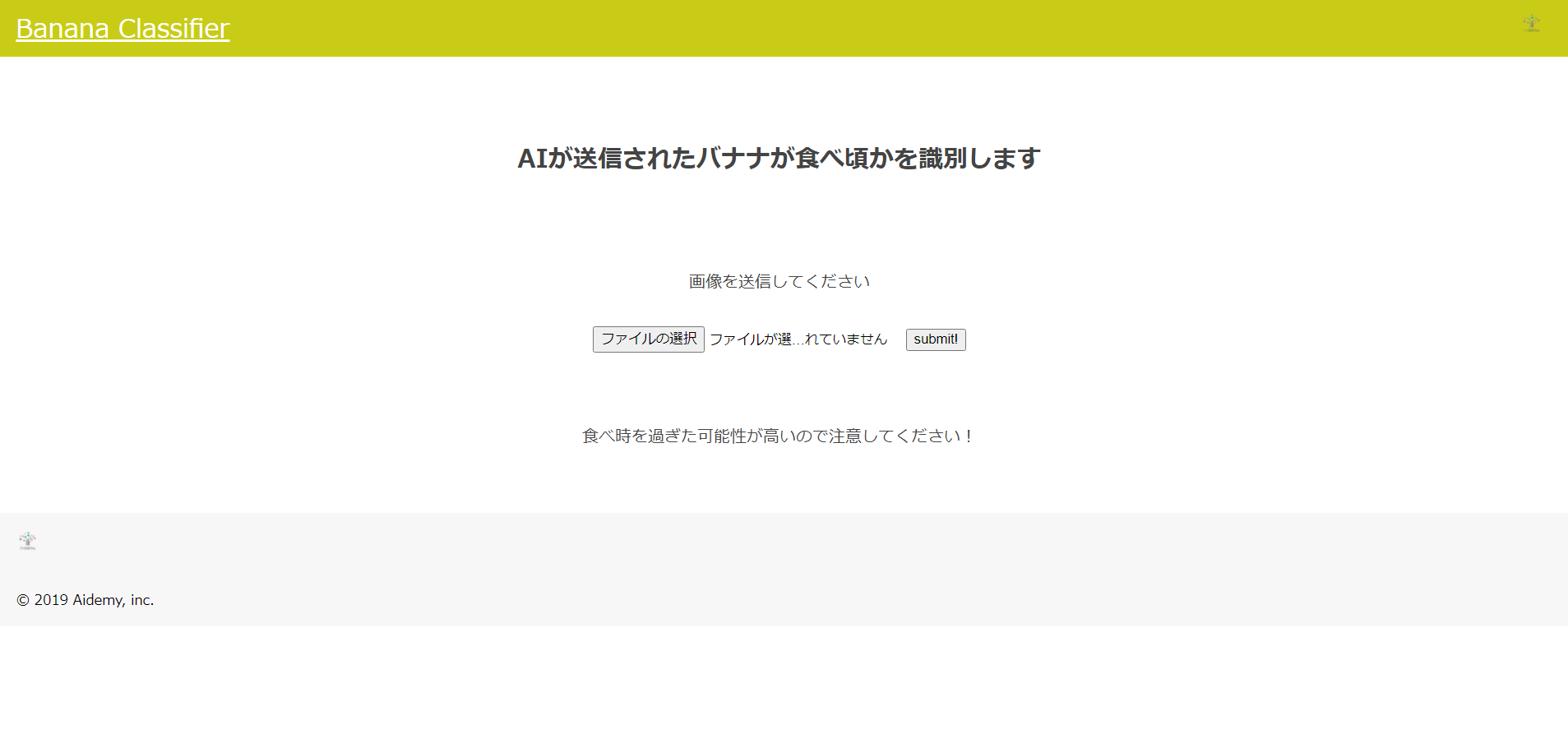
家にあった下のバナナの写真で動作を確認したところ、「食べ時を過ぎた可能性が高いので注意してください!」と判定されました。実際には中身はキレイな色で食べ頃だったので、やはりこのような黄色と茶色が混ざった皮の色だと判定が難しいようです。

7.考察
上記の実行結果では正解率96%弱と比較的良い数字が出ていますが、実行するたびに正解率が数パーセント違ってくるので、画像の枚数を増やしたり(特に「今がちょうど食べ頃です!」の画像を増やす)、画像のサイズを上げたり、モデルの層の数やエポック数の調整を行ったりしながら、安定して良い結果が出るよう改善する必要がありそうです。
また、今回VGG16を使用しましたが、2014年時点のものなので、さらに良い成績を収めているモデルを使用することで精度向上が見込めるのではないかと考えています。
8.今後の展望
今回はチューターさんに助けていただきながら何とかアプリの完成までたどり着きましたが、しっかり復習して自分のものにしたいと思います。
以前からプログラミングには興味を持っていましたが、自分の意志でアイデミーの講座受講を決め、3ヵ月間必死に取り組んだことで、やっと本格的にスタートをきることができたと感じています。
世の中に必要とされる能力を身に着けるまではまだ時間がかかりそうですが、いつか社会に貢献することができるよう努力を続けていきたいです。
9.参考文献