はじめに
皆さんこんにちは!
記事タイトルをYou○ubeの【歌ってみた】風にしてみました〜、【】つけるとSEO的に良いって聞いたような聞いてないような。
伸びろ閲覧数☆ということで、今回はCDC(Change Data Capture)をAWS DMS(フルマネージド)で実現してみたので、CDCとは何か?というところからマネコンの操作まで解説していきます。
What is CDC ?
特定のデータソースに発生した変更を追跡することをCDCと称します。
図に起こすとこんな感じです。
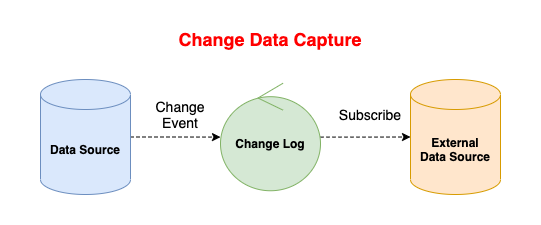
何が嬉しいの?
例えばですが、
「基盤サービスのDBと新規サービスのDBは全く異なっているけれどデータ同期はしたい」といった要件にマッチします。
Micro Serviceで解決できないの?
おっしゃるとおりです。サービス単位でエンドポイントが事前に切り出されていれば、こういった同期したいという要件自体発生しないと思います。
また、ドメイン単位でDBが切り出されている場合は変更を追うのも容易でしょう。
ただ、既存にある分割されていないサービスに対してはCDCの方がコスト的には低いといえるので最適なアプローチだと思います。
CDCを実装するためにAWS DMSを使用する
What is DMS ?
正式名称は「Database Migration Service」となり、データ移行用のサービスとなります。
図に起こすと以下のような感じです。
※ DMSの理解にこの図はめちょ重要なんで、よく見てもらえると
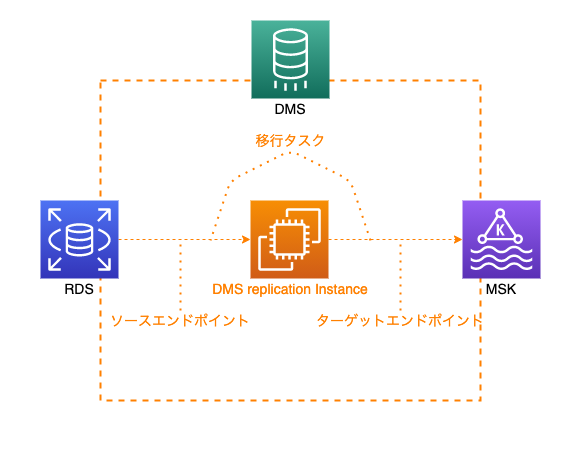
RDSの変更が起きた際に、ソースエンドポイントを介してレプリケーションのEC2インスタンスからデータ整形を行い、ターゲットエンドポイントを介してMSKに変更の反映が行われます。
この一連の流れを指して移行タスクと呼びます。
What is MSK ?
