この記事はEnjoy Architectingからの転載です。
概要
分散システムを学術的に学びたくて、
Chord Protocolというアルゴリズムが面白かったので実際に論文を読んで実装してみました。
この記事では、分散システムにおける名前付けの概念と、Chord Protocolの紹介、簡単な検証について言及していこうと思います。
 |
|---|
| 実際に作ったサーバ |
分散システムにおける名前付けとは?
分散システムの分野には「名前」、「名前付け」、「アドレス」と呼ばれる概念があります。
それぞれどのような意味を持っているのでしょうか?
名前付けと名前
分散システムはネットワークを通じてそれぞれのサーバ、プロセスが協調して動作しています。
この中で、各サーバ、プロセスはやり取りをする相手の「名前」を知らなければやり取りを行うことができません。
この名前の解決を行うことを「名前付け」と呼んでいます。
そして、あるリソース(特定のプロセス、サーバなど)を一意に特定するための文字列を「名前」呼んでいます。
アドレス
名前が分かっていても実際にはそれだけではやり取りできず、実際には「アドレス」と呼ばれるリソースの住所に対してアクセスすることでやり取りが成立します。
つまり、リソースに対する実質的なアクセスポイントをアドレスと呼んでいます。
名前との違いは、名前は永続的にリソースを一意に特定するもの、
アドレスはアクセスするために必要な実際のリソースの住所、つまり位置情報を持っているということです。
名前は永続的に同じリソースを指し続けるのに対し、アドレスはそのときリソースが存在する位置によって変化します。
具体例
ドメイン名(example.com)が「名前」、example.comに紐づくAレコードのIPが「アドレス」に当たります。
ドメイン名はずっと変わりませんが、IPアドレスはサーバを移管したりすることで変化することがありえます。
永久に同じリソースへのポインタになるのでドメインは「名前」として成立するわけです。
Naming Serverとは?
名前からアドレスを解決したり、特定のリソースに名前をつけてくれるサービスのことをNaming Serviceと呼びます。
一番わかり易い例としては、DNSが挙げられます。
DNSは、ドメインという名前からIPというアドレスを解決し、またIPに対してドメイン名をつける名前付けを行うことで成立しています。
代表的なアルゴリズム ~Consistent Hash~
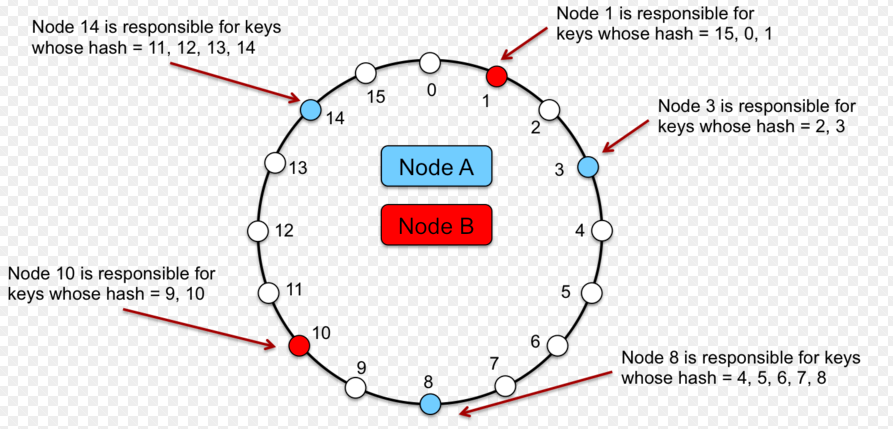
名前付け、名前解決のためのアルゴリズムとしてメジャーなものにConsistent Hashがあります。
Consistent Hashは、
サーバの集合(以降各要素をノードと呼ぶ)に対してハッシュ関数で一意のID(たいていはホスト名などのハッシュ)を振り、
各ノードをID順に円状に並べ、
あるIDがどのノードに配置されるべきかを決定するアルゴリズムです。
与えられたID以上であり、値が一番近いノードに解決され、
円状になっているので、
仮にそのノードがいなくなったとしても次のノードに回されるといったように、ノード障害に強いアルゴリズムになっています。
詳しくは、こちらがわかりやすいです。
コンシステントハッシュ法
ハッシュによって名前付けを行い、
ハッシュによるIDから対応するサーバを解決して名前解決を行います。
(引用: https://vitalflux.com/wtf-consistent-hashing-databases/)
Consistent Hashの拡張、Chord Protocol
前述のConsistent Hashは完璧ではなく、欠点があります。
それは、ノードの離脱、ノードの参画がいつ起こったとしても、
ただしい結果を返し続けるためには一つのノードは、参加している他のすべてのノードの状態を把握している必要があることです。
(そうでないとノードが増えたり減ったりした時点で正しく結果を返すことができなくなる)
これは大規模な分散システムになればなるほど、大きな課題になりえます。
大規模なノードの集合では各ノードは他のノードの情報を保持するために大規模なリソースを要求し、また、ノードの参加、離脱時の情報更新などの計算コストも高くつくことになります。
これを解決するべく生まれたのがChord Protocolになります。
基本的なアルゴリズムは下記の資料がとてもわかり易くまとめられています。
Chord Protocolは何が優れているのか?
