概要
Azure Machine Learning を利用するにあたり、ほぼ必ずつまずくのが、どのように予測精度を高められるか?です。
そこで今回はCortana Intelligence Suiteを構築(第6回)で構築した、Azure Machine Learning環境を使って、機械学習モデルの精度を向上させてみます。
事前に準備するもの
- Azure サブスクリプション
- Cortana Intelligence Suiteを構築(第6回)で作成したAzure Machine Learning環境
予測精度を高めよう!
カスタムモジュールの「Generate Lag Data」を利用して、過去のレコードからのトレンドデータを生成する
1分前の遅延時間、5分前の遅延時間、20分前の遅延時間、といった形で過去のデータを列として追加することで、予測する基準を過去のデータも対象とし、より精度の高い分析ができるようになります。ただ、通常このようなデータを生成するにはR言語を理解している必要がありますが、今回はR言語を理解していなくても生成する方法、「Custom Module(カスタムモジュール)」機能を利用します。
「New」>「Module」>「Generate Lag Features」を選択し、「Import Module」をクリックします。
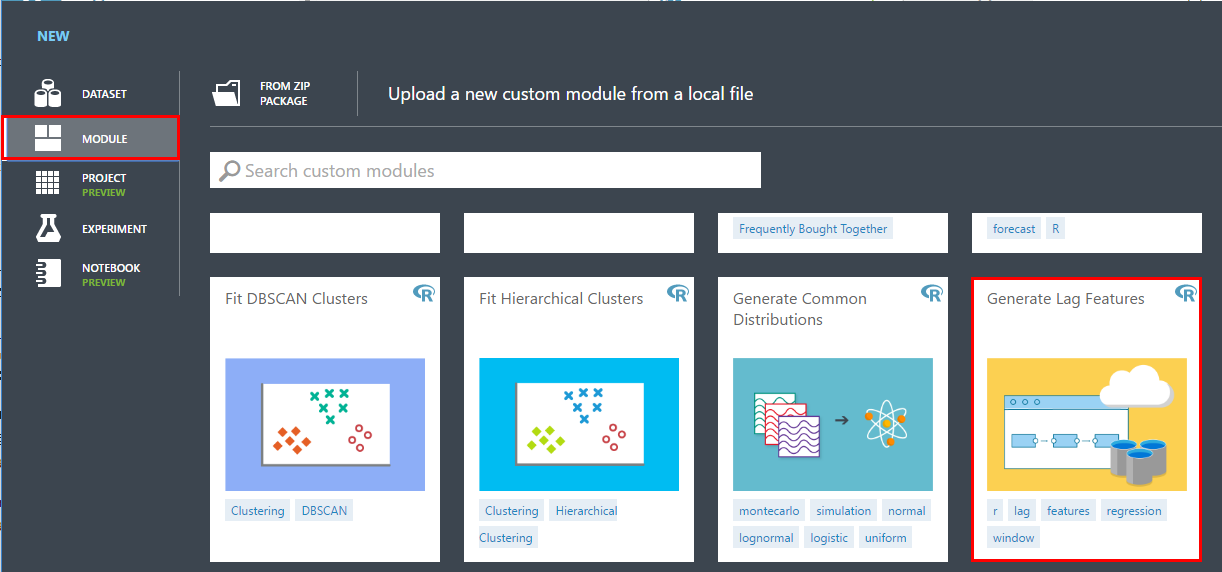
「Import completed」と表示されます。これで、このカスタムモジュールが追加されたことを意味します。

追加したカスタムモジュールは、「Custom」の中にあります。これを、前回作成した機械学習モデルの、「Select Columns in Dataset」と「Split data」の間に入れます。
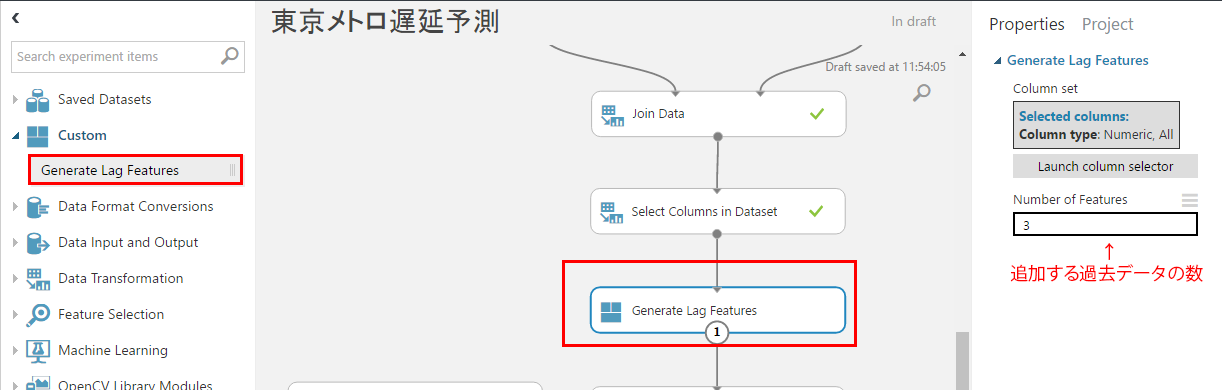
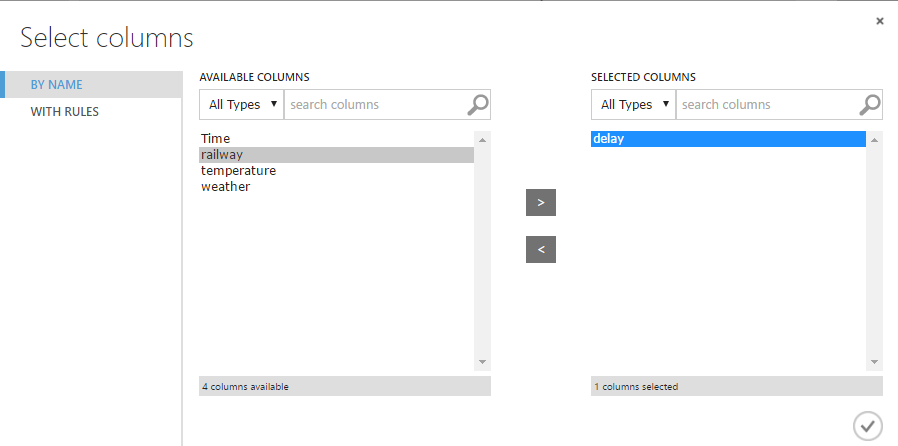
過去データを生成する対象の例は、「Delay」のみにします。「Number of Features」は過去データの生成数なので、10と指定して、過去10回分のデータ(今回のモデルですと、10分前まで)のデータを追加しましょう。
これで一旦「Run」で実行して、精度が上がるか見てみましょう。
前回の結果: Coeffient of Determinationは0.358655でした。
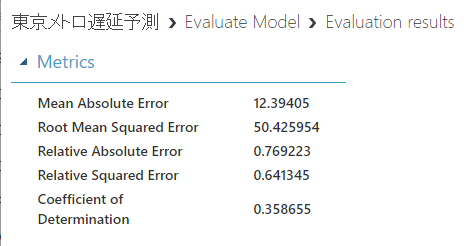
今回の結果:Coeffient of Determinationは0.65676ということで、精度が大幅に向上していることが確認できましたね!