正式名称「Managed Streaming for Apache Kafka」
端的に言うとフルマネージドなApache Kafkaです。
Kafkaってなんやねんって方は凄めなMQだと思ってもらえると。
MQってなんやねんて人は手紙書いて紙飛行機にして隣の人に飛ばしてください、それがMQです。
[実践] AWS マネコン操作編
ゆるーくCDCとDMSとMSKについて解説しましたので、マネコンの操作編へ。
RDSの説明してなかったですけど、DB(ドラゴンボールデータベース)のことを指してます。
データの流れ通り、
ソースエンドポイント -> レプリケーションインスタンス -> ターゲットエンドポイント -> それらを連結させる移行タスク の順で作っていきます。
ソースエンドポイントの作成
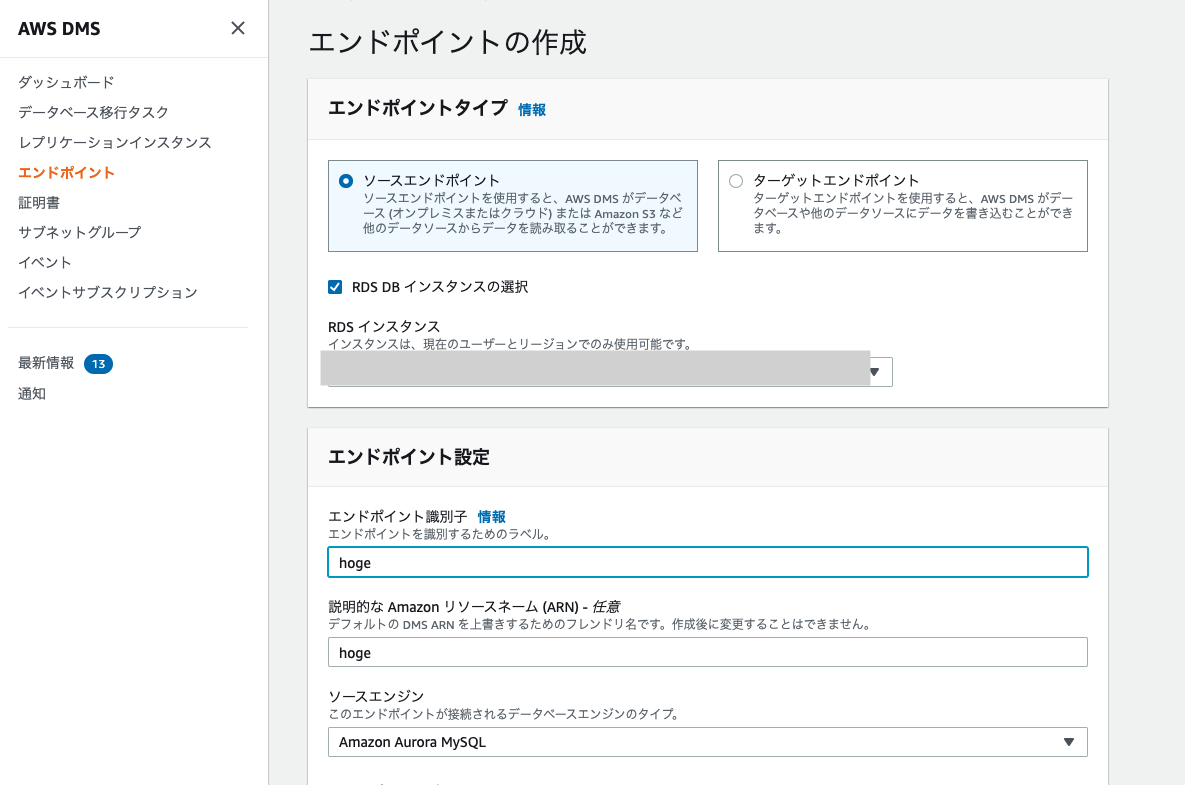
「エンドポイントの作成」を押下すると、以下の画面が出てくるのでソースエンドポイントにチェックを入れましょう。
仮にRDSを使う場合はソースエンジンにAuroraやPostgreSQLを選択してください。
その後、RDSインスタンスの選択項目で使用するRDSインスタンスの名称を選択してください。
レプリケーションインスタンスの作成