基本的なことは上の資料がとてもわかり易いので、ここではかいつまんで何が優れているポイントなのかを説明しておきます。
乱暴にいってしまえば、
- 経路表による高速な検索
- ノード参画、離脱時に各ノードが独立して経路表を更新する仕組み
- 経路表が最新化されていない場合のためのFallback手段としてのSuccessorList
が主なポイントになります。
これらのポイントにより、耐障害性を担保しつつスケーラビリティを向上させることに成功しています。
順に追っていきましょう。
経路表による高速な検索
各ノードは、全てのノードの状態を維持する代わりに、一定サイズの経路表をメンテナンスします。
例えば、32ビット長のハッシュをIDとする場合、32個の行数を持つ経路表を持ち、
この表を元にして、他ノードにルーティングして検索します。
計算量はO(logN)になり(Nはノード数)、これによって大幅にスケーラビリティを担保できるようになります。
ノード参画、離脱時に各ノードが独立して経路表を更新する仕組み
Chord Protocolでは、ノードの参画、離脱時に各ノードがそれぞれ安定化させるためのルールを規定しています。
このルールに従った非同期プロセス、ないしスレッドが一定間隔で動作していて、経路表のメンテナンスを行います。
このメンテナンスは、ノードの離脱、参画に対して、メッセージ数がO(log^2N)程度で、そこそこ高速に実行されます。
経路表が最新化されていない場合のためのFallback手段としてのSuccessorList
ノードが参加した直後などは当然経路表は最新化されていません。
よって一時的に正しい結果を返せない可能性もあります。
そこで、この資料のスライド131ページあたりに記載されているように、
Successor Listというリストも保持しておき、経路表による検索に失敗した場合はこのリストを使ってFallbackすることができます。
実際に実装してみた
ここまでがNaming Service及び、Chord Protocolの説明でした。
今回は、これをもとに実際にNaming ServiceをGoで実装してみました。
Goで書いたChordの参照実装なので名前はgordです。(安直)
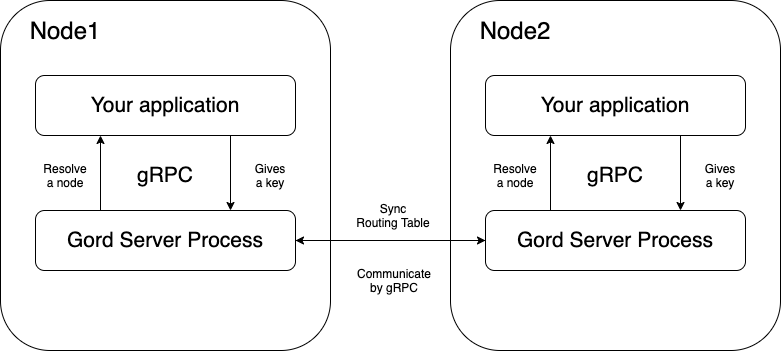
gordの概要
これはどういう実装かというと、
GordがChord Protocolのノード郡を管理するためのプロセスとして常駐し、
別途ストレージを管理するソフトウェアがgRPCでGordに対してアクセスし、
特定のキーがどのノードに存在するかを検索したり、
自分たちが管理するべきキーを判別したりする、といった機能を提供します。
k8sであればサイドカーとして各Podにくっついているイメージになります。
