記事を書こうと思った理由
僕自身が初心者ということもありますが、 tensorflow-gpuのインストールに手こずった(特に、GPUの認識周り)ので、残すために書いてたりします。また他の人が詰まったりしたときに参考になればな、と思います。
今回の環境
- Ubuntu 16.04 LTS
- GCE
- CUDA 9.0
- cuNN 7.4
ハマりポイントその1(コンソールから立ち上げたVMインスタンスはGPU認識しない)
実は、Googleのコンソール画面からGPUインスタンスの起動ができない。
これけっこうハマりましたね。最初、コンソールでインスタンス起動してたんですけど、ドライバーなどをインストールしても、GPUが認識されないんですよね。
cloudって言うこともあってちゃんとGPUが刺さっている状態になっているのか、という判断ができないんですよ。エラー出ていたときは、バージョンのエラーかなぁ、位にしか思っていませんでした。
認識できなかったときに出てきていたエラーはこちら。
$ nvidia-smi
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running."
Ubuntuでnvidiaドライバーが動作しないを参考にしてみましたが、この記事の通りに行ってもだめでした。
当然その理由は先程も述べたように、そもそもGPUインスタンスの立ち上げ方を間違えていました。
まずはGPUインスタンスをしっかり立ち上げるところから始めましょう。
$ gcloud beta compute instances create {GPU_INSTANCE_NAME} \
--machine-type n1-standard-2 --zone {ZONE_NAME} \
--boot-disk-size 30GB \
--accelerator type=nvidia-tesla-k80,count=2 \
--image-family ubuntu-1604-lts --image-project ubuntu-os-cloud \
--maintenance-policy TERMINATE --restart-on-failure \
--metadata startup-script='#!/bin/bash
# Install CUDA
if ! dpkg-query -W cuda; then
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
dpkg -i ./cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
apt-get update
apt-get install cuda -y
fi'
ハマりポイント2、3、4は縁のない人にはないので、見出しだけ見て、良さそうなら、スキップしてくださいw
ハマりポイント2(Compute Engine APIの上限が0)

上限が0の場合はこれを割り当ててあげましょう。
もしこのままハマりポイント1で紹介したコマンドを叩くと、
ERROR: (gcloud.compute.instances.create) Could not fetch resource:
- Quota 'GPUS_ALL_REGIONS' exceeded. Limit: 0.0 globally.
と出力され、作成できません。
これもハマりましたね。GPU割り当ててるのになぁと思いながら設定確認してました。
実際は見てるサービスが違いましたね。もう少しエラー文なんとかならないのか…
ハマりポイント3 (インスタンスを立てるゾーンにGPUが割り当てられていない)
こちらの問題、特に問題ありませんでしたが、一応載せておきます。
--accelerator type=nvidia-tesla-k80,count=2こちらのオプションで指定しているGPUですが、実は割り当てられている数が決まっています。その上限を超える場合は、Googleに上限解放申請を出す必要があります。
割り当てられている数は次のコマンドで確認できます。
$ gcloud beta compute regions describe {REGION_NAME}
(略)
- limit: 1.0
metric: NVIDIA_K80_GPUS
usage: 0.0
(略)
先程のコマンドを叩くと、Limit: 1.0というエラーが出ます。
この場合は、GCPのコンソールの「IAMと管理」 > 「割り当て」から「NVIDIA K80 GPUs」にチェックを入れて、「割り当てを編集」をクリックして上限解放リクエストを送りましょう。あるいは、GPU一個だけ割り当てる(count=1)。リクエストの承認は、場合によってはちょっと時間がかかります。(メールには2営業日以内という文面がありますが、早いときは20分位で来ます)
メールの内容はこちら(一部抜粋)。
Changed Quota:
+--------------------+-----------------+
| Region: asia-east1 | NVIDIA_K80_GPUS |
+--------------------+-----------------+
| Changes | 1 -> 8 |
+--------------------+-----------------+
ハマりポイント4 (ディスク容量枯渇)
ディスク容量には気をつけましょう。
先程のコマンドは動作確認済みのコマンドなので問題ないですが、最初僕が実行したコマンドでは、--boot-disk-sizeが抜けてました。
これが抜けていると、ライブラリのインストールを行おとしたときにディスク容量が足りないのでインストールできないよ!って怒られます。(デフォが10GB)
Could not install packages due to an EnvironmentError: [Errno 28] No space left on device
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 3.7G 0 3.7G 0% /dev
tmpfs 748M 8.6M 739M 2% /run
/dev/sda1 9.7G 9.5G 166M 99% /
tmpfs 3.7G 0 3.7G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 3.7G 0 3.7G 0% /sys/fs/cgroup
tmpfs 748M 0 748M 0% /run/user/1001
そうなったときは仕方ないので、ディスクをマウントしてあげましょう。
自分は30GBに増量しました。
