BioinfoにおけるPandas,Matplotlibの基礎
この記事は、Pythonで実践 生命科学データの機械学習 (https://www.yodosha.co.jp/yodobook/book/9784758122634/) の内容を含んでいます。
私は現在バイオインフォマティクス研究室に所属する学生です。
勉強した事をアウトプットする場として用いていますため、何卒ご理解のほどよろしくお願いします(>人<;)
Pandasの基礎1
まずは得られたデータの基本情報を知る必要がある。
その際に役立つコードを箇条書きしていく。
#データの最初の5行の表示
ファイル名.head()
#データの行数、列数を確認する
ファイル名.shape
#データ型を確認する.
ファイル名.dtypes
#カラム名を取得する
ファイル名.columns
#(リストで取得したい場合にはselected.columns.valuesとする)
また、行数、データ型、カラム名を同時に取得するには、
selected.info()
こっちの方が便利そうではある。
たまに、数値的はデータだけではなく、文字型(object)のものもある。例えばHigh, Moderate,Lowなどの三択での収集データも中にはある。
もし一つの選択肢のデータ数が極端に少ない、または多いと、ユニークなデータとなり、欠損値になるため、予め調べる必要がある。
# ユニークな値を把握する
factor=ファイル名['調べたい列の名前'].unique()
print(factor)
print(ファイル名['調べたい列の名前'].value_counts())
統計量はdescribe()で取得できる。文字列のデータは自動的に除外される。
ファイル名.describe()
Pandasの基礎2 ~データ整形~
1.欠損値の取り扱い
はじめに欠損値の確認を行う。
import pandas as pd
# サンプルデータ作成
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', None],
'Age': [25, 30, None, 40, 29],
'Gender': ['Female', None, 'Male', 'Male', 'Female']
}
selected = pd.DataFrame(data)
# 欠損値の数を確認
print(selected.isnull().sum())
#出力結果
Name 1
Age 1
Gender 1
dtype: int64
2.欠損値を含むデータを削除する
import pandas as pd
# サンプルデータ作成
data = {
'Name': ['Alice', 'Bob', None, 'David', 'Eve'],
'Age': [25, 30, None, 40, 29],
'Gender': ['Female', None, 'Male', 'Male', 'Female']
}
selected = pd.DataFrame(data)
print("元のデータフレーム:")
print(selected)
このサンプルデータの欠損値を含む行を削除する場合は、
# コピーして削除
deleted = selected.copy()