「レプリケーションインスタンスの作成」を押下すると、以下の画面が出てくるので適切なサイジングを行えば、作業完了となります。
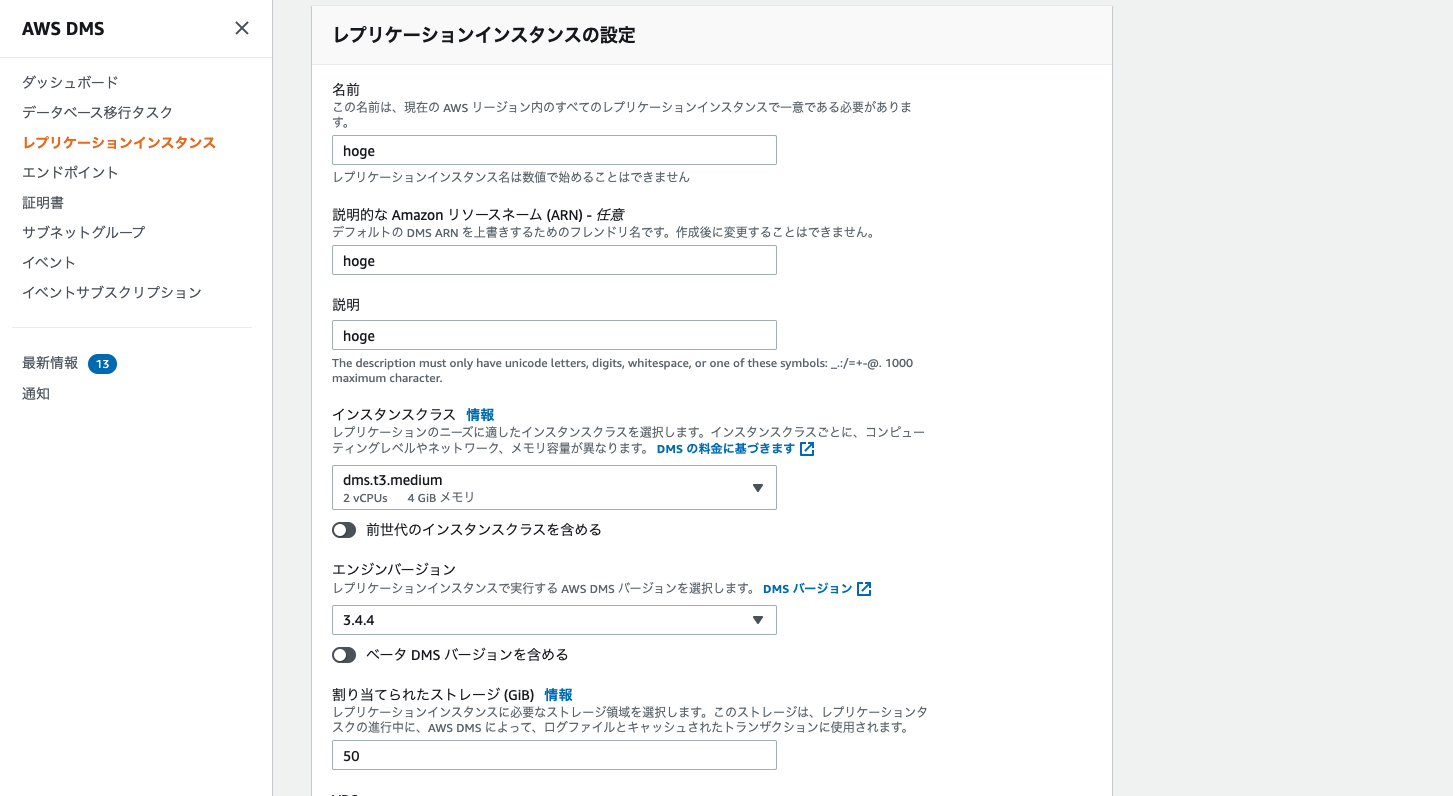
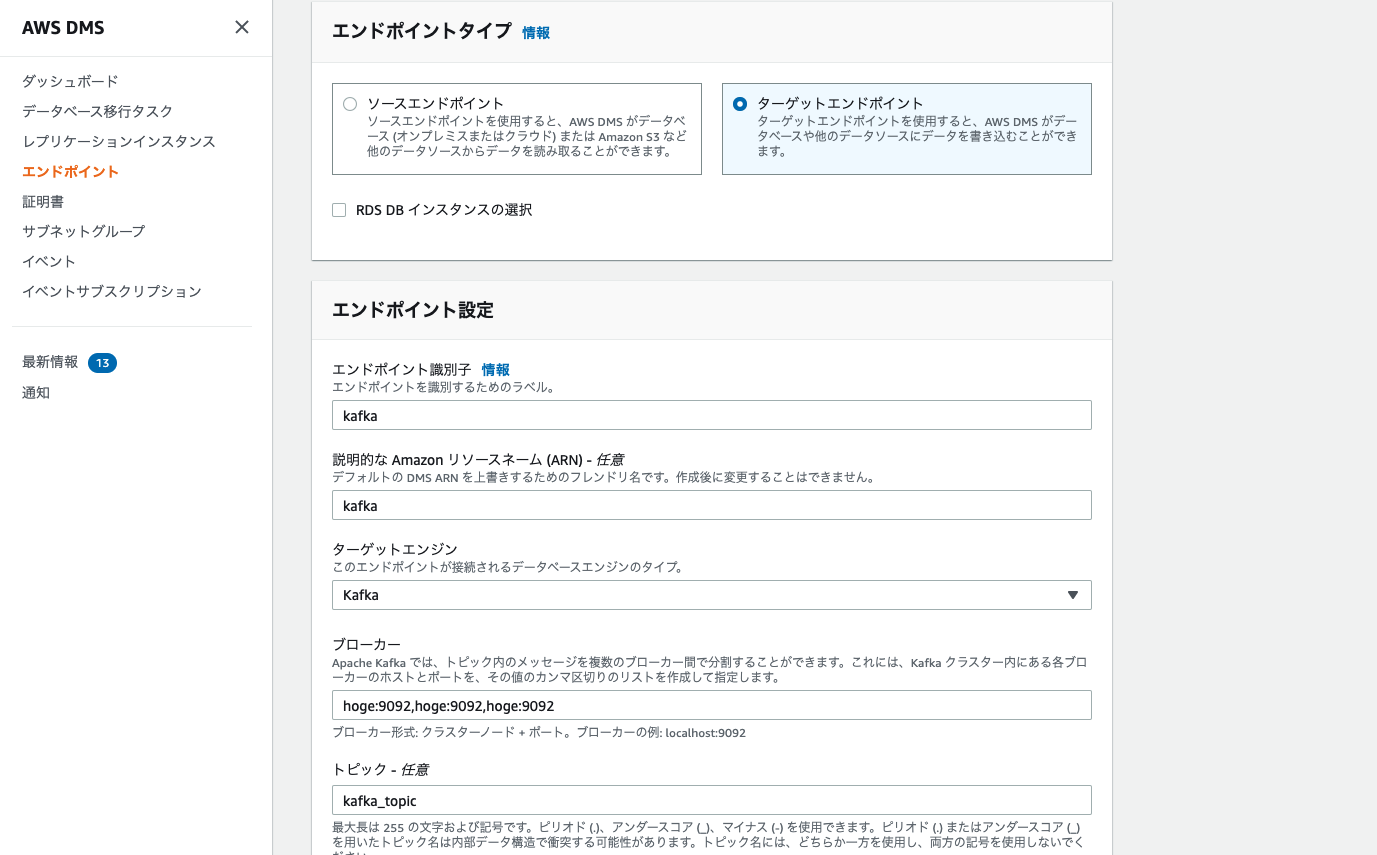
ターゲットエンドポイントの作成
「エンドポイントの作成」を押下すると、以下の画面が出てくるのでターゲットエンドポイントにチェックを入れましょう。
仮にKafkaを使う場合はターゲットエンジンにKafkaを選択しKafkaのブローカー情報とKafkaに存在するトピックの名称を入れてください。
※ KafkaはTopicをマネコンから作れないので気をつけてね!
