先日、JavaScriptファイルのロード中に、循環importによる初期化エラーが出て困ったので、図をつくって可視化してみました。
生成物は一番下にあります。
JavaScriptにおける他ファイル参照
ブラウザ上で動くJavaScriptコードを書くうえでは、奇妙な制約が多々あります。
言語自体が奇妙な場合も多いですが(本当に多い!)、他ファイルのimport的な機能は、もともと「ブラウザが通信してソースファイルをダウンロードしないといけない」という都合もあるため、なかなかに無茶な仕組みになっています。
そもそも最近までimport自体が存在しなかったので、適当なライブラリで専用の記法を使うか、トランスパイラで糖衣構文に変換するという手法が用いられています。
2015年のECMAScript2015(ES6)でようやくimportという構文が仕様に入りましたが、今のところどのブラウザもサポートしていないので、状況は変わっていません。
変換後の読み込み方法は、大まかに次の2つに分けられます。
- 全ファイルを一つにまとめる(Browserify、Webpackなど)
- スクリプト実行中に他のファイルを読み込む(RequireJS、SystemJSなど)
多くの場合これらのライブラリは強力で、何も考えずにimportを並べておいても、何も考えずに参照先の定義を使えます。
なぜ読み込みに失敗するのか?
循環参照で読み込みに失敗するのは、次の条件がそろった場合です。
- ファイルAがファイルBをimportしている
- ファイルBの初期化にファイルAの内容が使われている(ファイルBのクラスがAのクラスを継承している場合など)
- ファイルAが先にimportされている
これらを満たすのは次のようなケースです。
// A.js
import B from "./B";
export default class A {
method() {
new B();
}
}
// B.js
import A from "./A";
export default class B extends A {
}
// index.js
import A from "./A";
new A().method();
図で表すとこうです。これでAを先にインポートすると落ちます。
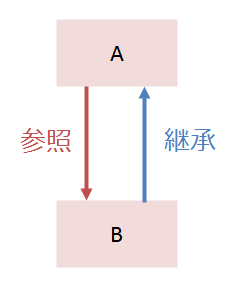
適当にコンパイル等してindex.jsを実行しようとすると、
TypeError: Class extends value undefined is not a function or null
あるいは
TypeError: Object prototype may only be an Object or null: undefined
などと言われると思います。Browserify(+Babelify)、Webpack、TypeScript+RequireJS、TypeScript+SystemJSを試しましたが、どれもエラーが出ます。このときの処理の流れは、
- indexを読み込み
- indexには
import Aと書いてあるのでindexを中断してAを読み込み - Aには
import Bと書いてあるのでAを中断してBを読み込み - Bには
import Aと書いてあるが、Aはさっき読み込みをしたので オブジェクトAがあるものとしてBを読み込み - 実はAの読み込みは終わっておらず、オブジェクトAはundefinedだったので、Bのプロトタイプに設定できずエラー
のようなものになっています。
Aの読み込みを始めるよりも前にBの読み込みを開始していれば、上の4.が起きなくなるので、エラーなく読み込みに成功します。
プロジェクトが大きいとき
さて、「Aの読み込みを始めるよりも前にBの読み込みを開始」するように書き換えるのはとても大変です。
今回対象にするのは300ファイル程度ですが、そもそもなんでBがAより先に読み込まれているのか、どこでimport順を変えればいいのかがわかりません(循環参照のエラーでは、変更箇所とは全然関係のないファイルで突然エラーが出ることもざらです)。
このためだけに無駄なimportを増やすのも、あとで収拾がつかなくなりそうです。(未使用変数はコンパイルオプションで禁じています。)
しかも、いつ再発するかもわかりません。
ひとまず、現在の状況を可視化できたら対策も考えやすいな・・・。でも何百ファイルもあって大変だな・・・。
大変なことはコンピュータにやらせましょう。
やりたいこと
JavaScriptファイル群を読み込んで、上のように参照関係を示した図を作ります。
循環を見つけてテキストで出力するだけだと、次のような循環のときに大量の循環が見つかって訳がわからなくなるので、図がいいです。
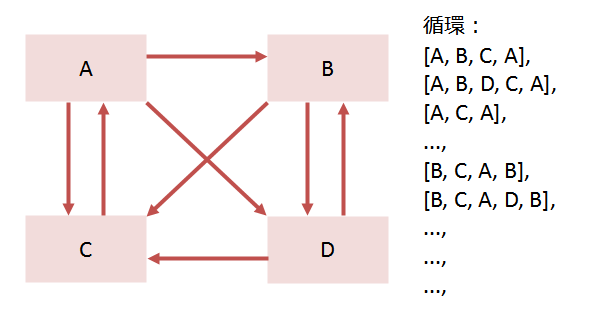
また、数百~数千ファイルある場合を考えると、循環に関係ないものは極力出力したくないです。なので、全ファイルの全依存を出力するMaDGe等はイマイチです。
以上でやりたいことが固まりました。
ファイルから有向グラフを生成して、強連結成分分解した結果を成分ごとに図に出力します。
有向グラフの強連結成分分解
任意の2点を結ぶ道が存在するような部分グラフは強連結成分(Strongly Connected Component、SCC)と呼ばれます。
つまり、強連結成分の中ではどの2点の間にも、循環する道(=閉路)が存在します。
この中に継承関係が含まれていると、上の読み込みエラーが起こりうると言えます。
有向グラフから強連結成分を取り出すアルゴリズムは、強連結成分分解と呼ばれていて、Kosarajuの手法やTarjanの手法などが知られています。
- Kosaraju's algorithm - Wikipedia (en)
- Tarjan's strongly connected components algorithm - Wikipedia (en)
計算量は、頂点数$|V|$・辺数$|E|$としていずれも$O(|V|+|E|)$と並んでいます。
