やりたいこと
Amazonやニュースサイトのランキングをタブで一括表示できるアプリがあると便利だな、と考えました。
けれど探しても見当たらないので、自分で作りました。
以下からダウンロードできますので是非使ってみてください(Androidのみ)
https://play.google.com/store/apps/details?id=atellieryotta.unsmart_news
サーバ側はPython+Selenium(headless)で一時間ごとに各サイトをスクレーピングし、サーバ上に保存、モバイルアプリ側は今はやりのflutterで構築し、そのデータを読み込んでいます。
今回はサーバ側の内容をご紹介します。
基本の手順(Amazonの本ランキング取得)
あらかじめ取得するサイトの構造が分かっているなら、XPATHによるスクレーピングが便利です。
XPATHを調べるにはChromeを使うのが簡単です。
今回はAmazonの本のランキングページを開き、本のタイトルのところで右クリック→「検証」を選択すると、
右側に開発者用のメニューが表示されるので、右クリックから→「Copy」→「Copy XPATH」を選択すると、クリップボートにXPATHがコピーされます。
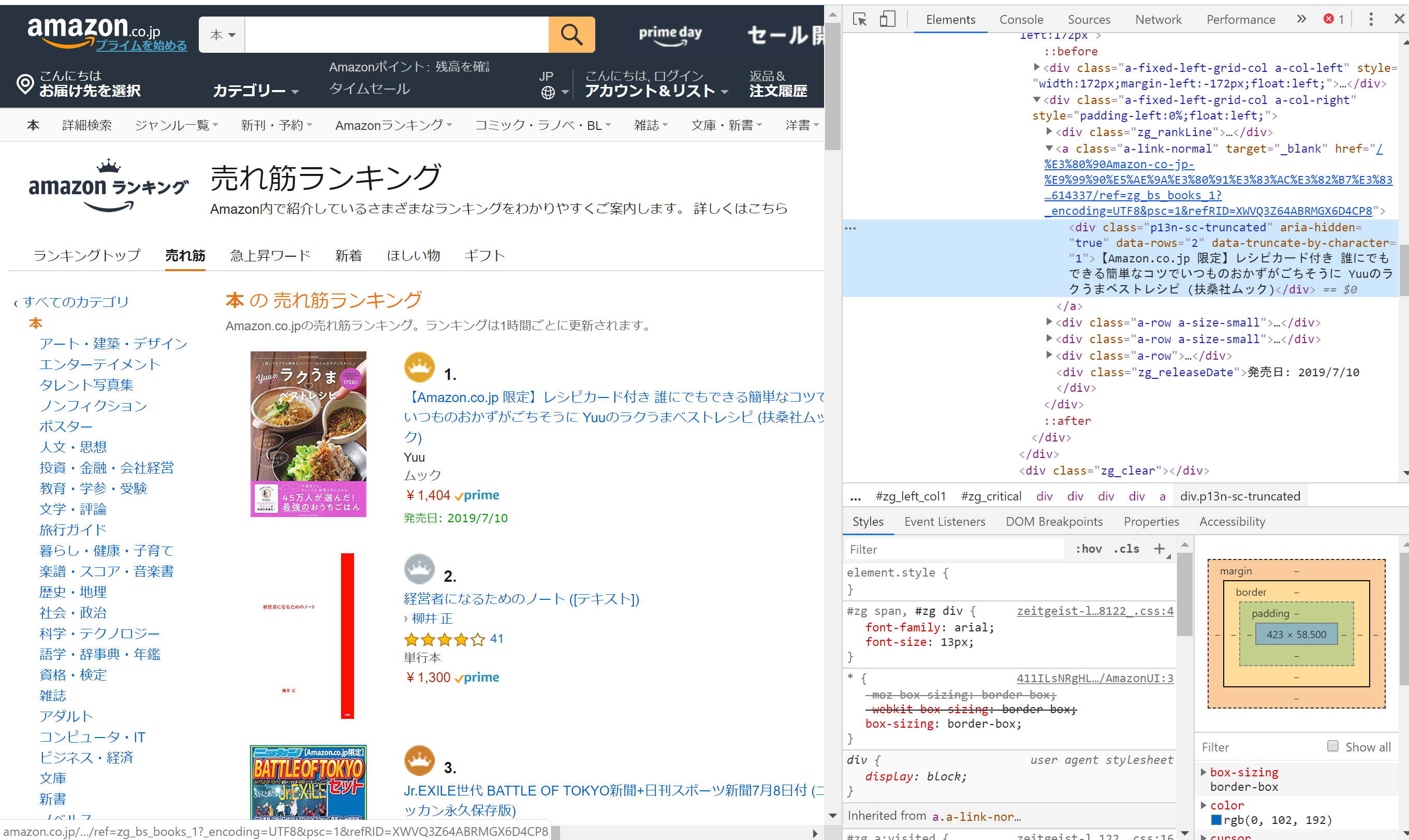
一位と二位について取得するとそれぞれ以下の通りであることがわかります。
//[@id="zg_critical"]/div[1]/div[1]/div/div[2]/a/div
//[@id="zg_critical"]/div[2]/div[1]/div/div[2]/a/div
一つ目のdivの[]内を1~10に変えてやればよさそうです。
ただここにトラップがあり、ランキング1~3位と4位以降では@id以降が変わっています。
4位以降は以下のXPATHを取る必要があります。(iは可変)
//*[@id="zg_nonCritical"]/div[{i}]/div[1]/div/div[2]/a/div
サイトによって仕様は異なるので何度かトライアンドエラーしながらXPATHを突き詰めていく必要があります。
タイトルに加えて、リンク先のURLやサムネイル画像のURLについても同様の手順でXPATHを確認できます。
最終的には以下のプログラムでランキングをスクレーピングできました。
(スクレーピングの際はサーバに過負荷をかけないようにご注意ください)
import sys,os
import requests
import bs4
import lxml.html
import shutil
fpath = "/tmp/hoge.tsv"
url = 'https://www.amazon.co.jp/gp/bestsellers/books'
url_base = 'https://www.amazon.co.jp/'
response = requests.get(url)
html = lxml.html.fromstring(response.content)
f = open(fpath, mode="w");
for i in range(1,4): # rank 1~3
xpath1 = f'//*[@id="zg_critical"]/div[{i}]/div[1]/div/div[2]/a/div' # text,
xpath2 = f'//*[@id="zg_critical"]/div[{i}]/div[1]/div/div[2]/a' # link
xpath3 = f'//*[@id="zg_critical"]/div[{i}]/div[1]/div/div[1]/a/img' # image
link1 = html.xpath(xpath1)
link2 = html.xpath(xpath2)
link3 = html.xpath(xpath3)
text = link1[0].text.strip()
href = link2[0].get("href").strip() # 空白が入り込むのでstrip
image = link3[0].get("src").strip()
f.write(f'{i} {url_base}{href} {text} {image}\n')
for i in range(1,8): # rank 4~10
xpath1 = f'//*[@id="zg_nonCritical"]/div[{i}]/div[1]/div/div[2]/a/div' # text,
xpath2 = f'//*[@id="zg_nonCritical"]/div[{i}]/div[1]/div/div[2]/a' # link
xpath3 = f'//*[@id="zg_nonCritical"]/div[{i}]/div[1]/div/div[1]/a/img' # image