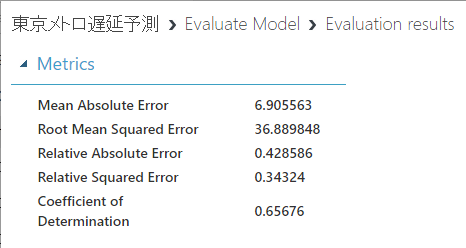
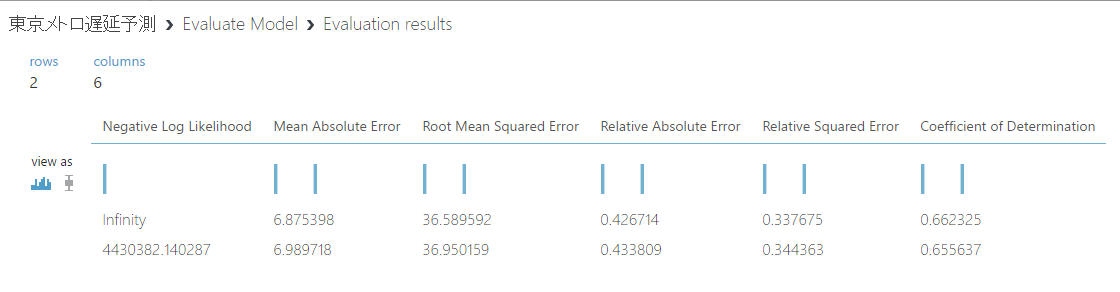
「Number of Features」を20にしてみると・・・Coeffient of Determinationは0.662325なので、これ以上はあまり精度はあがりそうにないですね…
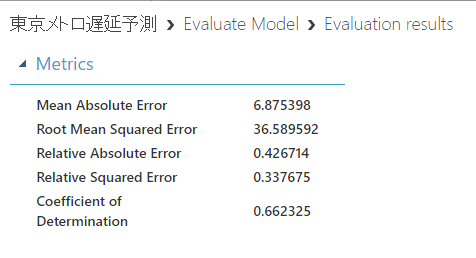
ということで、次は「Boosted Decision Tree Regression」というモデルを利用することがそもそも根本的に正しいのか検証してみましょう。
Evaluate Modelを最大限に活用して、一番最適な予測モデルを利用する
今までのステップでは、「Boosted Decision Tree Regression」を利用してきましたが、「Regression(回帰)」モデルはそれ以外にも、いろいろあるので、実際に複数のアルゴリズムを利用して、どれが最適なモデルかを検証してみます。
検証するには、1から新たに実験を作る必要はありません。前回作成した実験に付け加えることができます。まず、「Train Model」と「Score Model」を範囲選択して、コピーします。