ここでは、深さ優先探索1回で済み、わりときれいに書けそうなTarjanのアルゴリズムを使ってみます。あのドナルド・クヌースも美しい方法だと言っています(ってWikipediaに書いてある)。
Wikipediaに擬似コードまで載っているので楽ちんですね。
実装してみる
将来的にはgulpタスクのついでに実行できたらいいなーなどと思ったので、JavaScriptのコードにしたいです。
ですが、nullチェックを忘れたりしたらエディタが赤線を引いてくれるTypeScript(+VSCode)が最近とても快適![]() なので、TypeScriptで書いてコンパイルします。
なので、TypeScriptで書いてコンパイルします。
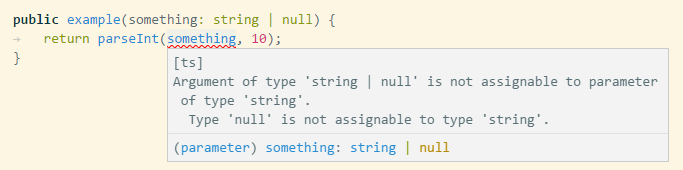
(nullかもしれないのでparseIntできないよとリアルタイムで教えてくれる例)
処理の流れは下のような感じです。
- ファイルを読み込んで、有向グラフをつくる
- できたグラフを強連結成分分解する
- 強連結成分ごとに図を書く
ファイルを読み込んで、有向グラフをつくる
各ファイルを頂点として、importの行を見つけたら辺をつなぎます。
まじめに構文解析するのは大変そうなので、正規表現で拾います。適当に/^import\s+(\w+)\s*(?:,.+)?from\s+['"](.+)['"];$/みたいな正規表現で拾えばだいたいはいけます。基本的にデフォルトインポートを使っていたので割と楽でした。
ファイルパスの解決らへんが面倒ですが、やるだけなのでここでは割愛します。
また、/class\s+(\w+)(?:<.+>)?\s+extends\s+(\w+)(?:<.+>)?/みたいな正規表現で継承を見つけて、辺に継承関係があるかどうかの情報をくっつけておきます。こちらも、クラスは基本的にデフォルトエクスポートひとつとしていたので割と楽でした。
グラフにはこんなクラスを使いました。コンパイルのついでに出力した定義ファイルの抜粋だけ載せます。
import GraphEdge from "./GraphEdge";
/** 頂点 */
export default class GraphNode {
/** ノード名 */
name: string;
/** どの強連結成分に属しているか */
SCCId: number;
/** 参照しているノードたち */
readonly adjacentNodes: GraphNode[];
/** 辺を追加 */
addLink(edge: GraphEdge): void;
}
import GraphNode from "./GraphNode";
/** 辺 */
export default class GraphEdge {
/** 元ノード */
readonly source: GraphNode;
/** 先ノード */
readonly destination: GraphNode;
/** 継承関係を示す辺ならtrue */
readonly isExtension: boolean;
}
TypeScriptは知らなくてもたぶん読めると思います。
すでにこれら2ファイルが循環参照していますが、継承関係にないのでエラーは起きません。![]()
できたグラフを強連結成分分解する
Tarjan法にはスタックが必要なのでそれっぽく実装します。ただし、普通のスタックの機能に加えて、$O(1)$で存在チェックをできないといけないので、内部にマップか何かで要素を覚えておく必要があります。
マップのキーのことを考えるのが面倒だったので、スタックには頂点の名前(ファイル名)を積むことにしました。
/** 指定された要素をO(1)で探索できるような、LIFOデータ構造。格納するデータは文字列のみの簡易実装。 */
export default class Stack {
/** 一番上に要素を追加。 */
push(element: string): void;
/** 一番上の要素。 */
top(): string;
/** 一番上の要素を削除。 */
pop(): void;
/** 指定された要素がスタック内に含まれていればtrue、そうでなければfalseを、O(1)で返す。 */
has(element: string): boolean;
/** スタックに積まれている要素数を返す。 */
size(): number;
}
強連結成分分解は肝なのでコードを丸ごと載せます。
せっかくQiitaに書くのでコメントも詳しく付けてみました。
間違っていたら教えてください。
import GraphNode from "./GraphNode";
import Stack from "./Stack";
export default class ConnectedComponentFinder {
private static _nodeMap: { [nodeName: string]: GraphNode };
/** 訪問順にノードにふられる番号 */
private static _numbers: { [nodeName: string]: number };
/** そのノードから有向路をたどって到達できるノードたちのうちで、そのノードに到達可能(=循環している)かつ最も番号が若いものの番号 */
private static _lowlinks: { [nodeName: string]: number };
/** ノードを訪問したらインクリメントして、各ノードの訪問順を記録できるようにする */
private static _index: number;
private static _stack: Stack;
/**
* @param nodeMap ノード名をキーにした、全ノードのマップ。実行のついでにSCCの番号もセットされる
*/
public static find(nodeMap: { [nodeName: string]: GraphNode }) {