link1 = html.xpath(xpath1)
link2 = html.xpath(xpath2)
link3 = html.xpath(xpath3)
text = link1[0].text.strip()
href = link2[0].get("href").strip()
image = link3[0].get("src").strip()
j = i+3
f.write(f'{j} {url_base}{href} {text} {image}\n')
f.close()
これを実行することで以下のような出力が得られます。
タブ区切りで、ランキング、リンク先URL、タイトル、サムネイルURLをダンプしています。
1 https://www.amazon.co.jp//%E3%80%90Amazon-co-jp-%E9%99%90%E5%AE%9A%E3%80%91%E3%83%AC%E3%82%B7%E3%83%94%E3%82%AB%E3%83%BC%E3%83%89%E4%BB%98%E3%81%8D-%E8%AA%B0%E3%81%AB%E3%81%A7%E3%82%82%E3%81%A7%E3%81%8D%E3%82%8B%E7%B0%A1%E5%8D%98%E3%81%AA%E3%82%B3%E3%83%84%E3%81%A7%E3%81%84%E3%81%A4%E3%82%82%E3%81%AE%E3%81%8A%E3%81%8B%E3%81%9A%E3%81%8C%E3%81%94%E3%81%A1%E3%81%9D%E3%81%86%E3%81%AB-Yuu%E3%81%AE%E3%83%A9%E3%82%AF%E3%81%86%E3%81%BE%E3%83%99%E3%82%B9%E3%83%88%E3%83%AC%E3%82%B7%E3%83%94-%E6%89%B6%E6%A1%91%E7%A4%BE%E3%83%A0%E3%83%83%E3%82%AF/dp/4594614337?_encoding=UTF8&psc=1 【Amazon.co.jp 限定】レシピカード付き 誰にでもできる簡単なコツでいつものおかずがご ちそうに Yuuのラクうまベストレシピ (扶桑社ムック) https://images-na.ssl-images-amazon.com/images/I/81sIUM7QXoL._AC_UL160_SR160,160_.jpg
2 https://www.amazon.co.jp//%E7%B5%8C%E5%96%B6%E8%80%85%E3%81%AB%E3%81%AA%E3%82%8B%E3%81%9F%E3%82%81%E3%81%AE%E3%83%8E%E3%83%BC%E3%83%88-%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88-%E6%9F%B3%E4%BA%95-%E6%AD%A3/dp/4569826954?_encoding=UTF8&psc=1 経営者になるためのノ ート ([テキスト]) https://images-na.ssl-images-amazon.com/images/I/61aHoJlmwoL._AC_UL160_SR160,160_.jpg
3 https://www.amazon.co.jp//Jr-EXILE%E4%B8%96%E4%BB%A3-BATTLE-TOKYO%E6%96%B0%E8%81%9E-%E6%97%A5%E5%88%8A%E3%82%B9%E3%83%9D%E3%83%BC%E3%83%84%E6%96%B0%E8%81%9E7%E6%9C%888%E6%97%A5%E4%BB%98-%E3%83%8B%E3%83%83%E3%82%AB%E3%83%B3%E6%B0%B8%E4%B9%85%E4%BF%9D%E5%AD%98%E7%89%88/dp/B07TNVXLZH?_encoding=UTF8&psc=1 Jr.EXILE世代 BATTLE OF TOKYO新聞+日刊スポーツ新聞7月8日付 (ニッカン永久保存版) https://images-na.ssl-images-amazon.com/images/I/911FzCntefL._AC_UL160_SR160,160_.jpg
4 https://www.amazon.co.jp//%E5%A4%8F%E3%81%AE%E9%A8%8E%E5%A3%AB-%E7%99%BE%E7%94%B0-%E5%B0%9A%E6%A8%B9/dp/4103364149?_encoding=UTF8&psc=1 夏の騎士 https://images-na.ssl-images-amazon.com/images/I/81JqVie4p8L._AC_UL160_SR160,160_.jpg