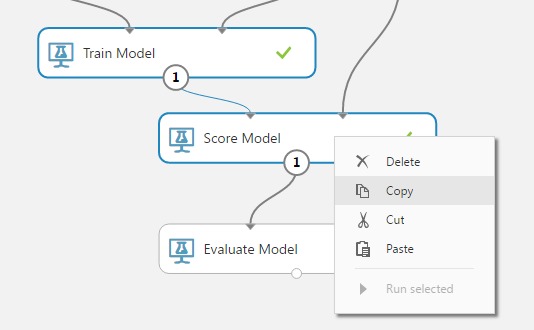
あとは貼り付けて、つなげるだけです。出力は、複数設定することができるようになっていますので、既にほかのモジュールとつながっていても問題ありません。
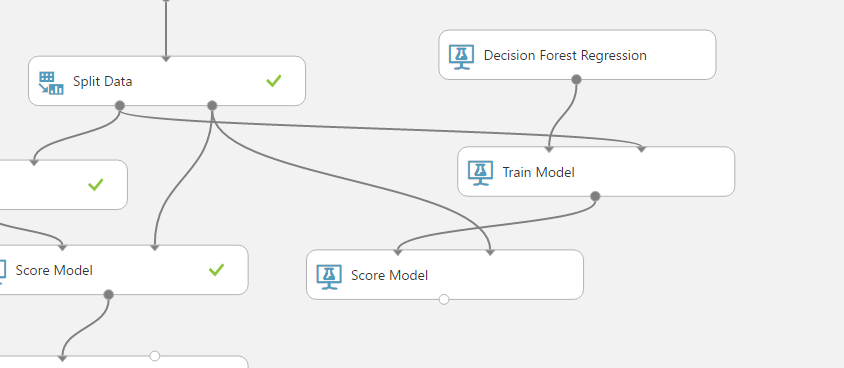
それでは、既存の「Evaluate Model」へ接続して、比較してみましょう。
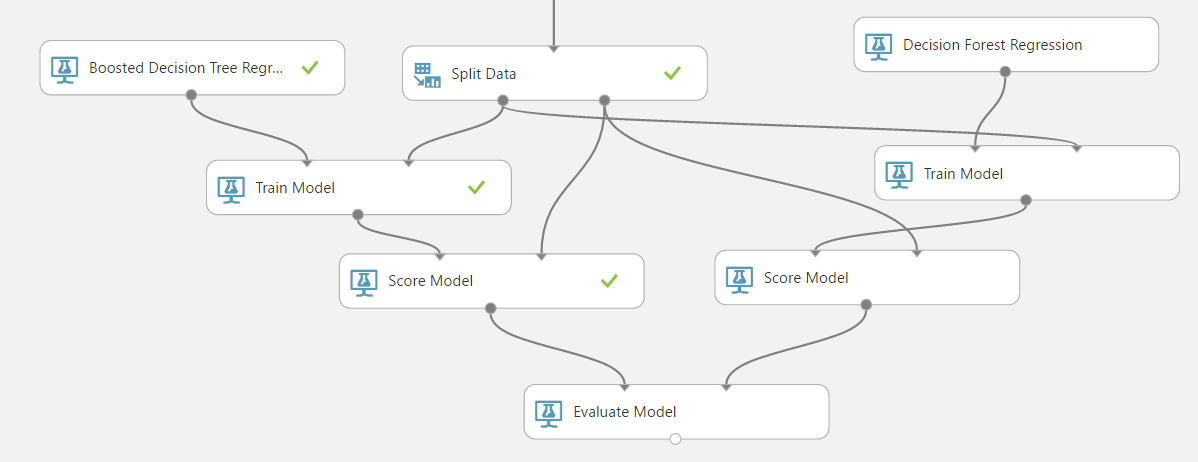
結果が2行表示されています。1行目が左側(Boosted Decision Tree Regression)の結果で、2行目が右側(Decision Forest Regression)です。結果、「Boosted Decision Tree Regression」の方が、精度が高いようです。
他のモデルでも試してみました。
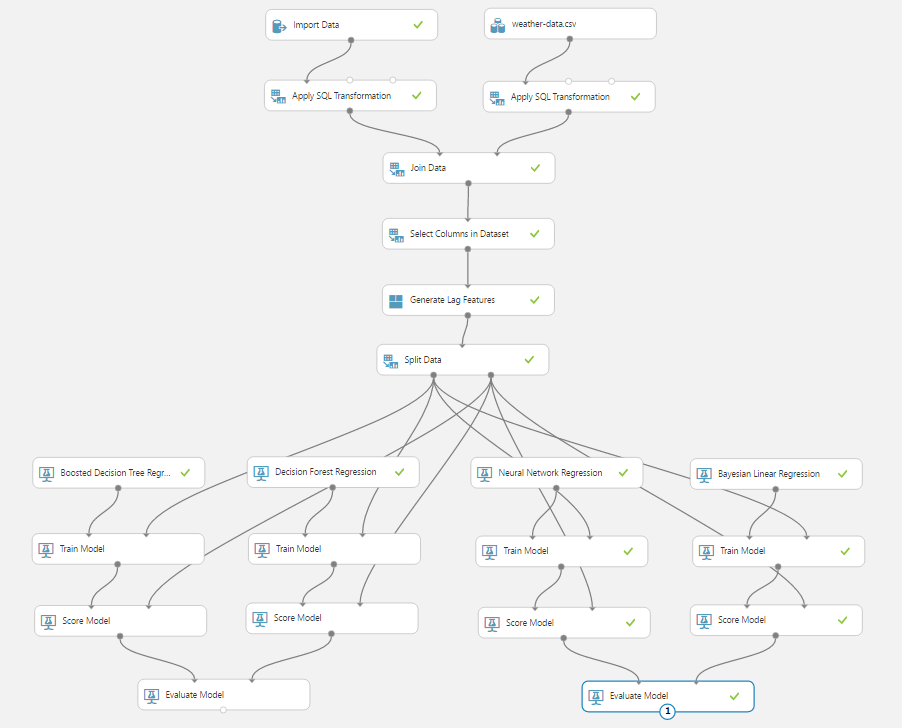
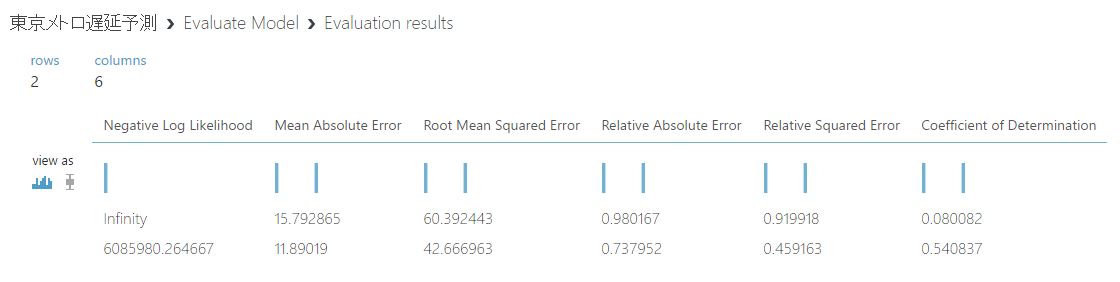