deleted.dropna(inplace=True)
print("\n欠損値を削除したデータフレーム:")
print(deleted)
#出力結果
元のデータフレーム:
Name Age Gender
0 Alice 25.0 Female
1 Bob 30.0 None
2 None NaN Male
3 David 40.0 Male
4 Eve 29.0 Female
欠損値を削除したデータフレーム:
Name Age Gender
0 Alice 25.0 Female
3 David 40.0 Male
4 Eve 29.0 Female
注意点
欠損値の削除条件
デフォルトでは、1つでも欠損値がある行が削除されます。
特定の列のみを基準に削除したい場合は、subset 引数を使用します:
deleted.dropna(subset=['Age'], inplace=True)
列を削除したい場合
行ではなく、欠損値を含む列を削除したい場合は axis=1 を指定します:
deleted.dropna(axis=1, inplace=True)
Matplotlibの基礎
主にデータの可視化の際に用いられるツールであり、基本的にはMatplotlibの公式がチートシートを公開している。
個人的には以下の記事が全て網羅されており大変使いやすいと感じた。
次に実践的な演習で得られた知識について挙げていく。
1.usecols
データを読み込む際に特定の列のみを指定して取り込むために利用される。
import pandas as pd
# sample.csv の "Name" と "Age" 列のみ読み込み
df = pd.read_csv("sample.csv", usecols=["Name", "Age"])
print(df)
# sample.csv の 1列目と3列目のみ読み込み
df = pd.read_csv("sample.csv", usecols=[0, 2])
print(df)
# 列名に "id" を含む列だけを選択
df = pd.read_csv("sample.csv", usecols=lambda col: "id" in col)
print(df)
2.encoding
ファイルの文字エンコーディング(文字コード)を指定するための引数です。エンコーディングを指定しないと、デフォルトのエンコーディング(通常はUTF-8)が使用されますが、文字化けが起きる場合に明示的に指定することで解決できます。
import pandas as pd
# Shift-JISエンコーディングのCSVファイルを読み込む
df = pd.read_csv("data.csv", encoding="shift_jis")
print(df)
3.map()
例えば陽性or陰性などのobjectのデータ型があったとする。これを1or0の変換を行わないといけない。
import pandas as pd
# サンプルデータ
data = {
'fluA_status': ['Positive', 'Negative', 'Positive', 'Unknown']
}
breast = pd.DataFrame(data)
print(breast)
#出力結果
