はじめに
いきなりですが, ECDSA という楕円曲線を使った署名技術が存在します1. そして,
$ python3 pip install ecdsa
で導入されるライブラリを使うと, pythonでECDSAの鍵生成や署名をはじめとして, DER/PEM形式での鍵のインポートやエクスポートも可能となります.
今回いろいろあってこのあたりの構造を調べていたら, タイトルの通り署名鍵インポートが適当だったことが判明したので, 自分への備忘録も兼ねてこれを記している次第です.
なお, はじめに断っておくとこれはバグではなく, ただ単に(それを承知の上で)実装されていないだけです.
環境
$ python3 --version
Python 3.10.12
$ python3 -m pip list | grep ecdsa
ecdsa 0.18.0
OSはUbuntu 22.04です.
ECDSAライブラリの扱い方
公式ドキュメント のUsageに一番最初に掲載されているサンプルコードを引用しています.
from ecdsa import SigningKey
sk = SigningKey.generate() # uses NIST192p
vk = sk.verifying_key
signature = sk.sign(b"message")
assert vk.verify(signature, b"message")
これをベースとして, 署名鍵skとシグネチャsignatureの中身を解析していきます.
シグネチャの構造
from ecdsa import SigningKey
sk = SigningKey.generate() # uses NIST192p
vk = sk.verifying_key
signature = sk.sign(b"message")
print(signature)
# b'`2f\x9e\xfb\x06\x98\x95(\xcbQ\xe3hG\xb3V\x8f\xe95:K\xbc\x1c\xb1h*5\x9c5as\xf8\xff\xe07\xda\x84\xb6\xe1\\j:\x023m\x9f!\x81'
上記のような48バイトのバイト列がシグネチャとして出力されます.
しかし, ECDSAについて少しばかり知識がある人は (あるいはWikipediaのセクションを見た人は) シグネチャが $(r,s)$ の2ペアからなることに気づくと思います.
これについては至ってシンプルで, 前半24バイトが$r$, 後半24バイトが$s$となります.
r = signature[:len(signature)//2]
print(r)
# b'`2f\x9e\xfb\x06\x98\x95(\xcbQ\xe3hG\xb3V\x8f\xe95:K\xbc\x1c\xb1'
s = signature[len(signature)//2:]
print(s)
# b'h*5\x9c5as\xf8\xff\xe07\xda\x84\xb6\xe1\\j:\x023m\x9f!\x81'
署名鍵の構造
from ecdsa import SigningKey
sk = SigningKey.generate() # uses NIST192p
print(sk.to_der())
# b'0_\x02\x01\x01\x04\x18\xe2\xc8\x87\x1cJ0\x92\x12\xca,\xa9L7\x13\x18.\x8a\xe4l[\xb0\xa7\x85\xb5\xa0\n\x06\x08*\x86H\xce=\x03\x01\x01\xa14\x032\x00\x04r\x8d\x88-\xaf\xea\x80\x15\xc7C\xe9\xb8\xdeo\xf7\x81\xb1\xf5+\xf3i>\x18\xda\xc6\x15T\x13\xc4t\xe5\xaa\x17#S\xaf\xbccE.\x9b7\x1c\xb8t\x13m\xd1'
上記のような97バイトのバイト列がDERフォーマットの署名鍵として出力されます. これを解析というかparseしていきます.
前提として, これらは基本的に
-
dataの属性情報 (1バイト) -
dataの長さ (1バイト2) -
data本体 (可変長)
の3つを塊としたブロックから構成されています.
