なぜ急にしりとり最短経路を解きたくなったのか?
あるシチュエーションで問題を出されたことがあり100点満点中、90点だったため悔しかったからです。
10点取れなかった理由は一時間という時間制限の中でオレオレアプローチでDFSを使って解いたのですが、
時間計算量が大きすぎてプログラムがタイムアウトしてしまいました。
(※ 当時はDFS(深さ優先探索)という単語自体知らなかった)
今なら解けるもんね!!
ということでその後、鍛錬を続けた結果該当問題でスコア100点を取れるようになったので解説を交えつつ同じような子羊たちを先導出来たらと思います。(何様)
OKわかった。どこに問題(プラットフォーム)があるんだ
ここ(paiza)にあります。
自分で考えたプログラムの著作権は自身にあるので問題ないらしいのですが、
問題文を100%コピペすると著作権に引っかかる可能性があるらしいので、要約しますね。
問題文
始点と終点の1文字(単語ではありません)をペアにして一行目に与えます。
始点文字から終点文字まで、与えられた単語リストを使いしりとり最短経路で到達してみましょう。
り つ
5
りんご
ごりら
ごりらごりら
らっぱ
ぱんつ
4
りんご ごりら らっぱ ぱんつ
inf
え、とりあえず答えを見せてって?
スコア100点だったプログラムが以下です。
後述しますが、オレオレアプローチで解いているので、
どこかから提供された回答案ではありません。
なのでサイトからの模範解答や模範的アルゴリズムではないことをご了承ください。
import java.util.*;
class Qiita {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
char startCharacter, endCharacter;
List<String> input = new ArrayList<>();
Map<String, String> parent = new HashMap<>();
while (sc.hasNextLine()) {
String str = sc.nextLine();
input.add(str);
}
sc.close();
String[] firstLine = input.get(0).split(" ");
startCharacter = firstLine[0].charAt(0);
endCharacter = firstLine[1].charAt(0);
input.remove(0);
input.remove(0);
Map<Character, List<String>> startCharDict = new HashMap<>();
for (String word : input) {
char wordHead = word.charAt(0);
startCharDict.computeIfAbsent(wordHead, ArrayList::new).add(word);
}
Queue<String> prevPath = new LinkedList<>();
List<String> startWords =
startCharDict.getOrDefault(startCharacter, Collections.emptyList());
for (String word : startWords) {
boolean visited = parent.get(word) != null;
if (visited) {
continue;
}
prevPath.add(word);
parent.put(word, "");
}
String tail = "";
// BFS
while (prevPath.size() > 0) {
String current = prevPath.remove();
char[] chars = current.toCharArray();
char wordTail = chars[chars.length - 1];
if (endCharacter == wordTail) {
String finalTail = "Game End!";
parent.put(finalTail, current);
tail = finalTail;
break;
}
if (startCharDict.get(wordTail) == null) {
continue;
}
for (String word : startCharDict.get(wordTail)) {
boolean visited = parent.get(word) != null;
if (visited) {
continue;
}
prevPath.add(word);
parent.put(word, current);
}
}
List<String> result = new ArrayList<>();
while (tail != "") {
tail = parent.get(tail);
if (tail != "") {
result.add(tail);
}
}
if (result.size() == 0) {
System.out.println("inf");
} else {
Collections.reverse(result);
System.out.println(result.size());
System.out.println(String.join(" ", result));
}
}
}
いちいち読んでる時間ない、解説して!?
公式の模範解答を覗いてみた結果の解説
※ つまり上のコードとは直接関係なし
p◯izaから期待されている解法としては、
vertices (頂点) と edges (辺) の有向グラフを作成し、ベルマンフォード法で最短経路を出すことだそうです。
以下の図だと丸がvertices (頂点)で赤色の線がedges (辺)となります。
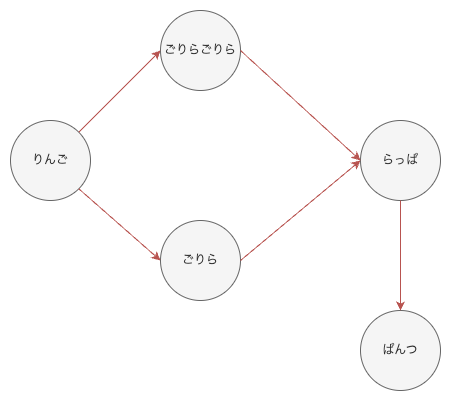
感想
ベルマンフォード法って辺に重みがないと意味がないのではないだろうかと思った。
事実上のBFSになっていそう。
ここからがオレオレアルゴリズムの解説
過去に痛い思いをした自分はとりあえず、DFSではないことだけはわかっていた。
そして有向グラフを作って欲しいんだなということも理解した。(※ただの勘)
しかしIQ3,000万Overの自分は(グラフデータの作成に慣れていない自分は) hashMapで擬似的な有向グラフ(?)を作ることで回避しようと考えた。
(※有向グラフのデータ構造を実務で使ったこと無いぞ?!)
与えられた入力から作ったデータ構造(hashMap)
単語の最初の1文字をキーとしたhashMapを作成しています。
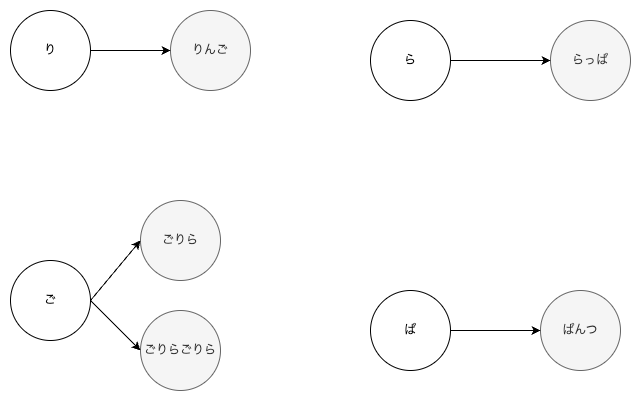
jsonで表すとこのような感じです。
{
"り": ["りんご"]
}
探索方法は?
始点単語(例:りんご)の末尾文字(例:ご)をキーにhashMapから配列を取り出し、配列の中身をすべてQueueに貯めています。
これによりBFS(幅優先探索)で探索することが可能になっています。
また、BFSでよくある訪問済みの場所はvisited変数に格納しました。
☆重要なポイント☆
単純にvisited(訪問済み)だけを記録すると訪問済みの場所はわかっても、その依存関係を解決出来ないため最短リレー数の数は出せても、しりとりとしては完成しません。
ちなみに、一般的なBFSでのvisited変数の中身をjsonで表すとこうです。
{
"りんご": true,
"ごりら": true
}
この問題を解決するアプローチとして、経路元をValue、経路先をKeyとして単語をhashMapの形式で格納しようと考えました。
見やすいようjavascriptで表すとこうです。
const visited = {
"ぱんつ": "らっぱ",
"らっぱ": "ごりら",
"ごりら": "りんご"
};
console.log(visited["ぱんつ"]); // らっぱ
console.log(visited[visited["ぱんつ"]]); // ごりら
最終単語はloopをbreakしたタイミングで拾えるため、最終単語からvisitedが探索できなくなるまでloopすることにより、逆順のしりとりが完成します。
あとはそれをreverse関数で反転させればあ〜ら不思議☆しりとり最短経路の完成です。
あとがき
このQiitaを書くためだけにp◯izaに会員登録したんですが、設問を解くためにはチケットというものを消費する必要があるらしく、なんだかソシャゲっぽいなと思いました。
※ チケット自体は購入できなそう (しらんですけど