前提
Goのコードを見て思ったこと、勉強するべき場所について思ったことを記載します。
対象者となり得る人はGo初心者ですが、他の言語で少しはコードを書いてきた人になるかと思いますので予めご了承ください。
※ご指摘いつでも承ります。
初めてGoと対峙
Goのコードを読んだ際に一番最初に思ったことは率直に全くわからないだった。
基礎を一通り勉強したはずだったのだが、、、、
では何が分からなかったのか、本当に必要な勉強はこれだったのではないか。
そんな話をしたい
[第一関門]ポインタ周り
誰しもがつまづくであろう、ポインタ周り。
なぜ理解できないだろうと考えた際に * と & が見慣れないのに乱立すると頭が追いつかないという理由な気がする。
実際私もまだ完全な理解にはなっていない。
では改めてポインタとは何か? => メモリのアドレス情報のこと
参考:Goで学ぶポインタとアドレス
それがなんで必要になるの? => 引数やレシーバを関数内で書き換える必要がある場合、書き換える対象はポインタで渡す必要がある
参考:【Go】自分が理解に苦しんだ、ポインタとアドレスについてまとめる
- ポインタ変数
package main
import "fmt"
func main() {
var var1 int = 10
// 💡 & を用いることで変数のアドレスを取得できる
var var2 *int = &var1
fmt.Println(var1) //=> 10
fmt.Println(var2) //=> 0x10414020
fmt.Println(*var2) //=> 10
}
- ポインタ型 / ポインタ型変数
func main() {
// メモリー上のアドレスを記憶する変数の型のこと
// *int がポインタ型
// その*intで定義した変数をポインタ型変数という -> var2 がポインタ型変数
var var1 int = 10 //int型
var var2 *int = &var1 //int型へのポイント型
// 💡ポインタ型変数の前に * をつけることで変数の中身へのアクセスが可能
fmt.Println(*var2) //=> 10
}
- ポインタ型変数の必要性
package main
import "fmt"
type Hoge struct{ value int }
// ポインタ型ではないので、h.valueを書き換えられない
func (h Hoge) HogeA(v int) {
h.value = v + 5
}
// ポインタ型なので、h.valueを書き換えられる
func (h *Hoge) HogeB(v int) {
h.value = v + 5
}
func main() {
var h Hoge
h.HogeA(0)
// 💡ポインタ型ではないので0のまま出力される
fmt.Printf("HogeA(ポインタ型ではない)の出力結果:%v\n", h.value)
h.HogeB(0)
// 💡ポインタ型なので+5された値が出力される
fmt.Printf("HogeB(ポインタ型である)の出力結果:%v\n", h.value)
}
[第二関門]オブジェクト指向について
次に何が書いてあるのか分からないの代表にオブジェクト指向的な部分があったと思う。
Goにはオブジェクト指向言語におけるClassが存在しない。でも似た役割の書き方ができる。
弊社ではそんな書き方で実装されており、オブジェクト指向を全く通ってこなかった私はここが第二の関門であった。
なぜオブジェクト指向なのか? => 一度書いたプログラムを再利用しやすくなり、より少ないコードで処理が実現出来るようになる(etc)
参考:オブジェクト指向とは
あとは実際に構造体やメソッド、レシーバ、について書いて学ぶ
- 構造体と初期化関数
package main
import "fmt"
// Personの構造体
type Person struct {
firstName string
age int
}
// 関数で初期化
func newPerson(firstName string, age int) *Person{
person := new(Person)
person.firstName = firstName
person.age = age
return person
}
func main(){
var jen *Person = newPerson("Jennifer", 40)
fmt.Println(jen.firstName, jen.age) //=>Jennifer 40
}
- 構造体でメソッドを定義
type Person struct {
firstName string
age int
}
// メソッドの定義の仕方 (通常の関数と違うのはレシーバ引数だけ
func (<レシーバ引数>) <関数名>([引数]) [戻り値の型] {
[関数の本体]
}
// p という名前の Person 型のレシーバを持つことを意味する
func (p Person) intro(greetings string) string{
return greetings + " I am " + p.firstName
}
func main(){
bob := Person{"Bob", 30}
// 構造体Personで作成されたbobからメソッドを呼び出す
fmt.Println(bob.intro("Hello")) //=> Hello I am Bob
}
またここはまだ勉強中であるが、レシーバをポインタ型にするか否かは下記が参考になるようだ。
参考https://qiita.com/knsh14/items/8b73b31822c109d4c497#receiver-type
[第三関門]インターフェース
最後にインターフェースについて、オブジェクト指向を触れたことがない人にはまたきつい。。
そもそもインターフェースとは何か? => メソッドの型だけを記述した型のことで、インターフェースを通してオブジェクトの振る舞いを定義することができる
なぜインターフェースなのか? =>ざっくり言うと処理の共通化
参考:【Go】インターフェースの意義と使い方
- インターフェースの定義
// 定義の仕方
type 型名 interface {
メソッド名1(引数の型, ...) (返り値の型, ...)
.....
メソッド名N(引数の型, ...) (返り値の型, ...)