属性情報については以下のような番号が割り振られています. constructedだけtagというのが付与されていますが, それについては後ほど取り上げます.
| 属性 | 番号 |
|---|---|
integer |
0x02 |
bitstring |
0x03 |
octet string |
0x04 |
object |
0x06 |
sequence |
0x30 |
constructed |
0xa0 + tag
|
0, 1バイト目
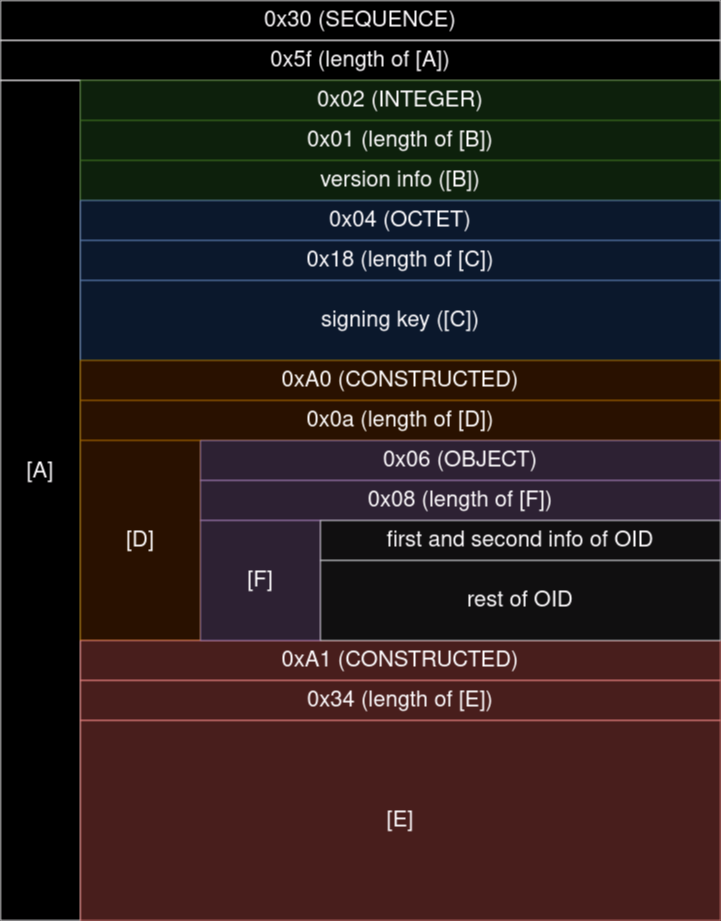
0バイト目は0, つまり0x30 -> sequence属性3
1バイト目は_, つまり0x5f -> このあとにsequence属性のデータ[A]が95バイト続きます.

2-4バイト目
2バイト目は0x02 -> integer属性
3バイト目は0x01 -> このあとにinteger属性のデータ[B]が1バイト続きます.
4バイト目は0x01 -> RFC 5915 に準拠しているバージョンを表すデータで, ここでは1で固定です.

5-30バイト目
5バイト目は0x04 -> octet string属性
6バイト目は0x18 -> このあとにoctet string属性のデータ[C]が24バイト続きます.
7-30バイト目 -> ここにECDSAの秘密鍵(厳密には署名鍵)の情報が入っています. 特に圧縮等もされておらず, 生のデータでそのまま格納されています.

31-42バイト目
31バイト目は0xa0 -> tagに0がセットされたconstructed属性(0xa0 + tagで計算された値が31バイト目に入っています). このtagは後述する楕円曲線の選定に関連するもので, 0で固定です.
32バイト目は\n, つまり0x0a -> このあとにconstructed属性のデータ[D]が10バイト続きます.
33-42バイト目 -> ここにどの楕円曲線を使用するかの情報(OID, Object Identifier)が入っています. ここは少し手を加えられているので以下でも少し取り上げます.

43-96バイト目
43バイト目は0xa1 -> tagに1がセットされたconstructed属性. このtagは検証鍵に関連するもので, 1で固定です.
44バイト目は4, つまり0x34 -> このあとにconstructed属性のデータ[E]が52バイト続きます.
45-96バイト目 -> ここに検証鍵が入っています. ここもまだ生データではないので後に詳しく触れます.

OIDについて
33-42バイト目の[D]セクションについてさらに見ていきます. ここには現在\x06\x08*\x86H\xce=\x03\x01\x01が格納されています.