fluA_status
0 Positive
1 Negative
2 Positive
3 Unknown
このように、インフルエンザA型のデータに陰性陽性のリストがあったとする。
#変換コード
class_fluA = {'Positive': 1, 'Negative': 0}
breast['fluA_status'] = breast['fluA_status'].map(class_fluA)
print(breast)
#出力結果
fluA_status
0 1.0
1 0.0
2 1.0
3 NaN
このようにして変換ができる。
陽性陰性でデータを分割する際の方法
positive = breast.loc[breast['FluA_status']==1]
negative = breast.loc[breast['FluA_status']==0]
論文や学会で用いるような綺麗な図を描くのはMatplotlibでは大変なため、Seabornがおすすめ
この方の記事が大変丁寧に解説されていた。
4.ydata-profiling
データはなんとなく集まったけど、どこから進めていけばいいのかわからない、、、
そんな時にはydata-profilingを使ってデータの全体像や簡単な統計値を知ることができる。
pip install pandas ydata-profiling
# 必要なライブラリをインポート
import pandas as pd
from ydata_profiling import ProfileReport
# サンプルデータの作成
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 40, None],
'Gender': ['Female', 'Male', 'Male', 'Male', 'Female'],
'Income': [50000, 60000, 75000, 80000, 120000],
'Married': [False, True, True, False, True],
'Score': [85.5, 90.2, 88.0, 72.5, 95.0]
}
# データフレームに変換
selected = pd.DataFrame(data)
# データ確認
print("サンプルデータ:")
print(selected)
# プロファイリングレポートの生成
report = ProfileReport(selected, title="Sample Data Profiling Report")
# レポートをHTMLファイルに出力
report.to_file("sample_profile_report.html")
print("プロファイリングレポートが 'sample_profile_report.html' として保存されました。")
sample_profile_report.htmlをDLして開くと、このような表示がされる。
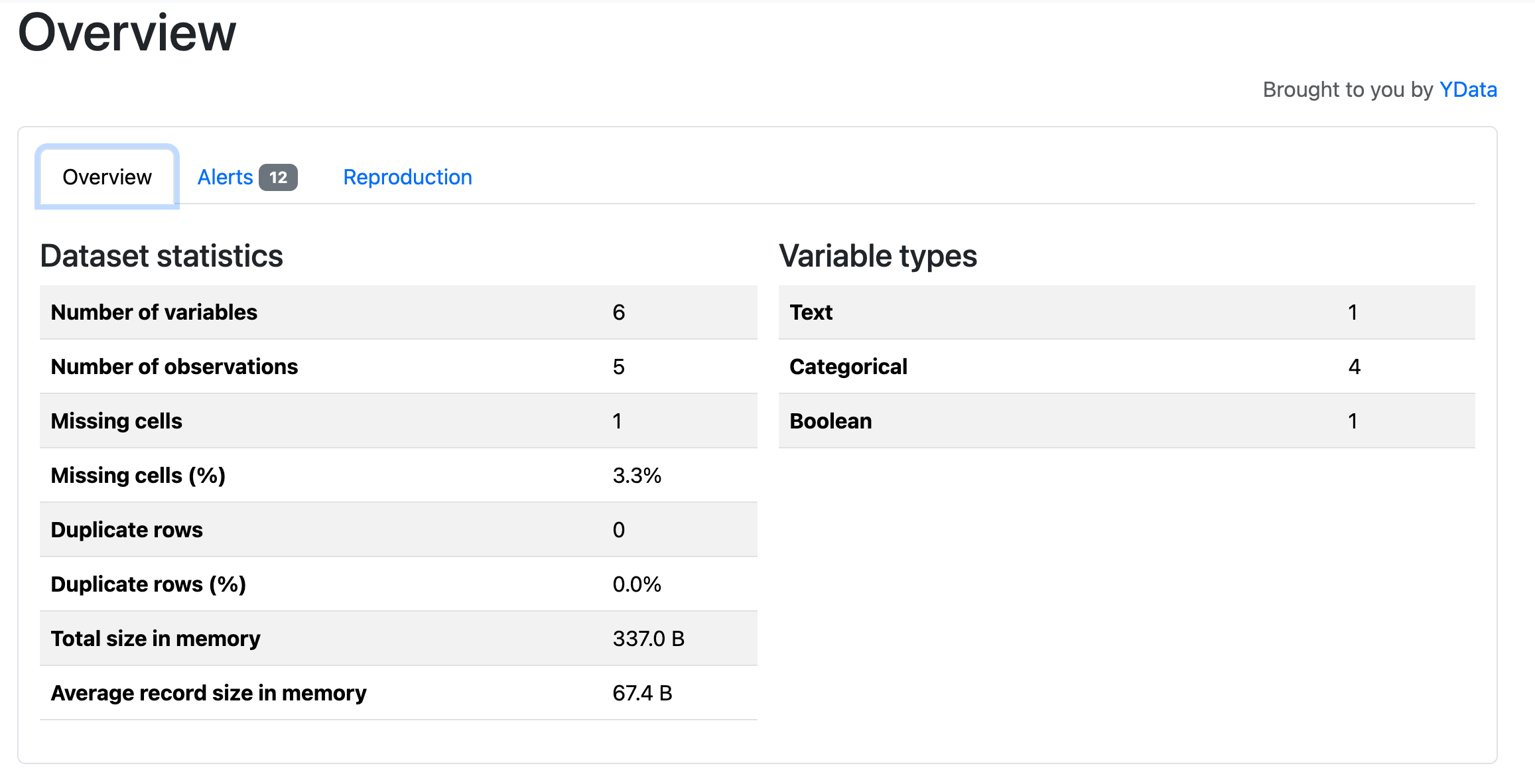
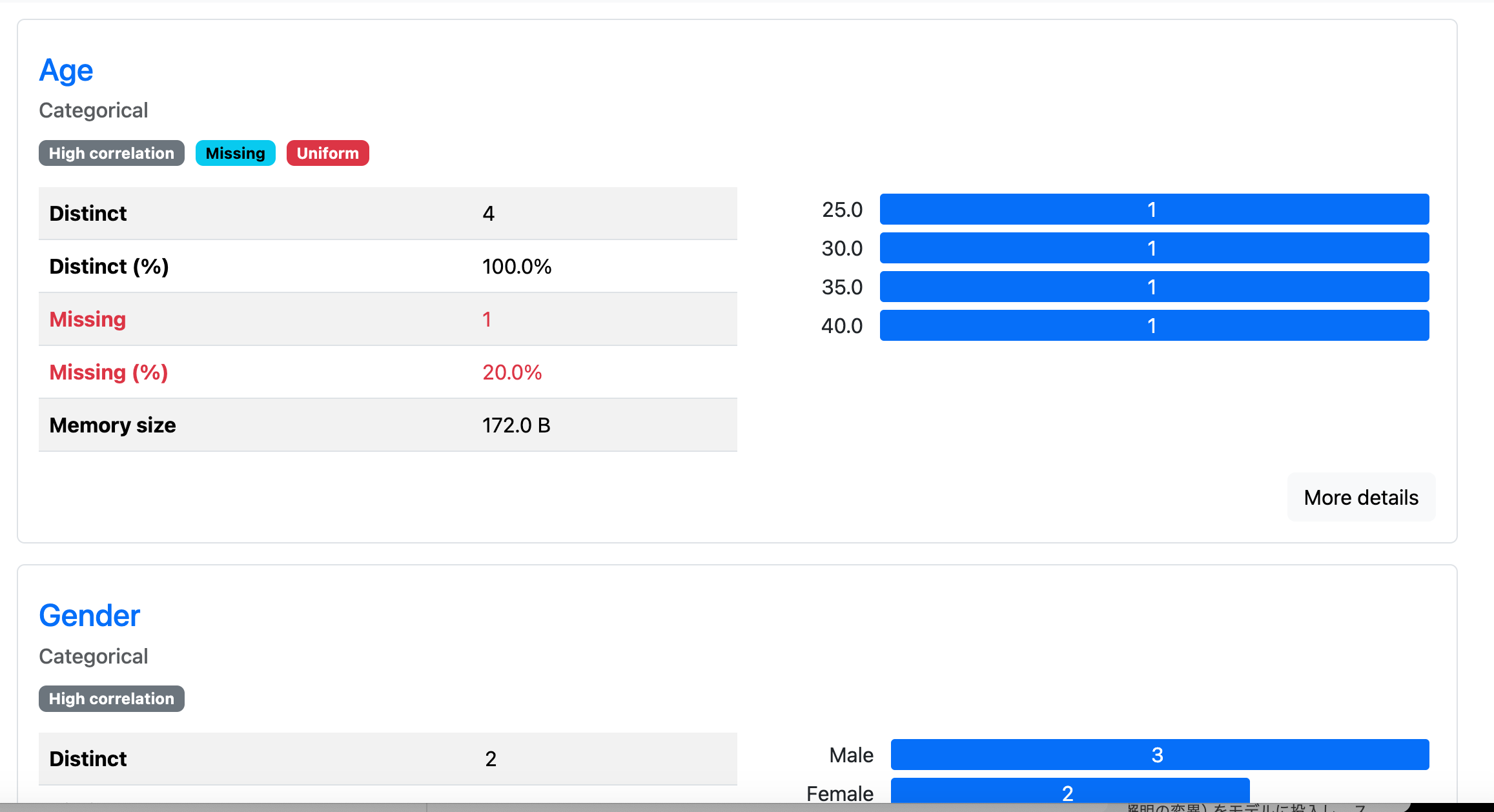
各列のデータを要約して統計量なども示してくれる、非常に使い勝手のいいものとなっている。