マウントの方法はこちらの記事が参考になります。
割り当て後↓↓
df -h
Filesystem Size Used Avail Use% Mounted on
udev 3.7G 0 3.7G 0% /dev
tmpfs 748M 8.6M 739M 2% /run
/dev/sda1 30G 9.5G 20G 33% /
tmpfs 3.7G 0 3.7G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 3.7G 0 3.7G 0% /sys/fs/cgroup
tmpfs 748M 0 748M 0% /run/user/1001
ここまでが、一通り僕が立ち止まったエラーでした。
次から、早速インストール勧めていきます。
GPU認識確認
GPUインスタンスが立ち上がったら、まずは、CUDAの設定を行いましょう。
$ echo "export PATH=/usr/local/cuda-9.0/bin\${PATH:+:\${PATH}}" >> ~/.bashrc
$ source ~/.bashrc
$ sudo /usr/bin/nvidia-persistenced
その後、GPUが認識されているかを確認します。
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.72 Driver Version: 410.72 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 42C P0 65W / 149W | 0MiB / 11441MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
これが出ていればOKです。
cuDNNのインストール
https://developer.nvidia.com/rdp/cudnn-download
ログインが必要ですが、ログイン後に、
CUDA 9.0と表示されているcuDNNを選択します。
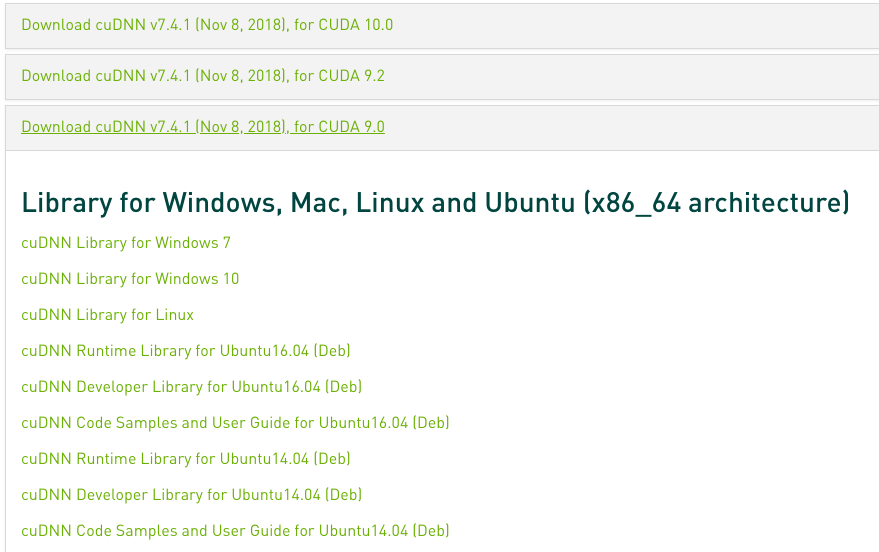
この中の、
- cuDNN Runtime Library for Ubuntu16.04 (Deb)
- cuDNN Developer Library for Ubuntu16.04 (Deb)
- cuDNN Code Samples and User Guide for Ubuntu16.04 (Deb)
をローカルPCにダウンロードしてください。
wgetでダウンロードしたいんですけど、ログインが必要なので、できません…。
次に、GCPのインスタンスの方へアップロードします。
一応、SCPコマンドのリンクを載せておきます。
$ gcloud compute scp {DOWNLOAD_PATH} {GPU_INSTANCE_NAME}:{UPLOAD_PATH}
{}の中身は適宜変更してください。
アップロード完了したら、PGUインスタンスにログインして、アップロードしたディレクトリ内で、次のコマンドを実行します。
$ sudo dpkg -i *.deb
これでGPU周りのセットアップは終わりました。
Python環境の構築
Anacondaでやりましょう。
https://www.anaconda.com/download/#linux
こちらのリンクから、アナコンダダウンロードしてください。
$ wget https://repo.anaconda.com/archive/Anaconda3-5.3.1-Linux-x86_64.sh
$ sh ./Anaconda3-5.3.1-Linux-x86_64.sh
$ echo ". /home/{USER_NAME}/anaconda3/etc/profile.d/conda.sh" >> ~/.bashrc
$ source ~/.bashrc
このままではPython3.7を使うことになるので、Python 3.6にして、py36という名前で設定します。
$ conda create -n py36 python=3.6
$ conda activate py36
これでpython 3.6の環境になりました。
あとは、tensorflow-gpuを入れてテストして終わりです。
tensorflow-gpuのインストール
$ pip install --upgrade pip
$ pip install tensorflow-gpu
tensorflowがちゃんとGPUを使ってくれるのかテスト
TensorflowGPU 動作確認用スクリプト
をもとに行いました。
ちなみに僕の環境下ではこうなりました。
2018-11-29 15:52:08.355118: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:964] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2018-11-29 15:52:08.360279: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 0 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:00:04.0
totalMemory: 11.17GiB freeMemory: 11.09GiB
2018-11-29 15:52:08.360336: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0
2018-11-29 15:52:19.393952: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-11-29 15:52:19.394032: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0
2018-11-29 15:52:19.394042: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N
2018-11-29 15:52:19.394423: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10744 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7)
[[22. 28.]
[49. 64.]]
まとめ
これ動かすまでに2日かかりました…
何度か潰して、また立ち上げてを繰り返して、ようやくです。
感想としては、クラウド楽だけど大変だなぁっ感じですねww