33バイト目は0x06 -> object属性
34バイト目は0x08 -> このあとにobject属性のデータ[F]が8バイト続きます.
35-42バイト目 -> [0x2a, 0x86, 0x48, 0xce, 0x3d, 0x03, 0x01, 0x01]
ここの解読がこの記事中で最も複雑な処理かもしれません.
- 基本的に各要素の下7ビットを出力
- ただし, 要素が0x80以上であるならば, 次の要素の下位7ビットを末尾に結合する
がルールとなります. 当然, 2.で取り出した次の要素も再び0x80以上であれば, さらにその次の要素も取り出すことになります.
したがって,
- 35バイト目 -> 0x2a < 0x80なので, 下位7ビットの`0101010`を出力 -> 42
- 36バイト目 -> 0x86 >= 0x80なので, 下位7ビットの
0000110と, 次の37バイト目の下位7バイトを結合する- 37バイト目 -> 0x48 < 0x80なので, 下位7ビットの`1001000`を末尾に結合して`0000110_1001000`を出力 -> 840
- 38バイト目 -> 0xce >= 0x80なので, 下位7ビットの
1001110と, 次の39バイト目の下位7バイトを結合する- 39バイト目 -> 0x3d < 0x80なので, 下位7ビットの`0111101`を末尾に結合して`1001110_0111101`を出力 -> 10045
- 40-42バイト目 -> 下位7ビットを出力 -> (3, 1, 1)
よって, この35-42バイト目は(42, 840, 10045, 3, 1, 1)を意味することになります.
さらに, 35バイト目の42には, 40 * first + secondの値が入っています. これを満たす組はいくつか存在しますが,
assert 0 <= first < 2 and 0 <= second <= 39 or first == 2 and 0 <= second
という条件があります(ソースコードを参照). よって, first = 1, second = 2のみが該当します
以上をまとめると, (1, 2, 840, 10045, 3, 1, 1)が[F]セクションに格納されているOIDになります. なお, これは当然ながらデフォルトで選択される楕円曲線NIST192p (ここから確認できます) のものと一致しています.
検証鍵について
45-96バイト目の[E]セクションについてさらに見ていきます. ここには現在\x032\x00\x04r\x8d\x88-\xaf\xea\x80\x15\xc7C\xe9\xb8\xdeo\xf7\x81\xb1\xf5+\xf3i>\x18\xda\xc6\x15T\x13\xc4t\xe5\xaa\x17#S\xaf\xbccE.\x9b7\x1c\xb8t\x13m\xd1'が格納されています.
45バイト目は0x03 -> bitstring属性です. さて, 冒頭のほうで
前提として, これらは基本的に
dataの属性情報 (1バイト)dataの長さ (1バイト2)data本体 (可変長)の3つを塊としたブロックから構成されています.
と言いましたが, bitstring属性は例外で, 以下のような構造となっています.
-
dataの属性情報 (1バイト) -
data+encoded_unusedの長さ (1バイト) -
encoded_unused本体 (1バイト) -
data本体 (可変長)
特にパラメータを設定しない場合, encoded_unused = 0です. したがって, 改めて45バイト目からの構造を追ってみると,
45バイト目は0x03 -> bitstring属性
46バイト目は'2', つまり0x32 -> このあとにbitstring属性のデータ[G]と, encoded_unusedが計50バイト続きます.