左側(Neural Network Regression)も、右側(Bayesian Linear Regression)も「Boosted Decision Tree Regression」と比べると、より精度が低い結果となりました。次に「Boosted Decision Tree Regression」の精度を高めてみます。
「Tune Hyper Parameter」を利用して、適切なパラメータを設定する
今のところ、各アルゴリズムは既定のパラメータを利用して、実験しているため、最適化されていません。ただし、どのパラメータを変更すればいいのかは、データサイエンティストでもないので難しそう…そういう時に利用するモジュールが、「Tune Hyper Parameter」です。このモジュールは、適当に何個かのパラメータを用意し、それぞれの組み合わせで試した後、一番精度の高かったパラメータの組み合わせを学習モデルとして利用できるようになっています。
手順は1ステップです。「Train Model」のモジュールを「Tune Model Hyperparameters」と置換すれば、利用できます。
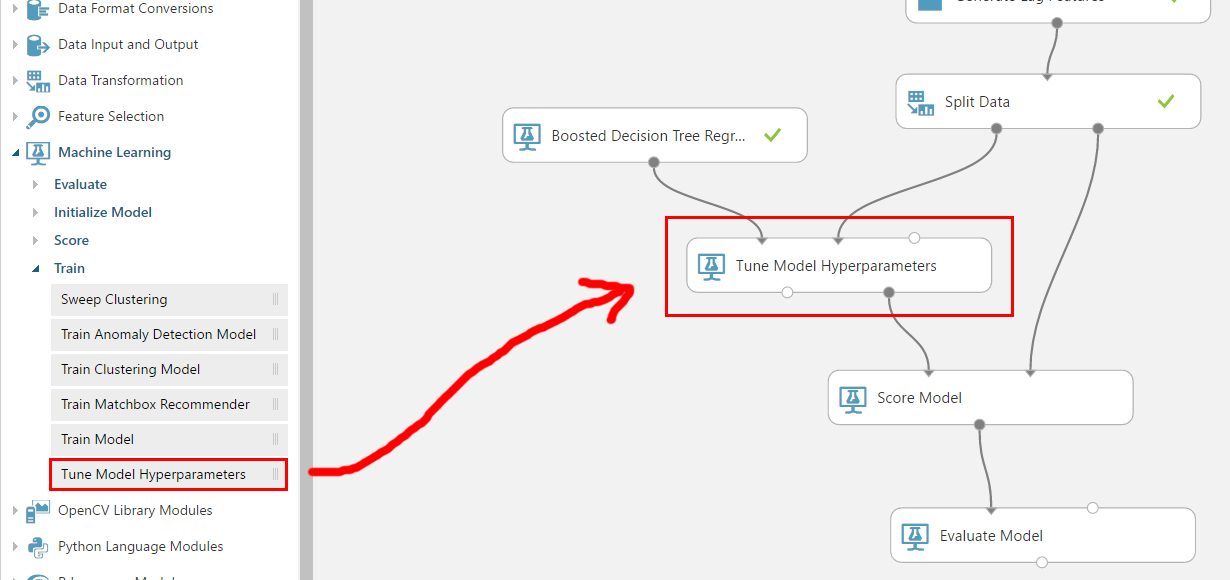