5 https://www.amazon.co.jp//%E3%81%8F%E3%81%B3%E3%82%8C%E6%AF%8D%E3%81%A1%E3%82%83%E3%82%93%E3%81%AE%E3%82%86%E3%82%8B%E3%82%81%E3%82%8B%E3%82%AB%E3%83%A9%E3%83%80-DVD%E4%BB%98%E3%81%8D-%E6%89%B6%E6%A1%91%E7%A4%BE%E3%83%A0%E3%83%83%E3%82%AF-%E6%9D%91%E7%94%B0-%E5%8F%8B%E7%BE%8E%E5%AD%90/dp/4594614248?_encoding=UTF8&psc=1 くびれ母ちゃんのゆるめるカラダ DVD付き (扶桑社ムック) https://images-na.ssl-images-amazon.com/images/I/81kx4Dcvo4L._AC_UL160_SR160,160_.jpg
6 https://www.amazon.co.jp//OAD%E4%BB%98%E3%81%8D-%E8%BB%A2%E7%94%9F%E3%81%97%E3%81%9F%E3%82%89%E3%82%B9%E3%83%A9%E3%82%A4%E3%83%A0%E3%81%A0%E3%81%A3%E3%81%9F%E4%BB%B6-12-%E9%99%90%E5%AE%9A%E7%89%88-%E8%AC%9B%E8%AB%87%E7%A4%BE%E3%82%AD%E3%83%A3%E3%83%A9%E3%82%AF%E3%82%BF%E3%83%BC%E3%82%BA%E3%83%A9%E3%82%A4%E3%83%84/dp/406513935X?_encoding=UTF8&psc=1 OAD付き 転生したらスライムだった件(12)限 定版 (講談社キャラクターズライツ) https://images-na.ssl-images-amazon.com/images/I/51xlRxe7ykL._AC_UL160_SR160,160_.jpg
7 https://www.amazon.co.jp//1%E6%97%A53%E5%88%86%E8%A6%8B%E3%82%8B%E3%81%A0%E3%81%91%E3%81%A7%E3%81%90%E3%82%93%E3%81%90%E3%82%93%E7%9B%AE%E3%81%8C%E3%82%88%E3%81%8F%E3%81%AA%E3%82%8B-%E3%82%AC%E3%83%9C%E3%83%BC%E3%83%AB%E3%83%BB%E3%82%A2%E3%82%A4-%E5%B9%B3%E6%9D%BE-%E9%A1%9E/dp/4797399694?_encoding=UTF8&psc=1 1日3分見るだけでぐんぐん目がよくなる! ガボール・アイ https://images-na.ssl-images-amazon.com/images/I/71k2FysEGIL._AC_UL160_SR160,160_.jpg
8 https://www.amazon.co.jp//%E6%97%A5%E5%90%91%E5%9D%8246-1st%E3%82%B0%E3%83%AB%E3%83%BC%E3%83%97%E5%86%99%E7%9C%9F%E9%9B%86%E3%80%8E%E3%82%BF%E3%82%A4%E3%83%88%E3%83%AB%E6%9C%AA%E5%AE%9A%E3%80%8F/dp/4103527811?_encoding=UTF8&psc=1 日向坂46 1stグループ写真集 『タイトル未定』 https://images-na.ssl-images-amazon.com/images/I/911IeCcqO8L._AC_UL160_SR160,107_.jpg
9 https://www.amazon.co.jp//%E6%98%9F%E9%87%8E%E6%BA%90-%E3%81%B5%E3%81%9F%E3%82%8A%E3%81%8D%E3%82%8A%E3%81%A7%E8%A9%B1%E3%81%9D%E3%81%86-AERA%E3%83%A0%E3%83%83%E3%82%AF/dp/4022792337?_encoding=UTF8&psc=1 星野源 ふたりきりで話そう (AERAムック) https://images-na.ssl-images-amazon.com/images/I/61RXvslphbL._AC_UL160_SR160,160_.jpg