47バイト目は0x00 -> デフォルトのencoded_unused
48-96バイト目にデータ本体[G]が入っています
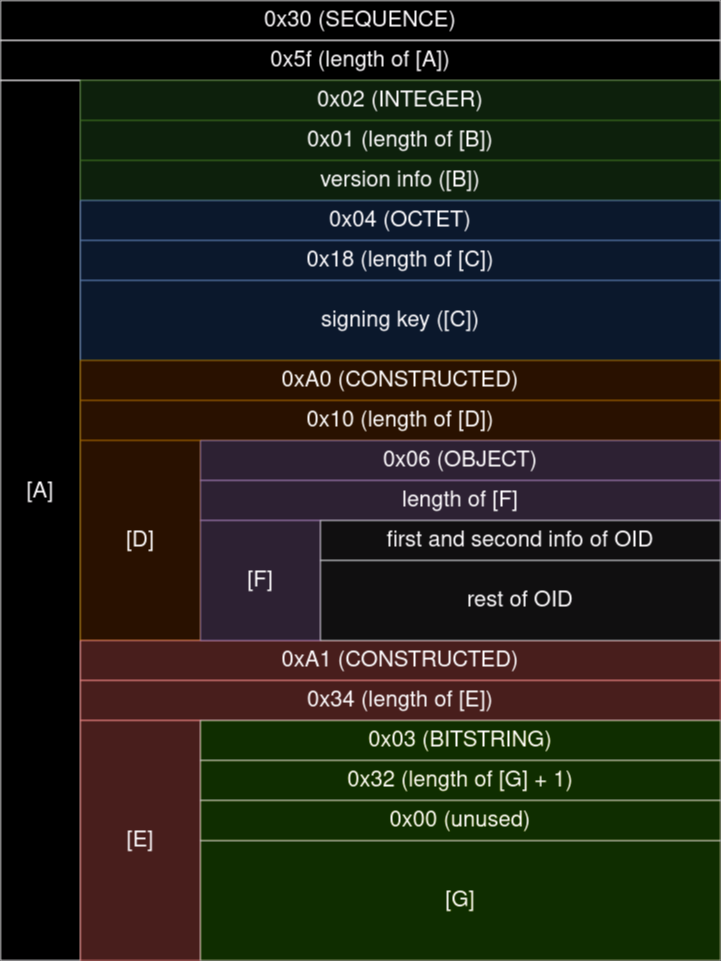
さらに[G]の構造を見ていきましょう. データは\x04r\x8d\x88-\xaf\xea\x80\x15\xc7C\xe9\xb8\xdeo\xf7\x81\xb1\xf5+\xf3i>\x18\xda\xc6\x15T\x13\xc4t\xe5\xaa\x17#S\xaf\xbccE.\x9b7\x1c\xb8t\x13m\xd1です.
この先頭の0x04はoctet string属性ではなく, 楕円曲線上の点の表現を圧縮するかどうかを表しています.
特に指定しない場合, デフォルトではuncompressedが選択されるようになっており, その場合
elif encoding == "uncompressed":
return b"\x04" + self._raw_encode()
という感じで\x04 + (検証鍵の$x$座標) + (検証鍵の$y$座標)となっています (ソースコード 参照). したがって,
- 48バイト目は0x04 ->
uncompressedを意味 - 49-72バイト目 -> 検証鍵の$x$座標
- 73-96バイト目 -> 検証鍵の$y$座標
となります.

署名鍵の読み込み
from ecdsa import SigningKey
sk = SigningKey.generate() # uses NIST192p
sk2 = SigningKey.from_der(sk.to_der())
署名鍵をDER形式でインポートする場合, from_derを使います. この挙動を追うのが本題となります.
該当するソースコードは ここ で, 以下にコメント部分をカットしたものを掲載します
また, !!!REDACTED!!!となっている箇所はとても長いのですが, 今回の場合だとこのif文に突入することがないのでバッサリ省略しています. この部分についても少し触れます.
def from_der(cls, string, hashfunc=sha1, valid_curve_encodings=None):
s = normalise_bytes(string)
curve = None
s, empty = der.remove_sequence(s)
if empty != b(""):
raise der.UnexpectedDER(
"trailing junk after DER privkey: %s" % binascii.hexlify(empty)
)
version, s = der.remove_integer(s)
if der.is_sequence(s):
!!!REDACTED!!!
