UniHCP: A Unified Model for Human-Centric Perceptions
概要
UniHCPは、人物中心の認識(姿勢推定、人間の解析、歩行者検出、人物再識別など)を一つのモデルで統一的に処理する新しいフレームワークを提案している.このモデルは、33の人物中心のデータセットで大規模な共同学習を行い、単一のビジョントランスフォーマーアーキテクチャを使用している.これにより、特定のタスクに適応する際に、新しい最先端のパフォーマンスを達成し、専門のモデルよりも優れた結果を示している.
物体検出がセグメントや姿勢推定に、姿勢推定がメッシュや動作予測に...などタスクが高度になる程、他のタスクと組み合わさっていくようなものだと思うので、それらを一つにまとめられると強い。
従来手法との比較
従来の人物中心の認識タスクは、それぞれが異なるセマンティック情報に焦点を当てていたが、すべてが人間の体の基本構造に依存している.以前の研究では、これらのタスクの同質性を利用して、共通のニューラルネットワークを使用して共同でトレーニングを行う試みがあったが、全ての人物中心のタスクを統一的に扱う一般的なモデルの設計は行われていなかった.UniHCPは、このギャップを埋めるために提案されたものである.
新規性
UniHCPの新規性は以下の点にある:
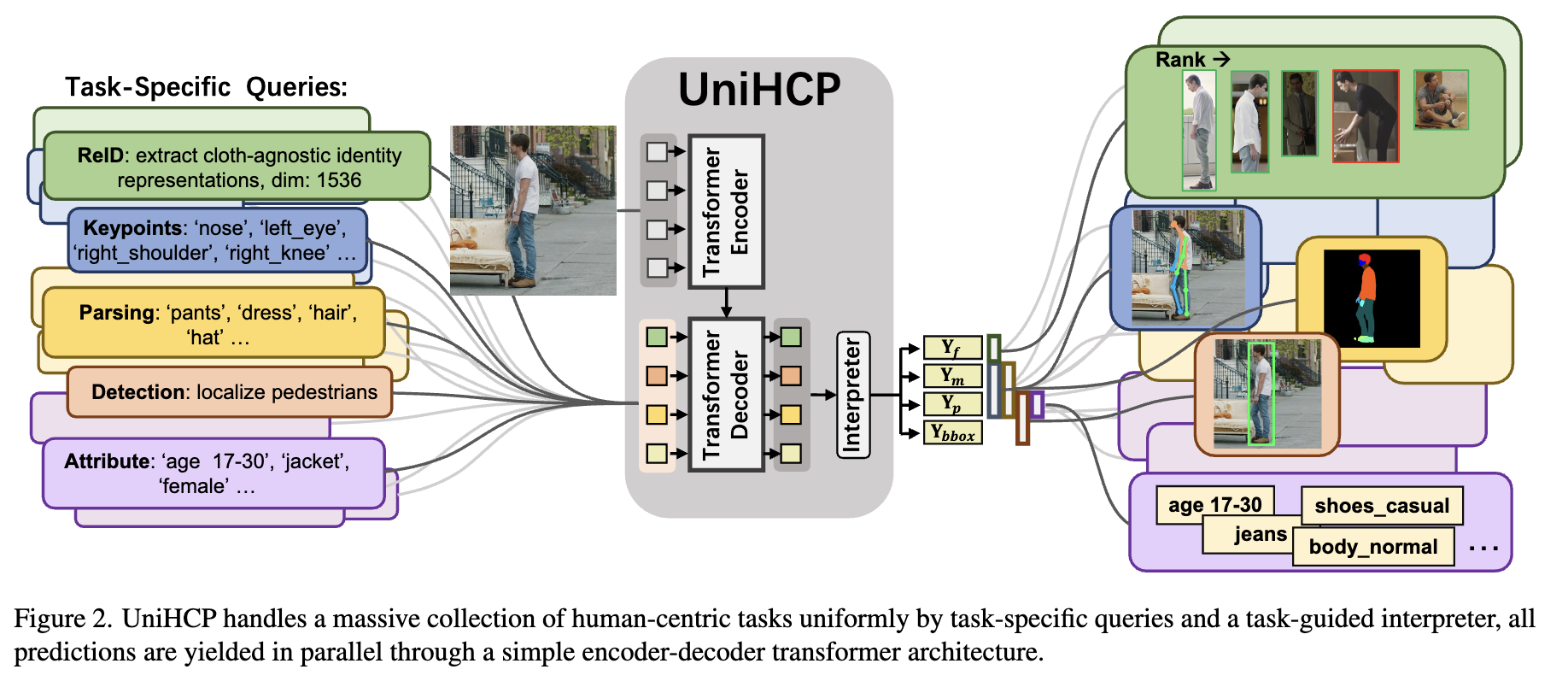
- 統一タスククエリ: すべてのデータセットで共有されるタスククエリを定義し、異なるタスクとデータセット間で共有可能なタスクガイドインタープリターを使用
- エンコーダ・デコーダアーキテクチャ: 単純なビジョントランスフォーマーを用いたエンコーダ・デコーダアーキテクチャを採用し、すべての人物中心のタスクとデータセットで汎用的な知識を抽出
- 大規模共同学習: 33のラベル付き人物中心のデータセットで大規模な共同学習を行い、異なるタスク間での知識共有を最大化
方法論
- タスク非依存エンコーダ: 異なる解像度の入力画像に対応するために、共有可能な学習済みポジショナルエンベディングを使用
- タスク特定クエリによるデコーダ: タスククエリを用いて、エンコーダの特徴からタスク特定の情報を抽出
- タスクガイドインタープリター: 各タスクに応じた出力ユニットを生成し、タスクごとの知識を共有
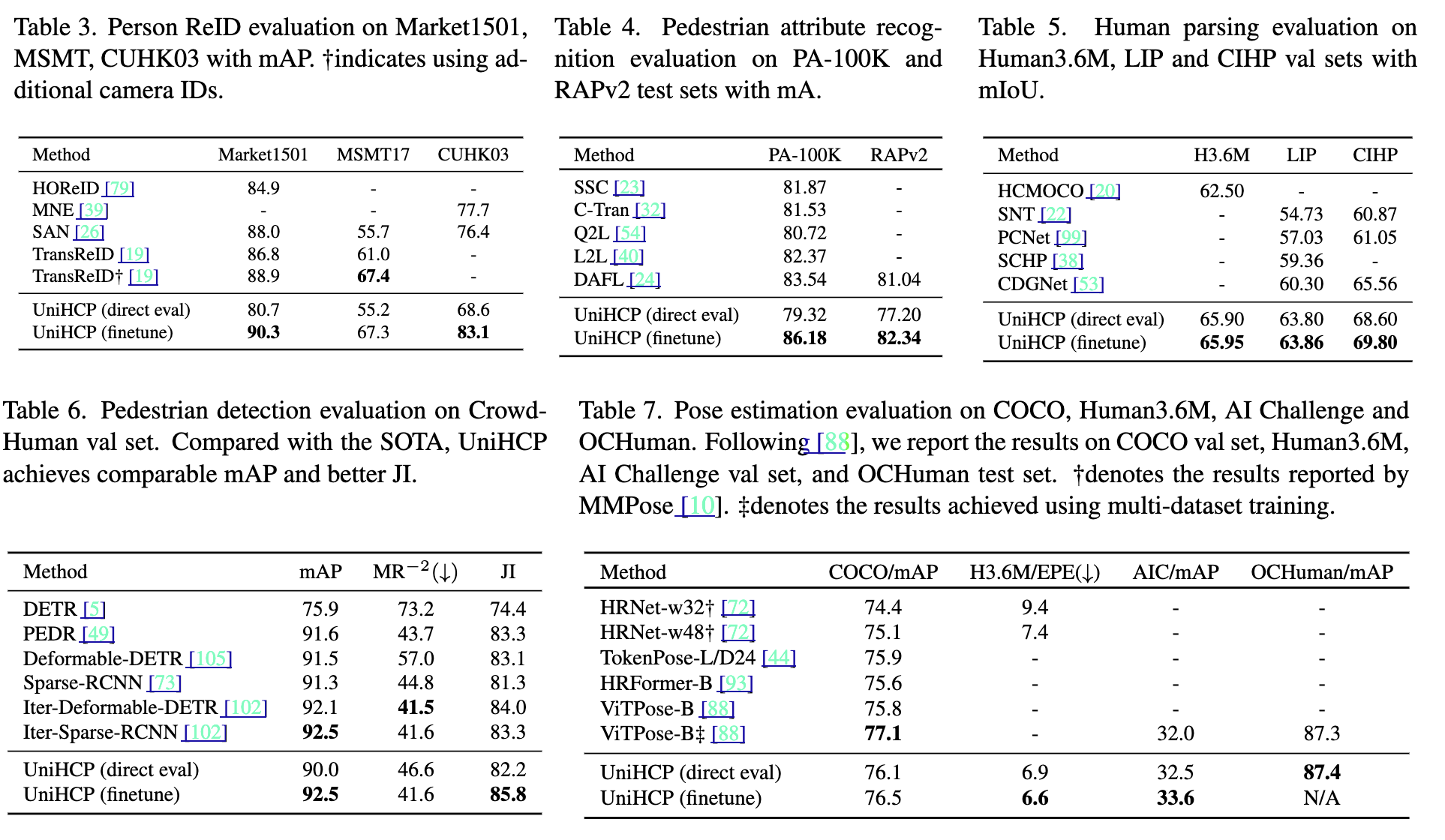
結果と評価
複数の人物中心のタスクベンチマークにおいて強力なベースラインを上回る性能を示している.