10 https://www.amazon.co.jp//%E3%83%8B%E3%83%A5%E3%83%BC%E3%82%BF%E3%82%A4%E3%83%97%E3%81%AE%E6%99%82%E4%BB%A3-%E6%96%B0%E6%99%82%E4%BB%A3%E3%82%92%E7%94%9F%E3%81%8D%E6%8A%9C%E3%81%8F24%E3%81%AE%E6%80%9D%E8%80%83%E3%83%BB%E8%A1%8C%E5%8B%95%E6%A7%98%E5%BC%8F-%E5%B1%B1%E5%8F%A3-%E5%91%A8/dp/447810834X?_encoding=UTF8&psc=1 ニュータイプの時代 新時代を生き抜く24の思考・行動様式 https://images-na.ssl-images-amazon.com/images/I/81bUaj2cn%2BL._AC_UL160_SR160,160_.jpg
動的生成されるコンテンツへの対応(日刊スポーツ)
だいたいのサイトは上記のやり方でスクレーピングできますが、動的に生成されるコンテンツがあるサイトはSeleniumのheadlessブラウザを利用することで、動的に生成されたコンテンツを取得することができます。
以下のような、ただURLをダンプするだけのプログラムを作っておくと便利です(ここだけrubyですが、訳は聞かないでください。。。)
※あらかじめLinux版のgoogle-chromeとchromedriverの準備が必要となります。
require 'selenium-webdriver'
url = ARGV[0]
out = ARGV[1]
ua = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36"
caps = Selenium::WebDriver::Remote::Capabilities.chrome("chromeOptions" => {binary: '/usr/bin/google-chrome', args: ["--headless", "--disable-gpu", "--user-agent=#{ua}", "window-size=1280x800"]})
$driver = Selenium::WebDriver.for :chrome, desired_capabilities: caps
$driver.manage.timeouts.implicit_wait = 30
$driver.get url
html = $driver.page_source
File.open(out, "w") do |text|
text.puts(html)
end
日刊スポーツのサイトを例にとると以下のようになります。
import sys,os
import requests
import bs4
import lxml.html
import shutil
fpath = /tmp/hoge.tsv
url = 'https://www.nikkansports.com/ranking/#total'
url_base = ''
### use chromedriver
tmp = "nikkan.tmp"
os.system(f"ruby chrome_helper.rb {url} {tmp}")
f = open(tmp)
content = f.read()
html = lxml.html.fromstring(content)
## あとはいつもの
f = open(fpath, mode="w");
for i in range(1,11):
xpath = f'//*[@id="sougou"]/ul/li[{i}]/a'
xpath2 = f'//*[@id="sougou"]/ul/li[{i}]/a/text()'
xpath3 = f'//*[@id="sougou"]/ul/li[{i}]/a/img'
link = html.xpath(xpath)
link2 = html.xpath(xpath2)
link3 = html.xpath(xpath3)
href = link[0].get("href")
text = link2[0]
image = link3[0].get("style")
image = image.replace("background-image: url(", "").replace(");", "") # 余計なスタイルシート指定を削除
f.write(f'{i} {url_base}{href} {text} {image}\n')
f.close()
ログインが必要なコンテンツへの対応
Seleniumを使うことによりログインが必要なコンテンツへのアクセスも容易に行えます。
以下の記事が参考になります。
Seleniumでログインを含めてWebスクレイピングしてみたhttps://qiita.com/cheekykorkind/items/efec86759073bf3f72e9
Python + Selenium + Chrome で自動ログインいくつかhttps://qiita.com/memakura/items/dbe7f6edadd456da1c5d