この構成は実際に論文でもサンプルとして提案されている構成になります。
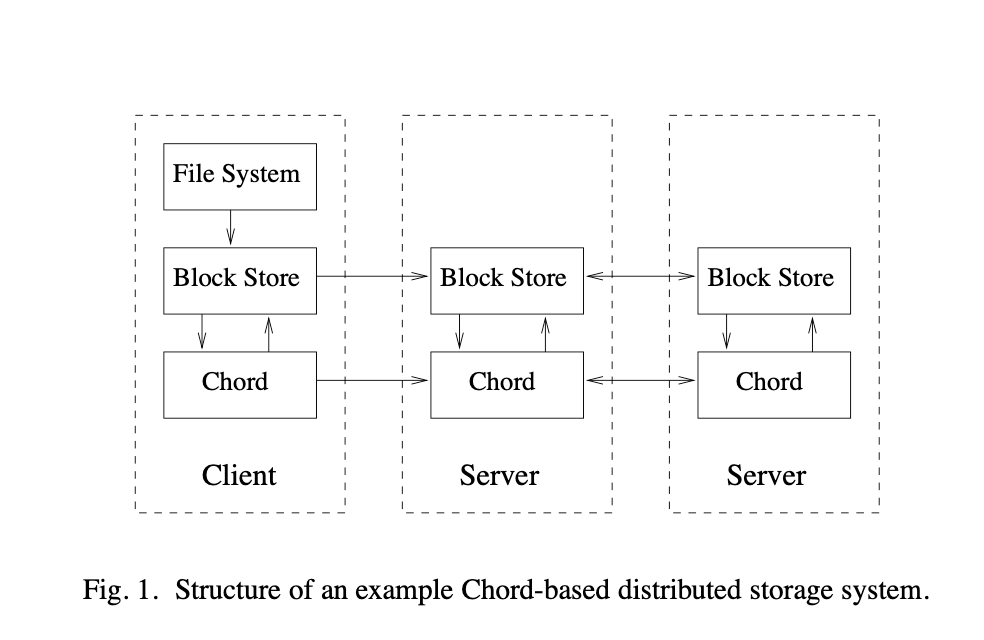 |
|---|
| 論文で提案されている構成 |
|
|---|
| 実際に落とし込んだ構成 |
実装に対する検証
実際に実装に落とし込んだところで、ちゃんと実装できているのかを検証したいと思います。
機能的な観点は、単体テストにて実装しているので今回はパフォーマンス、耐障害性について検証してみます。
ただし、ローカルマシンでの検証につき、プロセッサ数に限度があるため、
お遊び程度の検証しかできないのはあしからず...
パフォーマンスに関する検証
探索のパフォーマンスを測定してみます。
ノード数を1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024と増やしていったときに特定キーの検索にかかる時間を計算してみましょう。
[ベンチマークテストの実装は雑ですがこの辺です。]
(https://github.com/taisho6339/gord/blob/master/chord/bench_search_test.go)
すでにStabilizationを完了したノードを指定数用意し、検索のパフォーマンスの違いを見ていきます。
実験にした私のマシンは下記のスペックになります。
OS: MacOS Catalina 10.15.5
プロセッサ: 2.4 GHz 8コア/16スレッド Intel Core i9
メモリ: 64 GB 2667 MHz DDR4
結果はこんな感じになりました。
| ノード数 | 検索にかかった時間 |
|---|---|
| 1 | 20.1 ns/op |
| 2 | 4440 ns/op |
| 4 | 4450 ns/op |
| 8 | 4644 ns/op |
| 16 | 4644 ns/op |
| 32 | 6473 ns/op |
| 64 | 19778 ns/op |
| 128 | 25808 ns/op |
| 256 | 35940 ns/op |
| 512 | 35825 ns/op |
| 1024 | 36940 ns/op |
ローカルマシンでの検証なので32ノード以上になってくると、
ノードが実行している大量のゴルーチンを限られたプロセッサで共有せざるを得なくなってくるため、アルゴリズム以外の要因で遅くなっていそうです。
少なくともノード数によって線形に増加している傾向は見られませんでした。
耐障害性に関する検証
docker-compose build && docker-compose up
gord1_1 | time="2020-07-22T06:59:08Z" level=info msg="Running Gord server..."