}
// 実際の値
type Person struct {} //Person構造体
type Person2 struct {} //Person2構造体
type People interface{
intro()
}
// 💡本来構造体ごとに関数を作成しないといけないがインターフェースがあることにより構造体を引数として使える
func IntroForPerson(arg People) {
arg.intro();
}
//Person構造体のメソッドintro()
func (p *Person) intro() {
fmt.Println("Hello World")
}
//Person2構造体のメソッドintro()
func (p *Person2) intro() {
fmt.Println("Hello World")
}
func main(){
bob := new(Person)
mike := new(Person2)
IntroForPerson(bob) //=> Hello World
IntroForPerson(mike) //=> Hello World
}
[第四関門]フレームワーク
ここはあったり前の話だが、フレームワークにはそれなりの独特の書き方がある。
Rubyの基礎を一通り勉強したからってRailsを初めて見たらあれ?と思うだろう。
そこをすっかり忘れていた。ここは特に記載することはないので私みたいにならないでねを込めて記載しておく。
[第五関門]クリーンアーキテクチャ(追記)
上記関門である程度コードが読めるようにはなる。
その後に待ち構えているのが書き方による疑問だ。
なぜこんな書き方をしているのか。それは大体がクリーンアーキテクチャに通ずる。
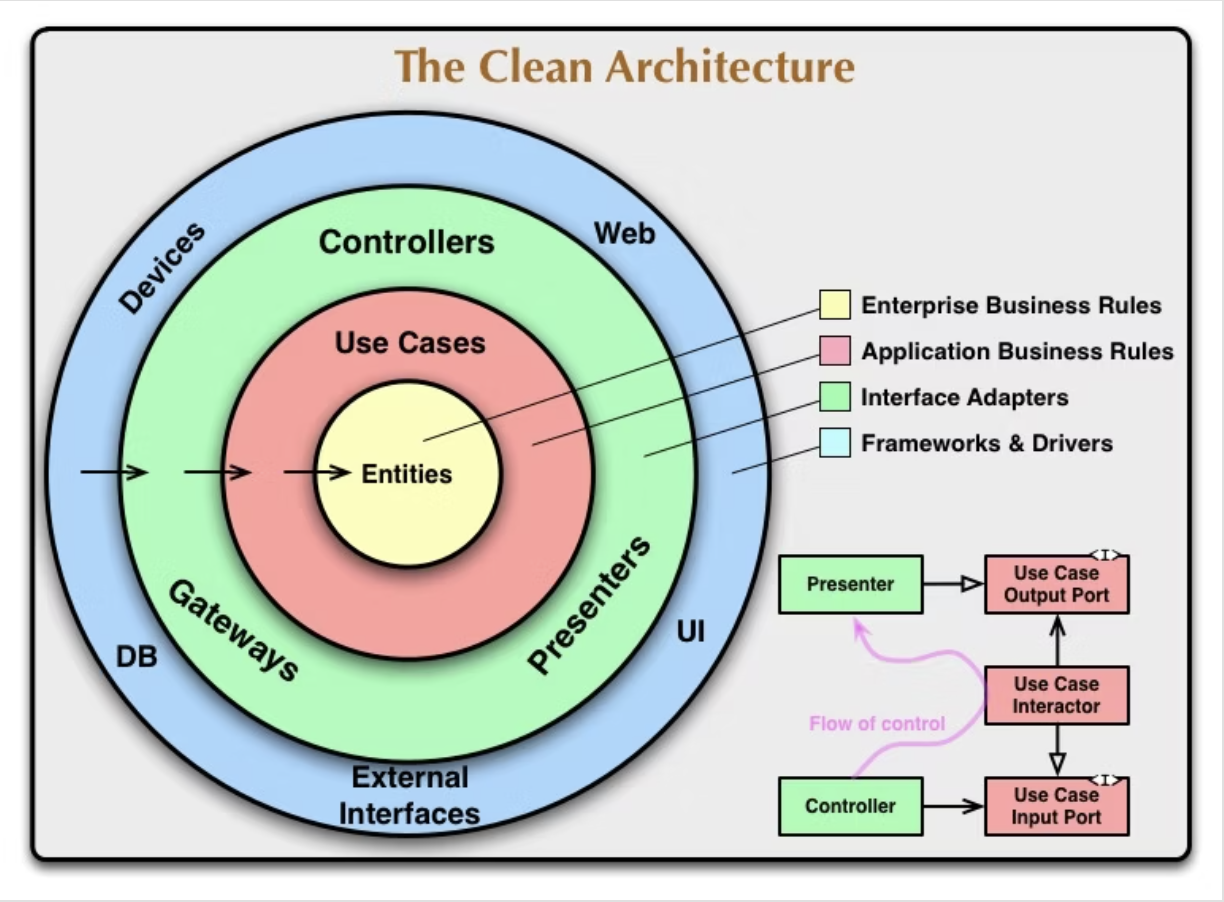
上記は有名なクリーンアーキテクチャの図である。
矢印が依存関係を示していて、依存関係が成立していると改修する際に依存関係にある箇所にも影響が出る。
昨今では、急な仕様変更や方向転換が生じる。そんな時にどこに影響が出るかを最小限に抑えられる。またテストを各項目ごとにできる。そんな特性を持つのがこのクリーンアーキテクチャだ。
このクリーンアーキテクチャは書き始めると記事一本分になるので詳細は割愛する。(別の機会に書こうかな)
ここの理解が進むとある程度なんでこんな書き方をしているのか、フォルダ構成がなぜこうなっているか。が分かる。
DI(Dependency Injection)も必須項目になるだろう。
まとめ
上記全ての関門を越えられると全く分からないの状態は抜けられると思う。
あとはわからない文言やコードを更に深掘りして詰めていく。なぜをそのままにしない。(自戒)
引き続き勉強頑張ります。また関門が出てきたら随時更新していきます。
参考記事
どれも参考になりすぎましてほぼパクリの記事になってしまったことをお詫びします。。。
- オブジェクト指向について
- Goの基礎周り
- メソッドとレシーバについて
- ポインタの説明
- ポインタの必要性
- レシーバをポインタ型にするか否か
- インターフェース