this._nodeMap = nodeMap;
this._numbers = {};
this._lowlinks = {};
this._index = 0;
this._stack = new Stack();
Object.keys(nodeMap).forEach((nodeName) => {
// 未訪問のノードなら探索開始
if (this._numbers[nodeName] === undefined) {
this.visit(nodeMap[nodeName]);
}
});
}
private static visit(currentNode: GraphNode): void {
this._numbers[currentNode.name] = this._index;
this._lowlinks[currentNode.name] = this._index;
this._index++;
this._stack.push(currentNode.name);
currentNode.adjacentNodes.forEach((nextNode) => {
if (this._lowlinks[nextNode.name] === undefined) {
// 自分に到達可能な若いノードに、自分の子から到達できるのなら、自分からも到達できる(子が未訪問の場合)
this.visit(nextNode);
this._lowlinks[currentNode.name] = Math.min(this._lowlinks[currentNode.name], this._lowlinks[nextNode.name]);
} else if (this._stack.has(nextNode.name)) {
// 自分に到達可能な若いノードに、自分の子から到達できるのなら、自分からも到達できる(子が訪問済みの場合)
this._lowlinks[currentNode.name] = Math.min(this._lowlinks[currentNode.name], this._lowlinks[nextNode.name]);
}
});
// 自分と循環するような自分より若いノードがないのなら、自分がSCCの中でいちばん若い
if (this._lowlinks[currentNode.name] === this._numbers[currentNode.name]) {
/** SCC中で最も若いノードの番号をSCCの番号として扱う */
const SCCId: number = this._lowlinks[currentNode.name];
// 再帰が自分に帰ってきた時点で自分より後としてスタックに積まれているノードは、すべて自分と同じSCCに含まれる
// (自分より後に訪問していて自分に到達できないノードは、すでにpopもされているので)
while (true) {
const topNodeName = this._stack.top();
this._stack.pop();
// 面倒なのでここでセット(手抜き)
this._nodeMap[topNodeName].SCCId = SCCId;
if (topNodeName === currentNode.name) {
break;
}
}
}
}
}
強連結成分ごとに図を書く
上でfind()というメソッド名に反して、頂点に直接SCCのIDをつけるところまでやってしまったので、あとは各ノードをチェックしていくだけです。
図の出力には、最近なんとなく触っていたPlantUMLを使ってみます。
簡単なテキストからUML図が出力できるという、便利で優秀なやつです。
JavaScriptから使うには、node-plantumlがあるのでこれを使います。実行にはJavaとGraphVizが必要なので別途インストールしておきます。
$ npm install node-plantuml --save
さっきの頂点クラスに、PlantUML用文字列を返してもらうようにメソッドを足します。
自分と同じSCC内への参照のみ出力すればよいので、だいたい下のような感じです。
// class GraphNode
public createUMLString(): string {
return `class ${this.name}\n`
+ this.edges
.filter(edge => edge.destination.SCCId === this.SCCId)
.reduce((result, edge) => {
const link: string = edge.isExtension ? " -u[#blue]--> " : " --> ";
return result + this.name + link + edge.destination.name + "\n";
}, "");
}
SCCごとに、全頂点のUML文字列をひとつにまとめて、node-plantumlに渡すと、図ができあがります。
const plantuml = require("node-plantuml");
let UMLStrings: { [SCCId: number]: string } = {};
nodes.forEach((node) => {
if (UMLStrings[node.SCCId] === undefined) {
UMLStrings[node.SCCId] = "";
}
UMLStrings[node.SCCId] += node.createUMLString();
});
Object.keys(UMLStrings).forEach((SCCId) => {
plantuml.generate(UMLStrings[SCCId]).out
.pipe(fs.createWriteStream(`output/SCC_${SCCId}.png`));
});
これで貫通です!