gord1_1 | time="2020-07-22T06:59:08Z" level=info msg="Gord is listening on gord1:26041"
gord1_1 | time="2020-07-22T06:59:08Z" level=info msg="Running Chord server..."
gord1_1 | time="2020-07-22T06:59:08Z" level=info msg="Chord listening on gord1:26040"
gord1_1 | time="2020-07-22T06:59:09Z" level=info msg="Host[gord1] updated its successor."
gord2_1 | time="2020-07-22T06:59:09Z" level=info msg="Running Gord server..."
gord2_1 | time="2020-07-22T06:59:09Z" level=info msg="Gord is listening on gord2:26041"
gord3_1 | time="2020-07-22T06:59:09Z" level=info msg="Running Gord server..."
gord3_1 | time="2020-07-22T06:59:09Z" level=info msg="Gord is listening on gord3:26041"
gord2_1 | time="2020-07-22T06:59:09Z" level=info msg="Running Chord server..."
gord2_1 | time="2020-07-22T06:59:09Z" level=info msg="Chord listening on gord2:26040"
gord3_1 | time="2020-07-22T06:59:09Z" level=info msg="Running Chord server..."
gord3_1 | time="2020-07-22T06:59:09Z" level=info msg="Chord listening on gord3:26040"
gord2_1 | time="2020-07-22T06:59:09Z" level=info msg="Host[gord2] updated its successor."
すぐにStabilizerがノード間連携をし、経路表を更新することでどのノードも一貫した結果を返しています。
grpcurl -plaintext -d '{"key": "gord1"}' localhost:26041 server.ExternalService/FindHostForKey \
&& grpcurl -plaintext -d '{"key": "gord1"}' localhost:36041 server.ExternalService/FindHostForKey \
&& grpcurl -plaintext -d '{"key": "gord1"}' localhost:46041 server.ExternalService/FindHostForKey
{
"host": "gord1"
}
{
"host": "gord1"
}
{
"host": "gord1"
}
つぎに試しに1ノード退場させてみます。
docker stop 1a3bf85b693b
gord3_1 | time="2020-07-22T07:04:43Z" level=error msg="successor stabilizer failed. err = &errors.errorString{s:\"NodeUnavailable\"}"
gord2_1 | time="2020-07-22T07:04:43Z" level=warning msg="Host:[gord1] is dead."
gord3_1 | time="2020-07-22T07:04:43Z" level=warning msg="Host:[gord1] is dead."
gord_gord1_1 exited with code 0
すぐにノードのダウンを検知し、更新に入っています。
grpcurl -plaintext -d '{"key": "gord1"}' localhost:36041 server.ExternalService/FindHostForKey \ ✘ 1
&& grpcurl -plaintext -d '{"key": "gord1"}' localhost:46041 server.ExternalService/FindHostForKey
{
"host": "gord2"
}
{
"host": "gord2"
}
ノード1がダウンしてもすぐに経路表が更新され、さらにノード1に本来属していた"gord1"というキーが別のノードに移っていることがわかります。
まとめ
実際にChord Protocolを実装することで、
実装としては、未熟な点やバグなど残っていると思いますが、何が優れていて、既存の手法とは何が違うのかを実際に理解することができました。
また付加価値として256ビットにもなる大きな数値をGolangでどう計算するのか、
Golangでの並行処理についても勉強することができました。
こういったことが直接お仕事の役に立つケースは多くはないかもしれませんが、実装力のレベルを一段引き上げてくれる良い機会になり、楽しむことができました。
今度はもっと身近なOSSなどで利用されているアルゴリズムなども実装してみたいと思います。