「Maximum number of runs...」が試すパラメータの組み合わせの数です。値が高ければ高いほど色んな組み合わせが試されるため、精度が上がる可能性が高まりますが、その分実行回数も多いため、結果を得られるまでの時間が長くなります。
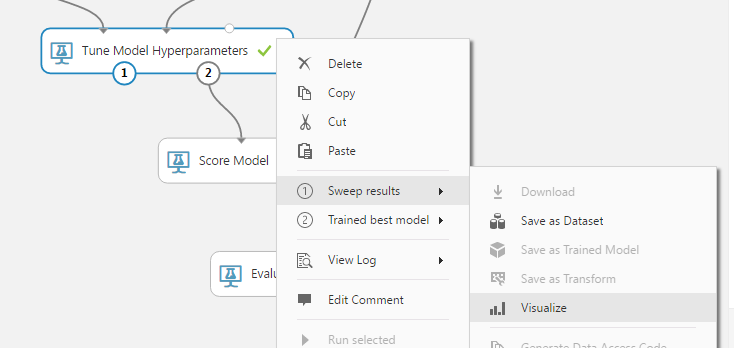
実際に10種類の組み合わせで試してみました。各組合せの結果は「Tune Model Hyperparameters」を右クリックし、「Sweep Results」>「Visualize」で確認できます。
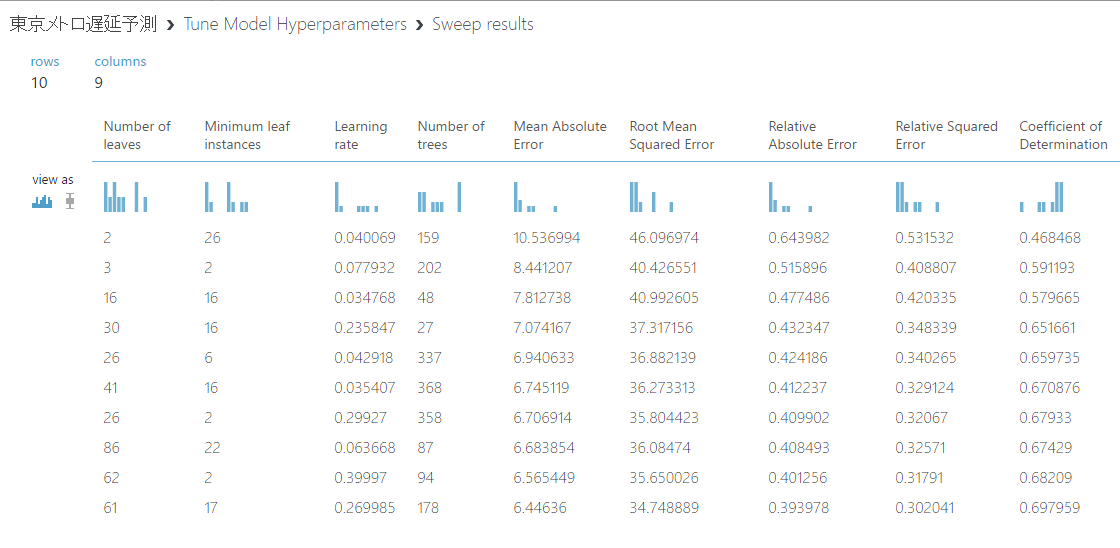
ここで表示されるのは、あくまでもサンプルで試した際の結果ですが、「0.697959」まで向上していますね!
「Evaluate Model」で確認してみましょう。
Tune Model Hyperparameters利用前:
Tune Model Hyperparameters利用後:
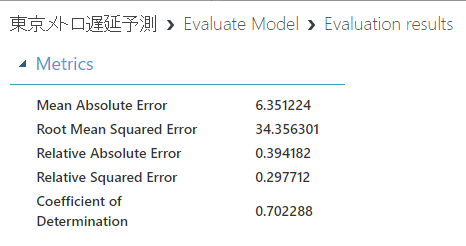
4%も向上しました!次回はWebサービス化&リアルタイム処理(Stream Analytics)で利用する方法をご紹介します。お楽しみに!