動かしてみる
例としてこんな依存関係を用意します。
// A.js
import B from "./B";
import C from "./C";
import D from "./D";
export default class A { }
// B.js
import E from "./E";
export default class B { }
// C.js
import A from "./A";
import B from "./B";
import F from "./F";
export default class C { }
// D.js
import E from "./E";
import G from "./G";
export default class D { }
// E.js
export default class E { }
// F.js
import D from "./D";
export default class F extends D { }
// G.js
import A from "./A";
import E from "./E";
export default class G extends A { }
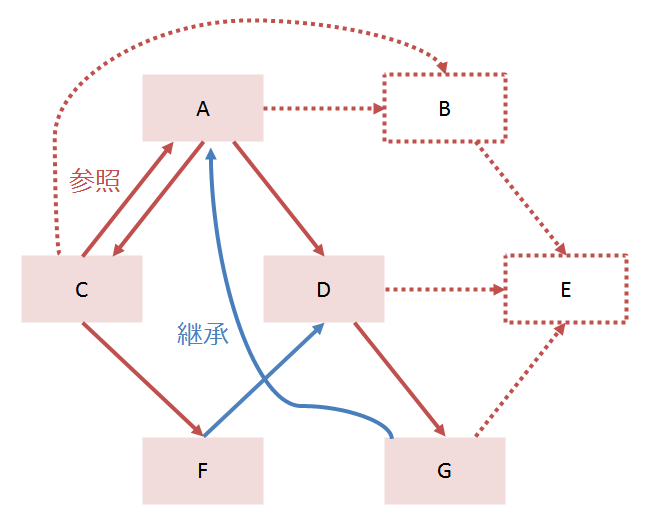
すでに人力の限界レベルです。
BとEは強連結成分に含まれないため、点線で示した頂点と辺はノイズであり、見たくありません。
さきほどのスクリプトに食わせます。
class A
A --> C
A --> D
class C
C --> A
C --> F
class D
D --> G
class F
F -u[#blue]--> D
class G
G -u[#blue]--> A
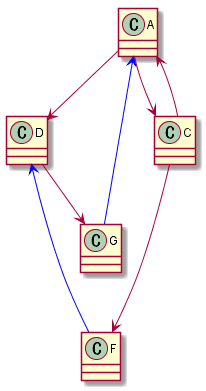
成功です。
本番
問題の300ファイルのコード群に対しても、上のスクリプトを実行してみます。
どうも図が巨大すぎるようで、デフォルト最大サイズの4096px以内で出力しきれないので、PlantUMLの実行時にオプションを渡します。
node-plantumlはオプションを受け取る口を備えていなかったので、ソースファイルをいじって、Java(PlantUMLは内部ではJavaを呼んでいます)の実行時に-Xmx1024mと-DPLANTUML_LIMIT_SIZE=16384のオプションを渡すようにします。
function execWithSpawn(argv, cwd, cb) {
cwd = cwd || process.cwd()
var opts = [
+ "-Xmx1024m", "-DPLANTUML_LIMIT_SIZE=16384",
'-Dplantuml.include.path=' + cwd,
'-Djava.awt.headless=true',
'-jar', PLANTUML_JAR,
].concat(argv)
return childProcess.spawn('java', opts)
}
出力した結果、こんな巨大な図ができあがりました(ファイル名は伏せてあります)。人力では不可能だったと思います。
この中からどんな2頂点を選んでも、必ず往復する道がつくれるはずです。時間のある人はパズルとして試してみてください(?)
50インチくらいのモニタがほしくなりますが、とりあえずこれでどんな循環が起きているのか一目瞭然になりました。
3つあるハブが印象的です。
やり残し
- gulpタスクとして実行したい
- 本当はPlantUMLにしなくても、内部で使われているGraphVizだけ使えばよさそう
- GraphVizを直接使った方が柔軟に出力できそう
- 時間節約のために、使ったことがあるPlantUMLを採用しただけ
- 上の図で左上にあるfile_14のように、「青い辺を含んだ単純閉路(頂点の重複がない閉路)」をつくれない頂点は、出力する必要がない
- 関節点を見つけてグラフを分割して、青い辺を含まない成分があったら取り除けばいい?
- 時間があったらやりたい