if version != 1:
raise der.UnexpectedDER(
"expected version '1' at start of DER privkey, got %d"
% version
)
privkey_str, s = der.remove_octet_string(s)
if not curve:
tag, curve_oid_str, s = der.remove_constructed(s)
if tag != 0:
raise der.UnexpectedDER(
"expected tag 0 in DER privkey, got %d" % tag
)
curve = Curve.from_der(curve_oid_str, valid_curve_encodings)
if len(privkey_str) < curve.baselen:
privkey_str = (
b("\x00") * (curve.baselen - len(privkey_str)) + privkey_str
)
return cls.from_string(privkey_str, curve, hashfunc)
さて, このparserを上から見ていきます.
6行目
s, empty = der.remove_sequence(s)
sequence属性情報[A]を取り出してsに格納
12行目
version, s = der.remove_integer(s)
RFC5915準拠のバージョン情報[B]を取り出し, 残りをsに格納.
14行目
if der.is_sequence(s):
この時点で残っているsの先頭は署名鍵に関するoctet string属性情報であり, sequence属性情報ではありません. したがって, 今回であれば14行目のif文がTrueになることはありません.
23行目
privkey_str, s = der.remove_octet_string(s)
署名鍵[C]を取り出し, 残りをsに格納
25-26行目
if not curve:
tag, curve_oid_str, s = der.remove_constructed(s)
curve = Noneのままなので25行目のif文に突入. OIDに関するデータ[D]を取り出し, 残りをsに格納
さて, 26行目で[D]を取り出して以降, 残った54バイト分のsが呼ばれることがないのです. このsには検証鍵に関するデータが入っていて, RFC5915にも
ECPrivateKey ::= SEQUENCE { version INTEGER { ecPrivkeyVer1(1) } (ecPrivkeyVer1), privateKey OCTET STRING, parameters [0] ECParameters {{ NamedCurve }} OPTIONAL, publicKey [1] BIT STRING OPTIONAL } The fields of type ECPrivateKey have the following meanings:
とあり, 検証鍵(public key)はOPTIONALであることが読み取れます. なので, 署名鍵を生成するにあたって必ず必要になる情報でないのは事実なのですが, この部分が正しいかどうかの検証はなされていません.
さて, 後出しじゃんけんのようになって申し訳ないですが,
以下にコメント部分をカットしたものを掲載します
と書いた割には, 実は25行目のif文を抜けた先に, 以下のようなコメントがあります.
# we don't actually care about the following fields
#
# tag, pubkey_bitstring, s = der.remove_constructed(s)
# if tag != 1:
# raise der.UnexpectedDER("expected tag 1 in DER privkey, got %d"
# % tag)
# pubkey_str = der.remove_bitstring(pubkey_bitstring, 0)
# if empty != "":
# raise der.UnexpectedDER("trailing junk after DER privkey "
# "pubkeystr: %s"
# % binascii.hexlify(empty))
ただ, いずれにせよフォーマットに則った形式かどうかをチェックしているだけで, 「検証鍵と署名鍵のペアが正しいかどうか」のチェックはなされていません. つまり, 属性情報などを除いた検証鍵の生データが格納されている末尾48バイトには何をセットしてもよく,
from ecdsa import SigningKey
sk = SigningKey.generate() # uses NIST192p
sk_pollute = sk.to_der()[:-48] + b'\xff' * 48
sk2 = SigningKey.from_der(sk_pollute)
であれば, 上記のコメントアウトが仮になかったとしてもsk2は正しい署名鍵として認識されます.
おわりに
一度from_der()が呼ばれてしまえば, 末尾が書き換えられても正しい鍵として扱われるので, これ単体ではまぁ大丈夫なんでしょうけどモヤモヤがありますね…
ヤバいシナリオを無理やりこじつけるなら, callerがfrom_der()を呼び出す前にdatabaseに保存している署名鍵と全く一致しているかどうかをチェックする機構を持っていたけど, 通信路上で末尾が書き換えられてFRR(本人拒否率)が上がるとかですか…