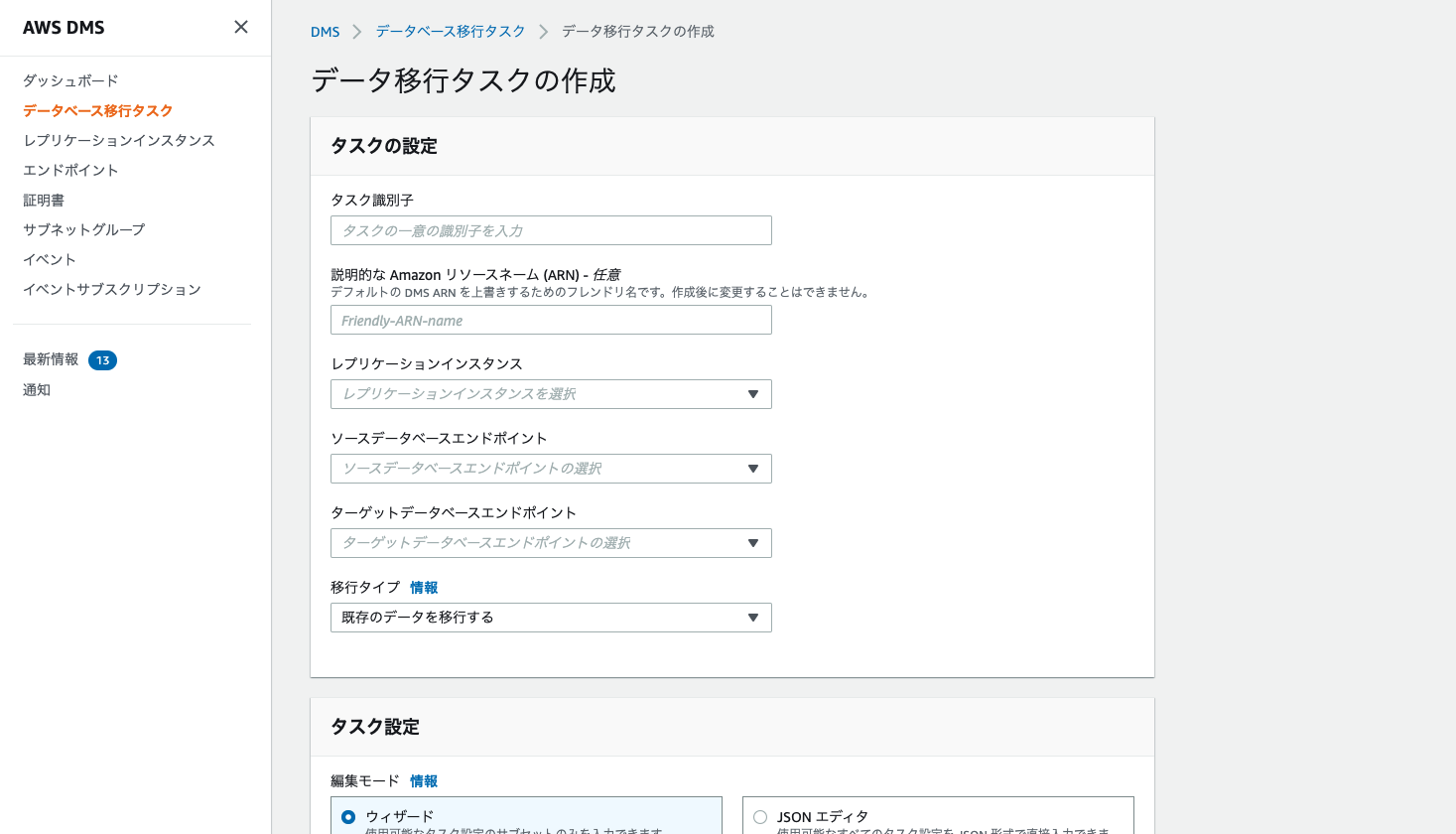
データベース移行タスクの作成
ここで、それぞれ作ったエンドポイントとレプリケーションインスタンスの紐付けを行います。
「タスクの作成」を押下すると、以下の画面が出てくるのでこれまでに作ったレプリケーションインスタンスとエンドポイントを選択しましょう。
また、CDCとして使用する場合は移行タイプで変更をレプリケートするようにしましょう。
選択後、以下のテーブルマッピングの画面が出てくると思います。
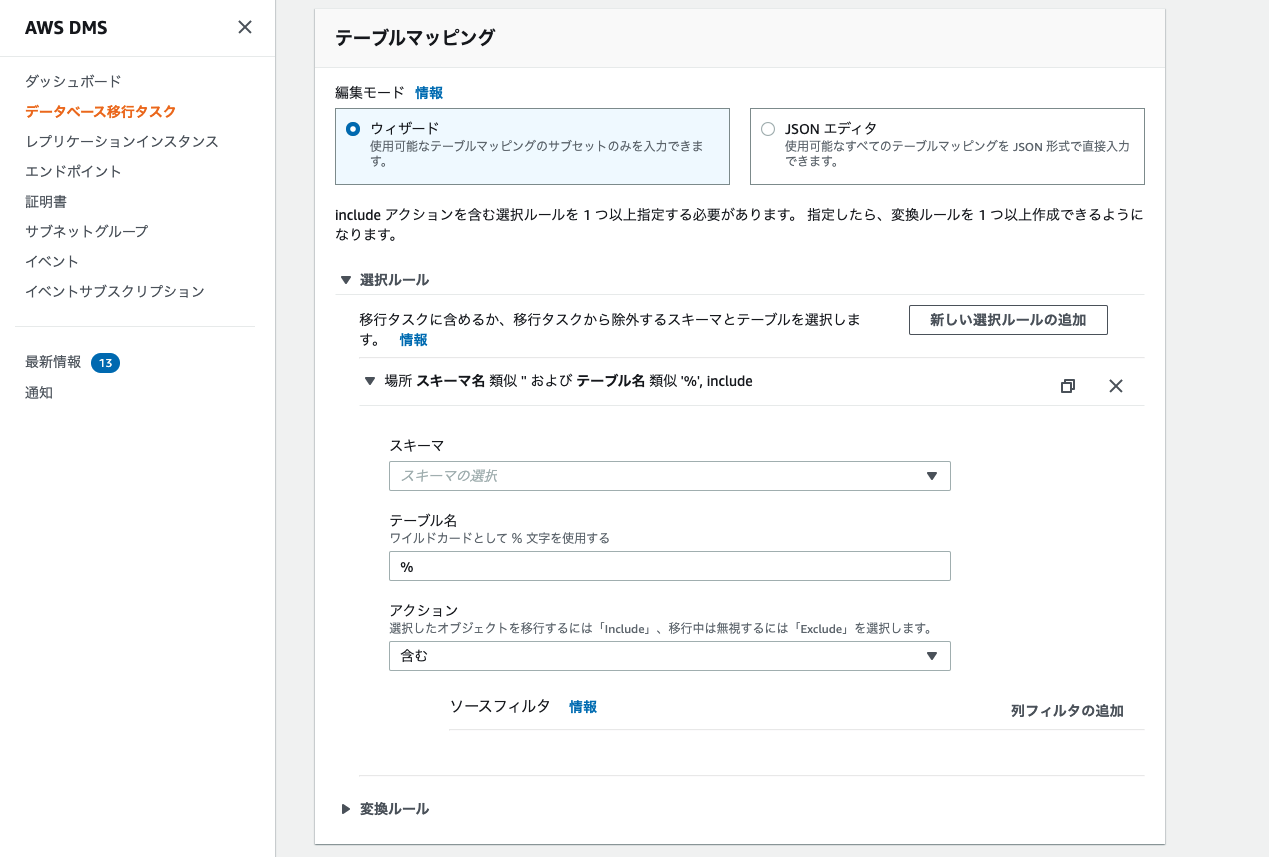
スキーマ名 ... database name
テーブル名 ... table name
スキーマとテーブルを選択することで、特定のテーブルで変更が起きた際にKafkaにデータを送るという絞り込みが可能となります。
各設定完了後「移行タスクのスタートアップ設定」で「作成時に自動的に行う」を選択していればタスクの作成と同時にCDCの処理が走り、絞り込んだテーブルに変更が発生するたびにKafkaにデータが送られます。
あとがき
最初、CDCの概念の理解やDMSのマネコン見ても はっ?( °o°) ってなった自分がいました。
私と同じような迷える子羊ちゃぁぁぁぁぁん(꒪ཀ꒪)の助けになれば幸いです。
(・ω・)ノシ